 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraversal Verification for Speculative Tree Decoding
May 18, 2025Speculative decoding is a promising approach for accelerating large language models. The primary idea is to use a lightweight draft model to speculate the output of the target model for multiple subsequent timesteps, and then verify them in parallel to determine whether the drafted tokens should be accepted or rejected. To enhance acceptance rates, existing frameworks typically construct token trees containing multiple candidates in each timestep. However, their reliance on token-level verification mechanisms introduces two critical limitations: First, the probability distribution of a sequence differs from that of individual tokens, leading to suboptimal acceptance length. Second, current verification schemes begin from the root node and proceed layer by layer in a top-down manner. Once a parent node is rejected, all its child nodes should be discarded, resulting in inefficient utilization of speculative candidates. This paper introduces Traversal Verification, a novel speculative decoding algorithm that fundamentally rethinks the verification paradigm through leaf-to-root traversal. Our approach considers the acceptance of the entire token sequence from the current node to the root, and preserves potentially valid subsequences that would be prematurely discarded by existing methods. We theoretically prove that the probability distribution obtained through Traversal Verification is identical to that of the target model, guaranteeing lossless inference while achieving substantial acceleration gains. Experimental results across different large language models and multiple tasks show that our method consistently improves acceptance length and throughput over existing methods
A Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025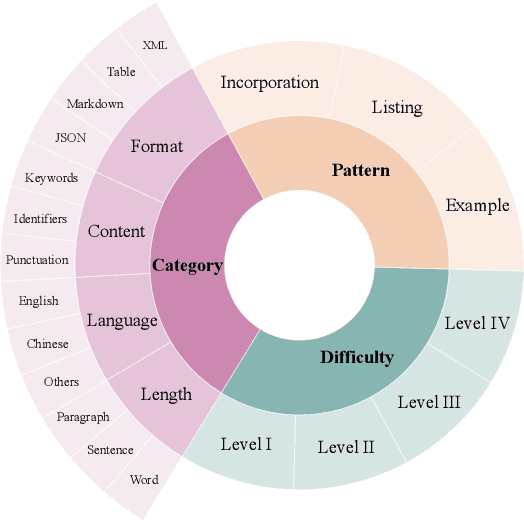

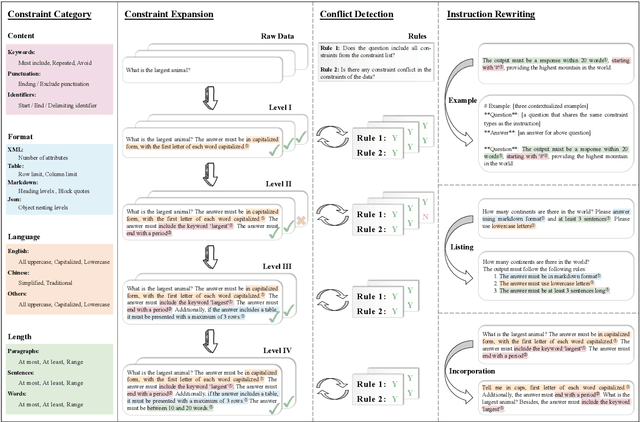
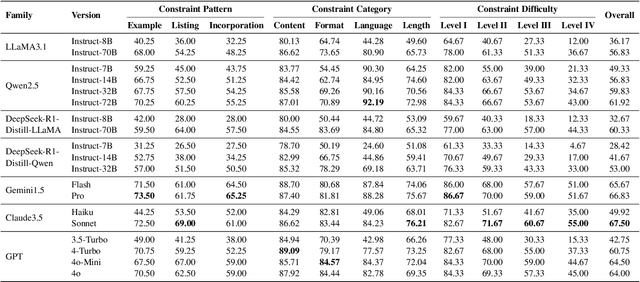
Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
May 08, 2025Enabling intelligent agents to comprehend and interact with 3D environments through natural language is crucial for advancing robotics and human-computer interaction. A fundamental task in this field is ego-centric 3D visual grounding, where agents locate target objects in real-world 3D spaces based on verbal descriptions. However, this task faces two significant challenges: (1) loss of fine-grained visual semantics due to sparse fusion of point clouds with ego-centric multi-view images, (2) limited textual semantic context due to arbitrary language descriptions. We propose DenseGrounding, a novel approach designed to address these issues by enhancing both visual and textual semantics. For visual features, we introduce the Hierarchical Scene Semantic Enhancer, which retains dense semantics by capturing fine-grained global scene features and facilitating cross-modal alignment. For text descriptions, we propose a Language Semantic Enhancer that leverages large language models to provide rich context and diverse language descriptions with additional context during model training. Extensive experiments show that DenseGrounding significantly outperforms existing methods in overall accuracy, with improvements of 5.81% and 7.56% when trained on the comprehensive full dataset and smaller mini subset, respectively, further advancing the SOTA in egocentric 3D visual grounding. Our method also achieves 1st place and receives the Innovation Award in the CVPR 2024 Autonomous Grand Challenge Multi-view 3D Visual Grounding Track, validating its effectiveness and robustness.
CORAL: Learning Consistent Representations across Multi-step Training with Lighter Speculative Drafter
Feb 24, 2025Speculative decoding is a powerful technique that accelerates Large Language Model (LLM) inference by leveraging a lightweight speculative draft model. However, existing designs suffers in performance due to misalignment between training and inference. Recent methods have tried to solve this issue by adopting a multi-step training strategy, but the complex inputs of different training steps make it harder for the draft model to converge. To address this, we propose CORAL, a novel framework that improves both accuracy and efficiency in speculative drafting. CORAL introduces Cross-Step Representation Alignment, a method that enhances consistency across multiple training steps, significantly improving speculative drafting performance. Additionally, we identify the LM head as a major bottleneck in the inference speed of the draft model. We introduce a weight-grouping mechanism that selectively activates a subset of LM head parameters during inference, substantially reducing the latency of the draft model. We evaluate CORAL on three LLM families and three benchmark datasets, achieving speedup ratios of 2.50x-4.07x, outperforming state-of-the-art methods such as EAGLE-2 and HASS. Our results demonstrate that CORAL effectively mitigates training-inference misalignment and delivers significant speedup for modern LLMs with large vocabularies.
TL-Training: A Task-Feature-Based Framework for Training Large Language Models in Tool Use
Dec 20, 2024



Large language models (LLMs) achieve remarkable advancements by leveraging tools to interact with external environments, a critical step toward generalized AI. However, the standard supervised fine-tuning (SFT) approach, which relies on large-scale datasets, often overlooks task-specific characteristics in tool use, leading to performance bottlenecks. To address this issue, we analyze three existing LLMs and uncover key insights: training data can inadvertently impede tool-use behavior, token importance is distributed unevenly, and errors in tool calls fall into a small set of distinct categories. Building on these findings, we propose TL-Training, a task-feature-based framework that mitigates the effects of suboptimal training data, dynamically adjusts token weights to prioritize key tokens during SFT, and incorporates a robust reward mechanism tailored to error categories, optimized through proximal policy optimization. We validate TL-Training by training CodeLLaMA-2-7B and evaluating it on four diverse open-source test sets. Our results demonstrate that the LLM trained by our method matches or surpasses both open- and closed-source LLMs in tool-use performance using only 1,217 training data points. Additionally, our method enhances robustness in noisy environments and improves general task performance, offering a scalable and efficient paradigm for tool-use training in LLMs. The code and data are available at https://github.com/Junjie-Ye/TL-Training.
Empirical Insights on Fine-Tuning Large Language Models for Question-Answering
Sep 24, 2024



Large language models (LLMs) encode extensive world knowledge through pre-training on massive datasets, which can then be fine-tuned for the question-answering (QA) task. However, effective strategies for fine-tuning LLMs for the QA task remain largely unexplored. To address this gap, we categorize supervised fine-tuning (SFT) data based on the extent of knowledge memorized by the pretrained LLMs and conduct a series of empirical analyses. Our experiments, involving four LLMs from three different model families, focus on three key factors: the amount of data required for SFT, the impact of different SFT datasets on model performance, and how data requirements vary across LLMs. The results show that as few as 60 data points during the SFT stage can activate the knowledge encoded during pre-training, enabling LLMs to perform the QA task. Additionally, SFT with data of varying memory levels has a significant impact on LLM performance, with the optimal dataset differing based on the specific model being fine-tuned. Future research will delve deeper into the mechanisms underlying these phenomena.
DomainVerse: A Benchmark Towards Real-World Distribution Shifts For Tuning-Free Adaptive Domain Generalization
Mar 05, 2024Traditional cross-domain tasks, including domain adaptation and domain generalization, rely heavily on training model by source domain data. With the recent advance of vision-language models (VLMs), viewed as natural source models, the cross-domain task changes to directly adapt the pre-trained source model to arbitrary target domains equipped with prior domain knowledge, and we name this task Adaptive Domain Generalization (ADG). However, current cross-domain datasets have many limitations, such as unrealistic domains, unclear domain definitions, and the inability to fine-grained domain decomposition, which drives us to establish a novel dataset DomainVerse for ADG. Benefiting from the introduced hierarchical definition of domain shifts, DomainVerse consists of about 0.5 million images from 390 fine-grained realistic domains. With the help of the constructed DomainVerse and VLMs, we propose two methods called Domain CLIP and Domain++ CLIP for tuning-free adaptive domain generalization. Extensive and comprehensive experiments demonstrate the significance of the dataset and the effectiveness of the proposed methods.
Hybrid Representation Learning via Epistemic Graph
May 31, 2023In recent years, deep models have achieved remarkable success in many vision tasks. Unfortunately, their performance largely depends on intensive training samples. In contrast, human beings typically perform hybrid learning, e.g., spontaneously integrating structured knowledge for cross-domain recognition or on a much smaller amount of data samples for few-shot learning. Thus it is very attractive to extend hybrid learning for the computer vision tasks by seamlessly integrating structured knowledge with data samples to achieve more effective representation learning. However, such a hybrid learning approach remains a great challenge due to the huge gap between the structured knowledge and the deep features (learned from data samples) on both dimensions and knowledge granularity. In this paper, a novel Epistemic Graph Layer (EGLayer) is developed to enable hybrid learning, such that the information can be exchanged more effectively between the deep features and a structured knowledge graph. Our EGLayer is composed of three major parts: (a) a local graph module to establish a local prototypical graph through the learned deep features, i.e., aligning the deep features with the structured knowledge graph at the same granularity; (b) a query aggregation model to aggregate useful information from the local graphs, and using such representations to compute their similarity with global node embeddings for final prediction; and (c) a novel correlation loss function to constrain the linear consistency between the local and global adjacency matrices.
Learning to Learn Domain-invariant Parameters for Domain Generalization
Nov 04, 2022
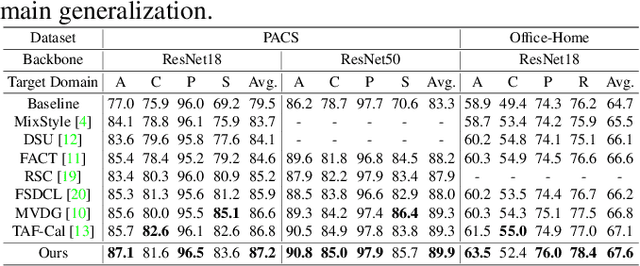


Due to domain shift, deep neural networks (DNNs) usually fail to generalize well on unknown test data in practice. Domain generalization (DG) aims to overcome this issue by capturing domain-invariant representations from source domains. Motivated by the insight that only partial parameters of DNNs are optimized to extract domain-invariant representations, we expect a general model that is capable of well perceiving and emphatically updating such domain-invariant parameters. In this paper, we propose two modules of Domain Decoupling and Combination (DDC) and Domain-invariance-guided Backpropagation (DIGB), which can encourage such general model to focus on the parameters that have a unified optimization direction between pairs of contrastive samples. Our extensive experiments on two benchmarks have demonstrated that our proposed method has achieved state-of-the-art performance with strong generalization capability.
SAP-DETR: Bridging the Gap Between Salient Points and Queries-Based Transformer Detector for Fast Model Convergency
Nov 03, 2022Recently, the dominant DETR-based approaches apply central-concept spatial prior to accelerate Transformer detector convergency. These methods gradually refine the reference points to the center of target objects and imbue object queries with the updated central reference information for spatially conditional attention. However, centralizing reference points may severely deteriorate queries' saliency and confuse detectors due to the indiscriminative spatial prior. To bridge the gap between the reference points of salient queries and Transformer detectors, we propose SAlient Point-based DETR (SAP-DETR) by treating object detection as a transformation from salient points to instance objects. In SAP-DETR, we explicitly initialize a query-specific reference point for each object query, gradually aggregate them into an instance object, and then predict the distance from each side of the bounding box to these points. By rapidly attending to query-specific reference region and other conditional extreme regions from the image features, SAP-DETR can effectively bridge the gap between the salient point and the query-based Transformer detector with a significant convergency speed. Our extensive experiments have demonstrated that SAP-DETR achieves 1.4 times convergency speed with competitive performance. Under the standard training scheme, SAP-DETR stably promotes the SOTA approaches by 1.0 AP. Based on ResNet-DC-101, SAP-DETR achieves 46.9 AP.