 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-MARS: Empowering Multimodal Agentic Reasoning and Search via Reinforcement Learning
Dec 30, 2025While Vision-Language Models (VLMs) can solve complex tasks through agentic reasoning, their capabilities remain largely constrained to text-oriented chain-of-thought or isolated tool invocation. They fail to exhibit the human-like proficiency required to seamlessly interleave dynamic tool manipulation with continuous reasoning, particularly in knowledge-intensive and visually complex scenarios that demand coordinated external tools such as search and image cropping. In this work, we introduce SenseNova-MARS, a novel Multimodal Agentic Reasoning and Search framework that empowers VLMs with interleaved visual reasoning and tool-use capabilities via reinforcement learning (RL). Specifically, SenseNova-MARS dynamically integrates the image search, text search, and image crop tools to tackle fine-grained and knowledge-intensive visual understanding challenges. In the RL stage, we propose the Batch-Normalized Group Sequence Policy Optimization (BN-GSPO) algorithm to improve the training stability and advance the model's ability to invoke tools and reason effectively. To comprehensively evaluate the agentic VLMs on complex visual tasks, we introduce the HR-MMSearch benchmark, the first search-oriented benchmark composed of high-resolution images with knowledge-intensive and search-driven questions. Experiments demonstrate that SenseNova-MARS achieves state-of-the-art performance on open-source search and fine-grained image understanding benchmarks. Specifically, on search-oriented benchmarks, SenseNova-MARS-8B scores 67.84 on MMSearch and 41.64 on HR-MMSearch, surpassing proprietary models such as Gemini-3-Flash and GPT-5. SenseNova-MARS represents a promising step toward agentic VLMs by providing effective and robust tool-use capabilities. To facilitate further research in this field, we will release all code, models, and datasets.
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
May 08, 2025Enabling intelligent agents to comprehend and interact with 3D environments through natural language is crucial for advancing robotics and human-computer interaction. A fundamental task in this field is ego-centric 3D visual grounding, where agents locate target objects in real-world 3D spaces based on verbal descriptions. However, this task faces two significant challenges: (1) loss of fine-grained visual semantics due to sparse fusion of point clouds with ego-centric multi-view images, (2) limited textual semantic context due to arbitrary language descriptions. We propose DenseGrounding, a novel approach designed to address these issues by enhancing both visual and textual semantics. For visual features, we introduce the Hierarchical Scene Semantic Enhancer, which retains dense semantics by capturing fine-grained global scene features and facilitating cross-modal alignment. For text descriptions, we propose a Language Semantic Enhancer that leverages large language models to provide rich context and diverse language descriptions with additional context during model training. Extensive experiments show that DenseGrounding significantly outperforms existing methods in overall accuracy, with improvements of 5.81% and 7.56% when trained on the comprehensive full dataset and smaller mini subset, respectively, further advancing the SOTA in egocentric 3D visual grounding. Our method also achieves 1st place and receives the Innovation Award in the CVPR 2024 Autonomous Grand Challenge Multi-view 3D Visual Grounding Track, validating its effectiveness and robustness.
Exploring contextual modeling with linear complexity for point cloud segmentation
Oct 28, 2024



Point cloud segmentation is an important topic in 3D understanding that has traditionally has been tackled using either the CNN or Transformer. Recently, Mamba has emerged as a promising alternative, offering efficient long-range contextual modeling capabilities without the quadratic complexity associated with Transformer's attention mechanisms. However, despite Mamba's potential, early efforts have all failed to achieve better performance than the best CNN-based and Transformer-based methods. In this work, we address this challenge by identifying the key components of an effective and efficient point cloud segmentation architecture. Specifically, we show that: 1) Spatial locality and robust contextual understanding are critical for strong performance, and 2) Mamba features linear computational complexity, offering superior data and inference efficiency compared to Transformers, while still being capable of delivering strong contextual understanding. Additionally, we further enhance the standard Mamba specifically for point cloud segmentation by identifying its two key shortcomings. First, the enforced causality in the original Mamba is unsuitable for processing point clouds that have no such dependencies. Second, its unidirectional scanning strategy imposes a directional bias, hampering its ability to capture the full context of unordered point clouds in a single pass. To address these issues, we carefully remove the causal convolutions and introduce a novel Strided Bidirectional SSM to enhance the model's capability to capture spatial relationships. Our efforts culminate in the development of a novel architecture named MEEPO, which effectively integrates the strengths of CNN and Mamba. MEEPO surpasses the previous state-of-the-art method, PTv3, by up to +0.8 mIoU on multiple key benchmark datasets, while being 42.1% faster and 5.53x more memory efficient.
Semantic Refocused Tuning for Open-Vocabulary Panoptic Segmentation
Sep 24, 2024



Open-vocabulary panoptic segmentation is an emerging task aiming to accurately segment the image into semantically meaningful masks based on a set of texts. Despite existing efforts, it remains challenging to develop a high-performing method that generalizes effectively across new domains and requires minimal training resources. Our in-depth analysis of current methods reveals a crucial insight: mask classification is the main performance bottleneck for open-vocab. panoptic segmentation. Based on this, we propose Semantic Refocused Tuning (SMART), a novel framework that greatly enhances open-vocab. panoptic segmentation by improving mask classification through two key innovations. First, SMART adopts a multimodal Semantic-guided Mask Attention mechanism that injects task-awareness into the regional information extraction process. This enables the model to capture task-specific and contextually relevant information for more effective mask classification. Second, it incorporates Query Projection Tuning, which strategically fine-tunes the query projection layers within the Vision Language Model (VLM) used for mask classification. This adjustment allows the model to adapt the image focus of mask tokens to new distributions with minimal training resources, while preserving the VLM's pre-trained knowledge. Extensive ablation studies confirm the superiority of our approach. Notably, SMART sets new state-of-the-art results, demonstrating improvements of up to +1.3 PQ and +5.4 mIoU across representative benchmarks, while reducing training costs by nearly 10x compared to the previous best method. Our code and data will be released.
Mask Grounding for Referring Image Segmentation
Dec 19, 2023
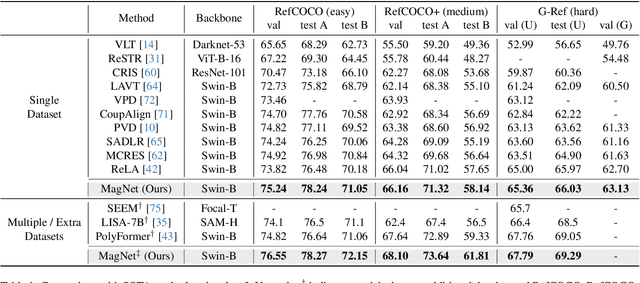
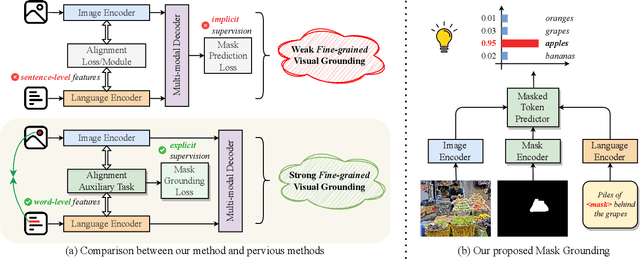
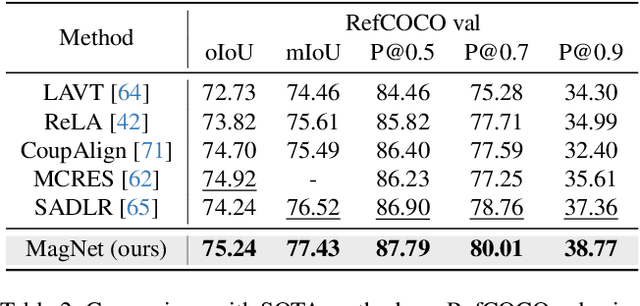
Referring Image Segmentation (RIS) is a challenging task that requires an algorithm to segment objects referred by free-form language expressions. Despite significant progress in recent years, most state-of-the-art (SOTA) methods still suffer from considerable language-image modality gap at the pixel and word level. These methods generally 1) rely on sentence-level language features for language-image alignment and 2) lack explicit training supervision for fine-grained visual grounding. Consequently, they exhibit weak object-level correspondence between visual and language features. Without well-grounded features, prior methods struggle to understand complex expressions that require strong reasoning over relationships among multiple objects, especially when dealing with rarely used or ambiguous clauses. To tackle this challenge, we introduce a novel Mask Grounding auxiliary task that significantly improves visual grounding within language features, by explicitly teaching the model to learn fine-grained correspondence between masked textual tokens and their matching visual objects. Mask Grounding can be directly used on prior RIS methods and consistently bring improvements. Furthermore, to holistically address the modality gap, we also design a cross-modal alignment loss and an accompanying alignment module. These additions work synergistically with Mask Grounding. With all these techniques, our comprehensive approach culminates in MagNet Mask-grounded Network), an architecture that significantly outperforms prior arts on three key benchmarks (RefCOCO, RefCOCO+ and G-Ref), demonstrating our method's effectiveness in addressing current limitations of RIS algorithms. Our code and pre-trained weights will be released.