 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraversal Verification for Speculative Tree Decoding
May 18, 2025Speculative decoding is a promising approach for accelerating large language models. The primary idea is to use a lightweight draft model to speculate the output of the target model for multiple subsequent timesteps, and then verify them in parallel to determine whether the drafted tokens should be accepted or rejected. To enhance acceptance rates, existing frameworks typically construct token trees containing multiple candidates in each timestep. However, their reliance on token-level verification mechanisms introduces two critical limitations: First, the probability distribution of a sequence differs from that of individual tokens, leading to suboptimal acceptance length. Second, current verification schemes begin from the root node and proceed layer by layer in a top-down manner. Once a parent node is rejected, all its child nodes should be discarded, resulting in inefficient utilization of speculative candidates. This paper introduces Traversal Verification, a novel speculative decoding algorithm that fundamentally rethinks the verification paradigm through leaf-to-root traversal. Our approach considers the acceptance of the entire token sequence from the current node to the root, and preserves potentially valid subsequences that would be prematurely discarded by existing methods. We theoretically prove that the probability distribution obtained through Traversal Verification is identical to that of the target model, guaranteeing lossless inference while achieving substantial acceleration gains. Experimental results across different large language models and multiple tasks show that our method consistently improves acceptance length and throughput over existing methods
CORAL: Learning Consistent Representations across Multi-step Training with Lighter Speculative Drafter
Feb 24, 2025Speculative decoding is a powerful technique that accelerates Large Language Model (LLM) inference by leveraging a lightweight speculative draft model. However, existing designs suffers in performance due to misalignment between training and inference. Recent methods have tried to solve this issue by adopting a multi-step training strategy, but the complex inputs of different training steps make it harder for the draft model to converge. To address this, we propose CORAL, a novel framework that improves both accuracy and efficiency in speculative drafting. CORAL introduces Cross-Step Representation Alignment, a method that enhances consistency across multiple training steps, significantly improving speculative drafting performance. Additionally, we identify the LM head as a major bottleneck in the inference speed of the draft model. We introduce a weight-grouping mechanism that selectively activates a subset of LM head parameters during inference, substantially reducing the latency of the draft model. We evaluate CORAL on three LLM families and three benchmark datasets, achieving speedup ratios of 2.50x-4.07x, outperforming state-of-the-art methods such as EAGLE-2 and HASS. Our results demonstrate that CORAL effectively mitigates training-inference misalignment and delivers significant speedup for modern LLMs with large vocabularies.
Activating the Discriminability of Novel Classes for Few-shot Segmentation
Dec 02, 2022Despite the remarkable success of existing methods for few-shot segmentation, there remain two crucial challenges. First, the feature learning for novel classes is suppressed during the training on base classes in that the novel classes are always treated as background. Thus, the semantics of novel classes are not well learned. Second, most of existing methods fail to consider the underlying semantic gap between the support and the query resulting from the representative bias by the scarce support samples. To circumvent these two challenges, we propose to activate the discriminability of novel classes explicitly in both the feature encoding stage and the prediction stage for segmentation. In the feature encoding stage, we design the Semantic-Preserving Feature Learning module (SPFL) to first exploit and then retain the latent semantics contained in the whole input image, especially those in the background that belong to novel classes. In the prediction stage for segmentation, we learn an Self-Refined Online Foreground-Background classifier (SROFB), which is able to refine itself using the high-confidence pixels of query image to facilitate its adaptation to the query image and bridge the support-query semantic gap. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrates the advantages of these two novel designs both quantitatively and qualitatively.
Few-Shot Object Detection by Knowledge Distillation Using Bag-of-Visual-Words Representations
Jul 25, 2022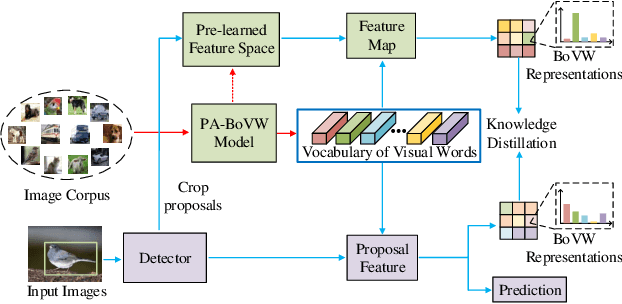
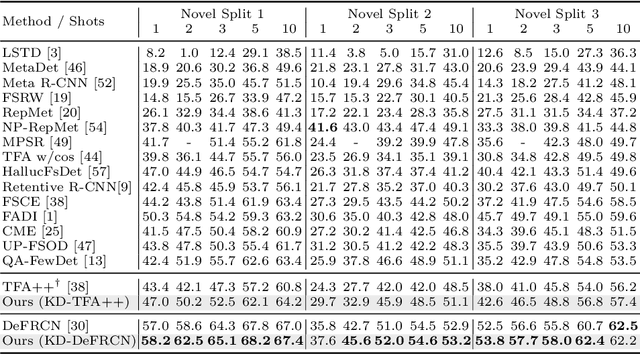
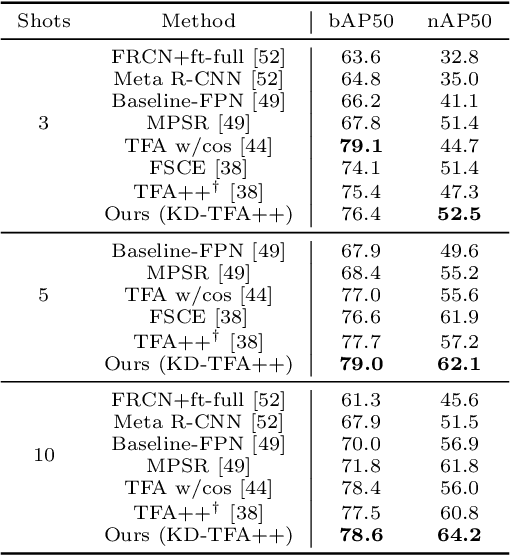

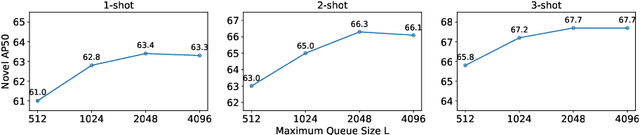
While fine-tuning based methods for few-shot object detection have achieved remarkable progress, a crucial challenge that has not been addressed well is the potential class-specific overfitting on base classes and sample-specific overfitting on novel classes. In this work we design a novel knowledge distillation framework to guide the learning of the object detector and thereby restrain the overfitting in both the pre-training stage on base classes and fine-tuning stage on novel classes. To be specific, we first present a novel Position-Aware Bag-of-Visual-Words model for learning a representative bag of visual words (BoVW) from a limited size of image set, which is used to encode general images based on the similarities between the learned visual words and an image. Then we perform knowledge distillation based on the fact that an image should have consistent BoVW representations in two different feature spaces. To this end, we pre-learn a feature space independently from the object detection, and encode images using BoVW in this space. The obtained BoVW representation for an image can be considered as distilled knowledge to guide the learning of object detector: the extracted features by the object detector for the same image are expected to derive the consistent BoVW representations with the distilled knowledge. Extensive experiments validate the effectiveness of our method and demonstrate the superiority over other state-of-the-art methods.
Multi-Faceted Distillation of Base-Novel Commonality for Few-shot Object Detection
Jul 22, 2022


Most of existing methods for few-shot object detection follow the fine-tuning paradigm, which potentially assumes that the class-agnostic generalizable knowledge can be learned and transferred implicitly from base classes with abundant samples to novel classes with limited samples via such a two-stage training strategy. However, it is not necessarily true since the object detector can hardly distinguish between class-agnostic knowledge and class-specific knowledge automatically without explicit modeling. In this work we propose to learn three types of class-agnostic commonalities between base and novel classes explicitly: recognition-related semantic commonalities, localization-related semantic commonalities and distribution commonalities. We design a unified distillation framework based on a memory bank, which is able to perform distillation of all three types of commonalities jointly and efficiently. Extensive experiments demonstrate that our method can be readily integrated into most of existing fine-tuning based methods and consistently improve the performance by a large margin.