 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring contextual modeling with linear complexity for point cloud segmentation
Oct 28, 2024



Point cloud segmentation is an important topic in 3D understanding that has traditionally has been tackled using either the CNN or Transformer. Recently, Mamba has emerged as a promising alternative, offering efficient long-range contextual modeling capabilities without the quadratic complexity associated with Transformer's attention mechanisms. However, despite Mamba's potential, early efforts have all failed to achieve better performance than the best CNN-based and Transformer-based methods. In this work, we address this challenge by identifying the key components of an effective and efficient point cloud segmentation architecture. Specifically, we show that: 1) Spatial locality and robust contextual understanding are critical for strong performance, and 2) Mamba features linear computational complexity, offering superior data and inference efficiency compared to Transformers, while still being capable of delivering strong contextual understanding. Additionally, we further enhance the standard Mamba specifically for point cloud segmentation by identifying its two key shortcomings. First, the enforced causality in the original Mamba is unsuitable for processing point clouds that have no such dependencies. Second, its unidirectional scanning strategy imposes a directional bias, hampering its ability to capture the full context of unordered point clouds in a single pass. To address these issues, we carefully remove the causal convolutions and introduce a novel Strided Bidirectional SSM to enhance the model's capability to capture spatial relationships. Our efforts culminate in the development of a novel architecture named MEEPO, which effectively integrates the strengths of CNN and Mamba. MEEPO surpasses the previous state-of-the-art method, PTv3, by up to +0.8 mIoU on multiple key benchmark datasets, while being 42.1% faster and 5.53x more memory efficient.
Memorizing Comprehensively to Learn Adaptively: Unsupervised Cross-Domain Person Re-ID with Multi-level Memory
Jan 13, 2020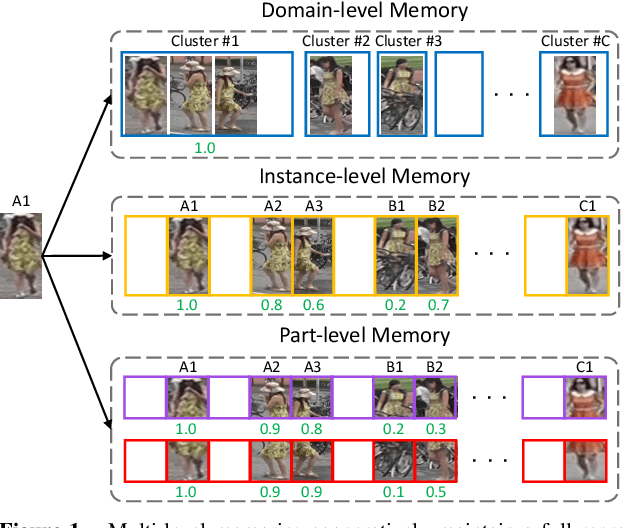
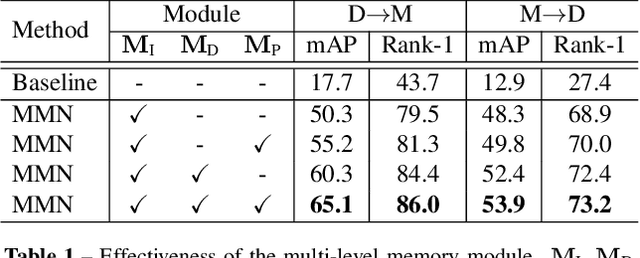
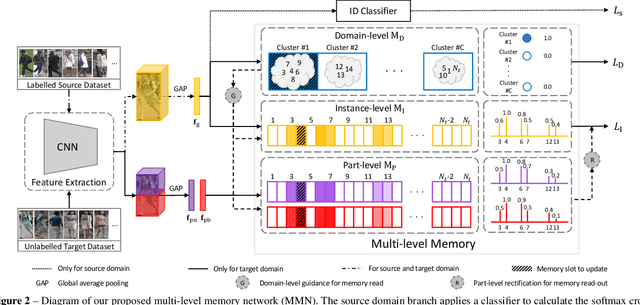
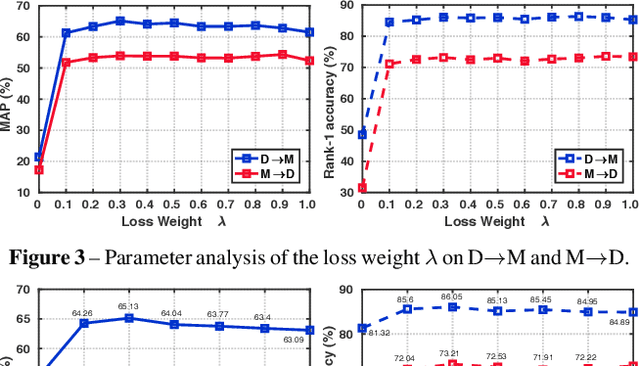
Unsupervised cross-domain person re-identification (Re-ID) aims to adapt the information from the labelled source domain to an unlabelled target domain. Due to the lack of supervision in the target domain, it is crucial to identify the underlying similarity-and-dissimilarity relationships among the unlabelled samples in the target domain. In order to use the whole data relationships efficiently in mini-batch training, we apply a series of memory modules to maintain an up-to-date representation of the entire dataset. Unlike the simple exemplar memory in previous works, we propose a novel multi-level memory network (MMN) to discover multi-level complementary information in the target domain, relying on three memory modules, i.e., part-level memory, instance-level memory, and domain-level memory. The proposed memory modules store multi-level representations of the target domain, which capture both the fine-grained differences between images and the global structure for the holistic target domain. The three memory modules complement each other and systematically integrate multi-level supervision from bottom to up. Experiments on three datasets demonstrate that the multi-level memory modules cooperatively boost the unsupervised cross-domain Re-ID task, and the proposed MMN achieves competitive results.
Part-Guided Attention Learning for Vehicle Re-Identification
Sep 19, 2019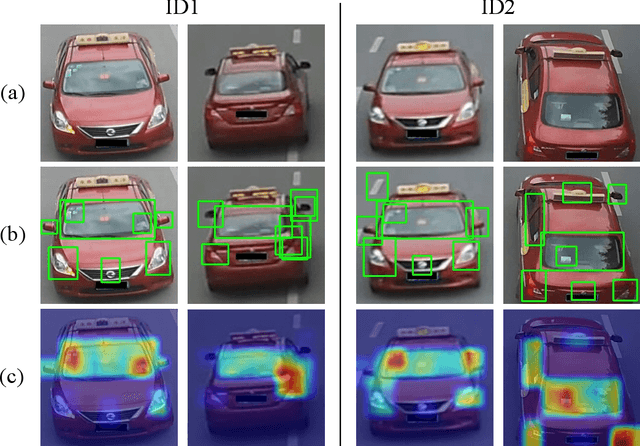
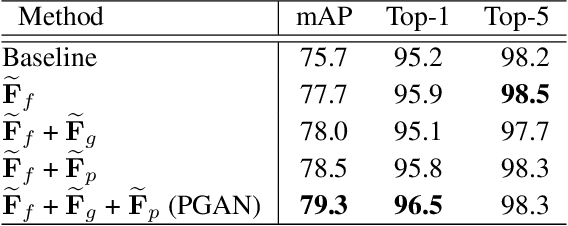
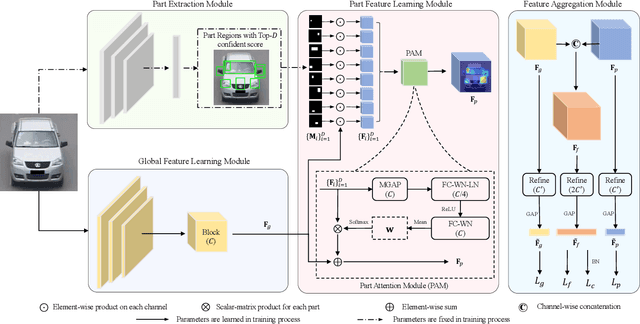
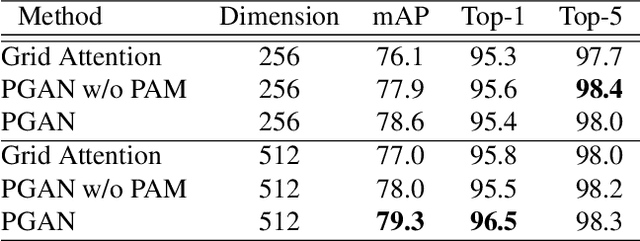
Vehicle re-identification (Re-ID) often requires one to recognize the fine-grained visual differences between vehicles. Besides the holistic appearance of vehicles which is easily affected by the viewpoint variation and distortion, vehicle parts also provide crucial cues to differentiate near-identical vehicles. Motivated by these observations, we introduce a Part-Guided Attention Network (PGAN) to pinpoint the prominent part regions and effectively combine the global and part information for discriminative feature learning. PGAN first detects the locations of different part components and salient regions regardless of the vehicle identity, which serve as the bottom-up attention to narrow down the possible searching regions. To estimate the importance of detected parts, we propose a Part Attention Module (PAM) to adaptively locate the most discriminative regions with high-attention weights and suppress the distraction of irrelevant parts with relatively low weights. The PAM is guided by the Re-ID loss and therefore provides top-down attention that enables attention to be calculated at the level of car parts and other salient regions. Finally, we aggregate the global appearance and part features to improve the feature performance further. The PGAN combines part-guided bottom-up and top-down attention, global and part visual features in an end-to-end framework. Extensive experiments demonstrate that the proposed method achieves new state-of-the-art vehicle Re-ID performance on four large-scale benchmark datasets.
Satellite Pose Estimation with Deep Landmark Regression and Nonlinear Pose Refinement
Aug 30, 2019
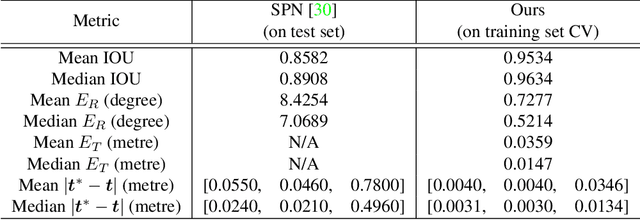
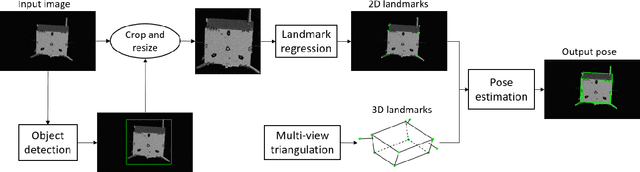
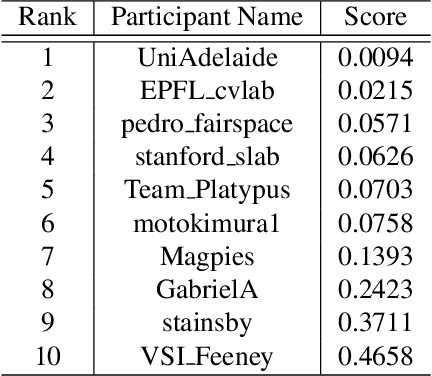
We propose an approach to estimate the 6DOF pose of a satellite, relative to a canonical pose, from a single image. Such a problem is crucial in many space proximity operations, such as docking, debris removal, and inter-spacecraft communications. Our approach combines machine learning and geometric optimisation, by predicting the coordinates of a set of landmarks in the input image, associating the landmarks to their corresponding 3D points on an a priori reconstructed 3D model, then solving for the object pose using non-linear optimisation. Our approach is not only novel for this specific pose estimation task, which helps to further open up a relatively new domain for machine learning and computer vision, but it also demonstrates superior accuracy and won the first place in the recent Kelvins Pose Estimation Challenge organised by the European Space Agency (ESA).
Self-training with progressive augmentation for unsupervised cross-domain person re-identification
Jul 31, 2019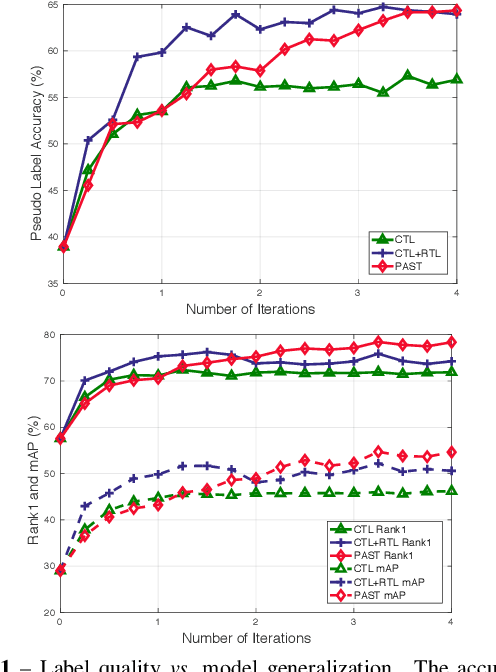
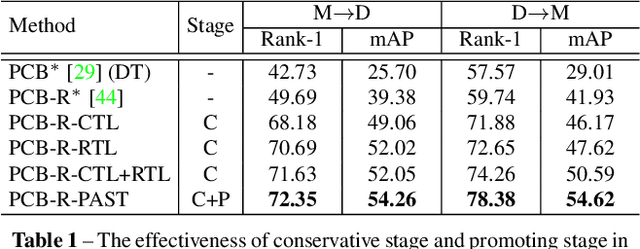

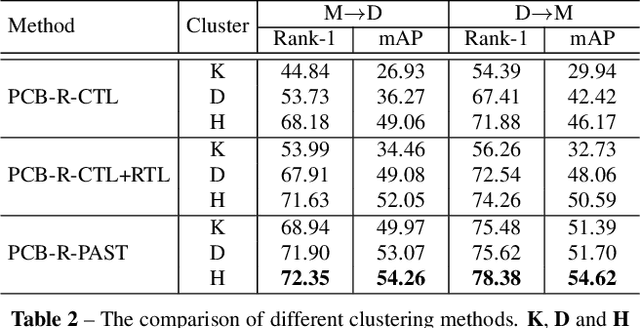
Person re-identification (Re-ID) has achieved great improvement with deep learning and a large amount of labelled training data. However, it remains a challenging task for adapting a model trained in a source domain of labelled data to a target domain of only unlabelled data available. In this work, we develop a self-training method with progressive augmentation framework (PAST) to promote the model performance progressively on the target dataset. Specially, our PAST framework consists of two stages, namely, conservative stage and promoting stage. The conservative stage captures the local structure of target-domain data points with triplet-based loss functions, leading to improved feature representations. The promoting stage continuously optimizes the network by appending a changeable classification layer to the last layer of the model, enabling the use of global information about the data distribution. Importantly, we propose a new self-training strategy that progressively augments the model capability by adopting conservative and promoting stages alternately. Furthermore, to improve the reliability of selected triplet samples, we introduce a ranking-based triplet loss in the conservative stage, which is a label-free objective function basing on the similarities between data pairs. Experiments demonstrate that the proposed method achieves state-of-the-art person Re-ID performance under the unsupervised cross-domain setting. Code is available at: https://tinyurl.com/PASTReID
V-PROM: A Benchmark for Visual Reasoning Using Visual Progressive Matrices
Jul 29, 2019


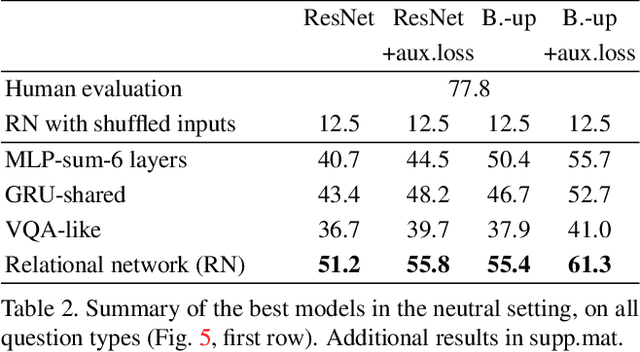
One of the primary challenges faced by deep learning is the degree to which current methods exploit superficial statistics and dataset bias, rather than learning to generalise over the specific representations they have experienced. This is a critical concern because generalisation enables robust reasoning over unseen data, whereas leveraging superficial statistics is fragile to even small changes in data distribution. To illuminate the issue and drive progress towards a solution, we propose a test that explicitly evaluates abstract reasoning over visual data. We introduce a large-scale benchmark of visual questions that involve operations fundamental to many high-level vision tasks, such as comparisons of counts and logical operations on complex visual properties. The benchmark directly measures a method's ability to infer high-level relationships and to generalise them over image-based concepts. It includes multiple training/test splits that require controlled levels of generalization. We evaluate a range of deep learning architectures, and find that existing models, including those popular for vision-and-language tasks, are unable to solve seemingly-simple instances. Models using relational networks fare better but leave substantial room for improvement.
Neighbourhood Watch: Referring Expression Comprehension via Language-guided Graph Attention Networks
Dec 12, 2018

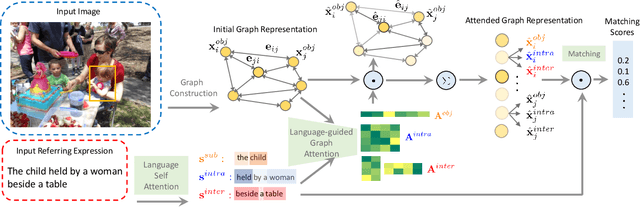
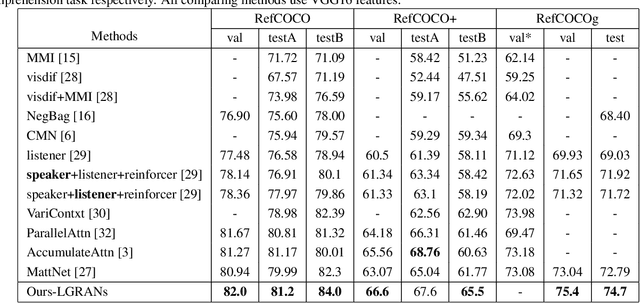
The task in referring expression comprehension is to localise the object instance in an image described by a referring expression phrased in natural language. As a language-to-vision matching task, the key to this problem is to learn a discriminative object feature that can adapt to the expression used. To avoid ambiguity, the expression normally tends to describe not only the properties of the referent itself, but also its relationships to its neighbourhood. To capture and exploit this important information we propose a graph-based, language-guided attention mechanism. Being composed of node attention component and edge attention component, the proposed graph attention mechanism explicitly represents inter-object relationships, and properties with a flexibility and power impossible with competing approaches. Furthermore, the proposed graph attention mechanism enables the comprehension decision to be visualisable and explainable. Experiments on three referring expression comprehension datasets show the advantage of the proposed approach.
Where to Focus: Query Adaptive Matching for Instance Retrieval Using Convolutional Feature Maps
Jun 22, 2016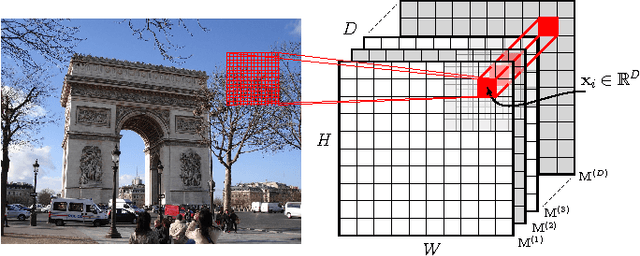

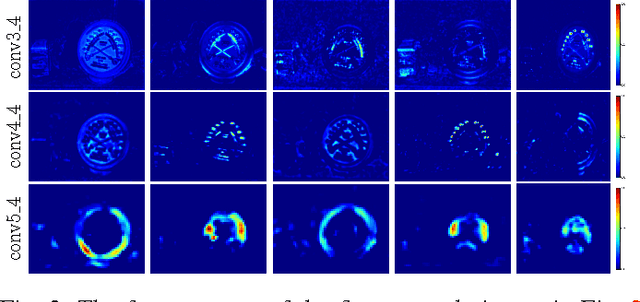
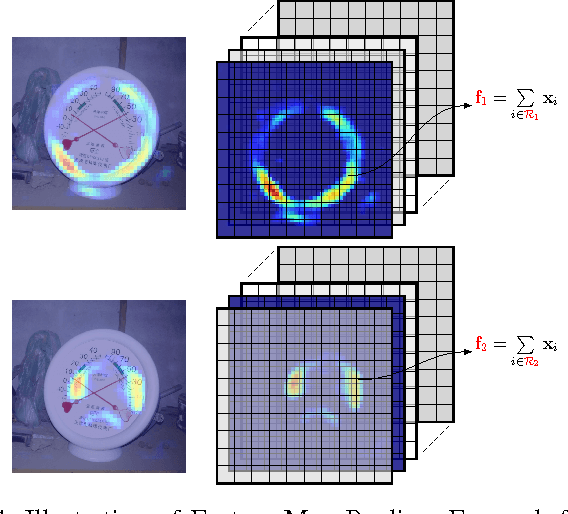
Instance retrieval requires one to search for images that contain a particular object within a large corpus. Recent studies show that using image features generated by pooling convolutional layer feature maps (CFMs) of a pretrained convolutional neural network (CNN) leads to promising performance for this task. However, due to the global pooling strategy adopted in those works, the generated image feature is less robust to image clutter and tends to be contaminated by the irrelevant image patterns. In this article, we alleviate this drawback by proposing a novel reranking algorithm using CFMs to refine the retrieval result obtained by existing methods. Our key idea, called query adaptive matching (QAM), is to first represent the CFMs of each image by a set of base regions which can be freely combined into larger regions-of-interest. Then the similarity between the query and a candidate image is measured by the best similarity score that can be attained by comparing the query feature and the feature pooled from a combined region. We show that the above procedure can be cast as an optimization problem and it can be solved efficiently with an off-the-shelf solver. Besides this general framework, we also propose two practical ways to create the base regions. One is based on the property of the CFM and the other one is based on a multi-scale spatial pyramid scheme. Through extensive experiments, we show that our reranking approaches bring substantial performance improvement and by applying them we can outperform the state of the art on several instance retrieval benchmarks.