 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Part Assembly Generation with Instance Encoded Transformer
Jul 05, 2022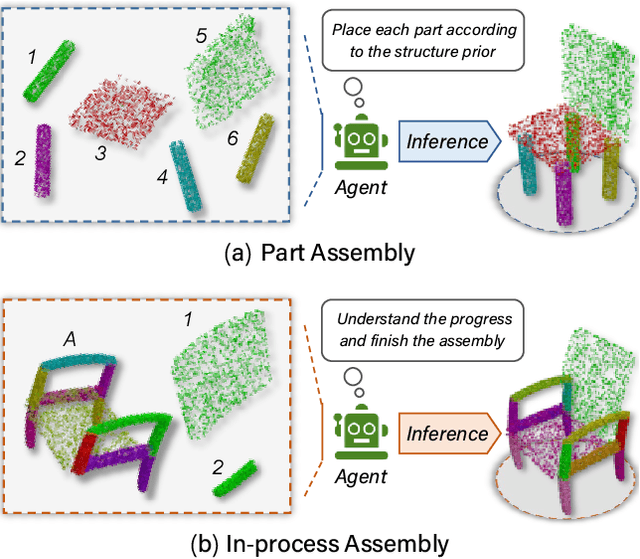
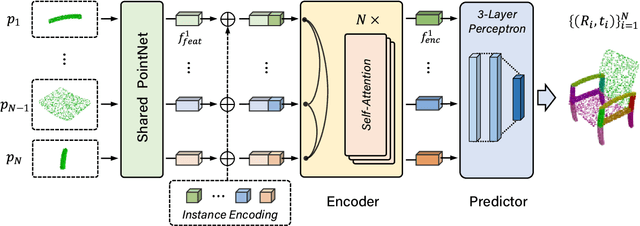
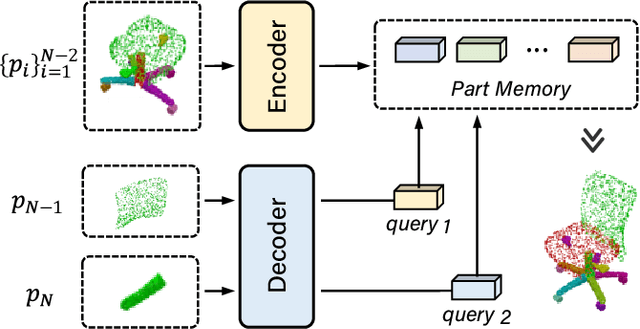
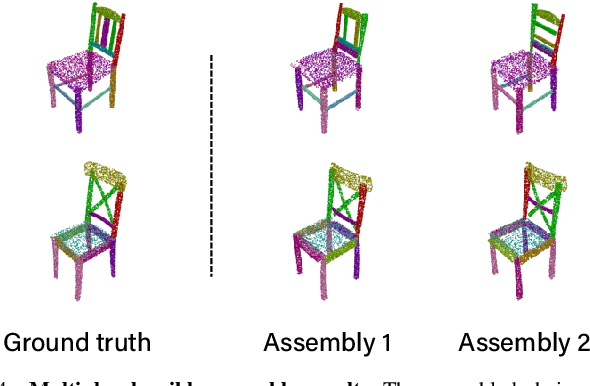
It is desirable to enable robots capable of automatic assembly. Structural understanding of object parts plays a crucial role in this task yet remains relatively unexplored. In this paper, we focus on the setting of furniture assembly from a complete set of part geometries, which is essentially a 6-DoF part pose estimation problem. We propose a multi-layer transformer-based framework that involves geometric and relational reasoning between parts to update the part poses iteratively. We carefully design a unique instance encoding to solve the ambiguity between geometrically-similar parts so that all parts can be distinguished. In addition to assembling from scratch, we extend our framework to a new task called in-process part assembly. Analogous to furniture maintenance, it requires robots to continue with unfinished products and assemble the remaining parts into appropriate positions. Our method achieves far more than 10% improvements over the current state-of-the-art in multiple metrics on the public PartNet dataset. Extensive experiments and quantitative comparisons demonstrate the effectiveness of the proposed framework.
* 8 pages, 7 figures
Self-Supervised Learning by Estimating Twin Class Distributions
Oct 22, 2021



We present TWIST, a novel self-supervised representation learning method by classifying large-scale unlabeled datasets in an end-to-end way. We employ a siamese network terminated by a softmax operation to produce twin class distributions of two augmented images. Without supervision, we enforce the class distributions of different augmentations to be consistent. In the meantime, we regularize the class distributions to make them sharp and diverse. Specifically, we minimize the entropy of the distribution for each sample to make the class prediction for each sample assertive and maximize the entropy of the mean distribution to make the predictions of different samples diverse. In this way, TWIST can naturally avoid the trivial solutions without specific designs such as asymmetric network, stop-gradient operation, or momentum encoder. Different from the clustering-based methods which alternate between clustering and learning, our method is a single learning process guided by a unified loss function. As a result, TWIST outperforms state-of-the-art methods on a wide range of tasks, including unsupervised classification, linear classification, semi-supervised learning, transfer learning, and some dense prediction tasks such as detection and segmentation. Codes and pre-trained models are given on: https://github.com/bytedance/TWIST
SOLO: A Simple Framework for Instance Segmentation
Jun 30, 2021
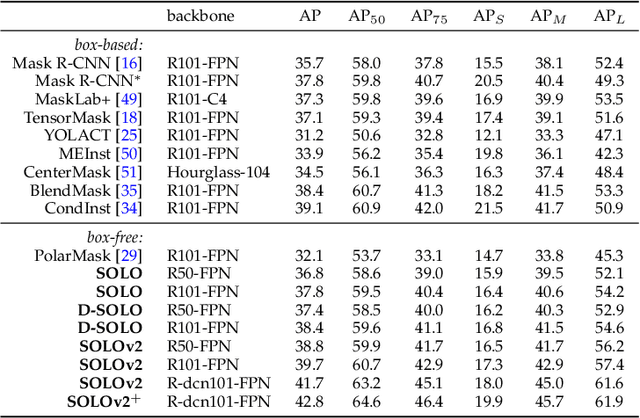


Compared to many other dense prediction tasks, e.g., semantic segmentation, it is the arbitrary number of instances that has made instance segmentation much more challenging. In order to predict a mask for each instance, mainstream approaches either follow the 'detect-then-segment' strategy (e.g., Mask R-CNN), or predict embedding vectors first then cluster pixels into individual instances. In this paper, we view the task of instance segmentation from a completely new perspective by introducing the notion of "instance categories", which assigns categories to each pixel within an instance according to the instance's location. With this notion, we propose segmenting objects by locations (SOLO), a simple, direct, and fast framework for instance segmentation with strong performance. We derive a few SOLO variants (e.g., Vanilla SOLO, Decoupled SOLO, Dynamic SOLO) following the basic principle. Our method directly maps a raw input image to the desired object categories and instance masks, eliminating the need for the grouping post-processing or the bounding box detection. Our approach achieves state-of-the-art results for instance segmentation in terms of both speed and accuracy, while being considerably simpler than the existing methods. Besides instance segmentation, our method yields state-of-the-art results in object detection (from our mask byproduct) and panoptic segmentation. We further demonstrate the flexibility and high-quality segmentation of SOLO by extending it to perform one-stage instance-level image matting. Code is available at: https://git.io/AdelaiDet
TransTrack: Multiple-Object Tracking with Transformer
Dec 31, 2020


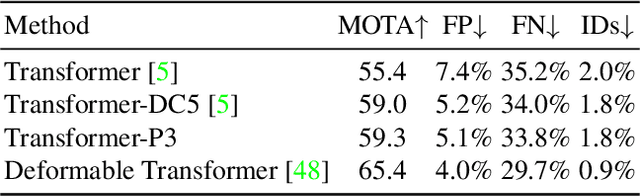
Multiple-object tracking(MOT) is mostly dominated by complex and multi-step tracking-by-detection algorithm, which performs object detection, feature extraction and temporal association, separately. Query-key mechanism in single-object tracking(SOT), which tracks the object of the current frame by object feature of the previous frame, has great potential to set up a simple joint-detection-and-tracking MOT paradigm. Nonetheless, the query-key method is seldom studied due to its inability to detect new-coming objects. In this work, we propose TransTrack, a baseline for MOT with Transformer. It takes advantage of query-key mechanism and introduces a set of learned object queries into the pipeline to enable detecting new-coming objects. TransTrack has three main advantages: (1) It is an online joint-detection-and-tracking pipeline based on query-key mechanism. Complex and multi-step components in the previous methods are simplified. (2) It is a brand new architecture based on Transformer. The learned object query detects objects in the current frame. The object feature query from the previous frame associates those current objects with the previous ones. (3) For the first time, we demonstrate a much simple and effective method based on query-key mechanism and Transformer architecture could achieve competitive 65.8\% MOTA on the MOT17 challenge dataset. We hope TransTrack can provide a new perspective for multiple-object tracking. The code is available at: \url{https://github.com/PeizeSun/TransTrack}.
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
Nov 25, 2020



We present Sparse R-CNN, a purely sparse method for object detection in images. Existing works on object detection heavily rely on dense object candidates, such as $k$ anchor boxes pre-defined on all grids of image feature map of size $H\times W$. In our method, however, a fixed sparse set of learned object proposals, total length of $N$, are provided to object recognition head to perform classification and location. By eliminating $HWk$ (up to hundreds of thousands) hand-designed object candidates to $N$ (e.g. 100) learnable proposals, Sparse R-CNN completely avoids all efforts related to object candidates design and many-to-one label assignment. More importantly, final predictions are directly output without non-maximum suppression post-procedure. Sparse R-CNN demonstrates accuracy, run-time and training convergence performance on par with the well-established detector baselines on the challenging COCO dataset, e.g., achieving 44.5 AP in standard $3\times$ training schedule and running at 22 fps using ResNet-50 FPN model. We hope our work could inspire re-thinking the convention of dense prior in object detectors. The code is available at: https://github.com/PeizeSun/SparseR-CNN.
Dense Contrastive Learning for Self-Supervised Visual Pre-Training
Nov 18, 2020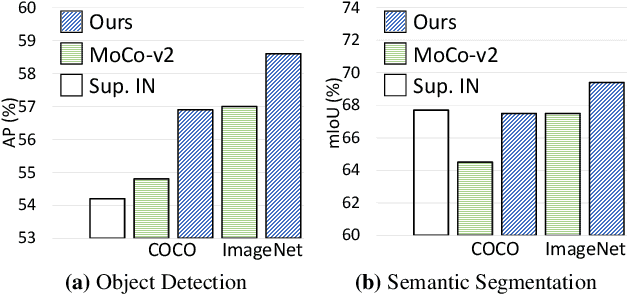



To date, most existing self-supervised learning methods are designed and optimized for image classification. These pre-trained models can be sub-optimal for dense prediction tasks due to the discrepancy between image-level prediction and pixel-level prediction. To fill this gap, we aim to design an effective, dense self-supervised learning method that directly works at the level of pixels (or local features) by taking into account the correspondence between local features. We present dense contrastive learning, which implements self-supervised learning by optimizing a pairwise contrastive (dis)similarity loss at the pixel level between two views of input images. Compared to the baseline method MoCo-v2, our method introduces negligible computation overhead (only <1% slower), but demonstrates consistently superior performance when transferring to downstream dense prediction tasks including object detection, semantic segmentation and instance segmentation; and outperforms the state-of-the-art methods by a large margin. Specifically, over the strong MoCo-v2 baseline, our method achieves significant improvements of 2.0% AP on PASCAL VOC object detection, 1.1% AP on COCO object detection, 0.9% AP on COCO instance segmentation, 3.0% mIoU on PASCAL VOC semantic segmentation and 1.8% mIoU on Cityscapes semantic segmentation. Code is available at: https://git.io/AdelaiDet
Mask Encoding for Single Shot Instance Segmentation
Mar 26, 2020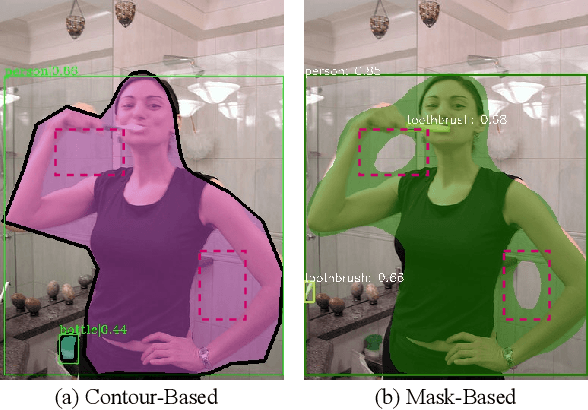

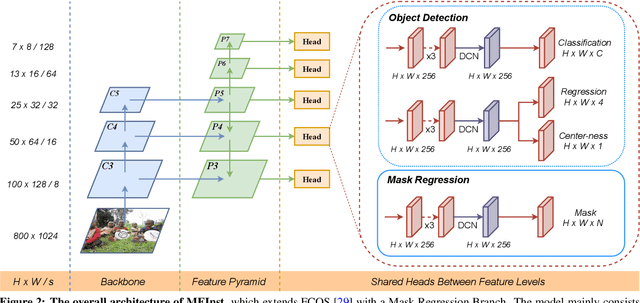
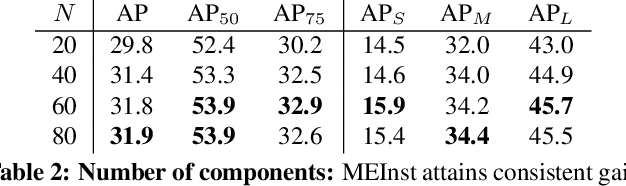
To date, instance segmentation is dominated by twostage methods, as pioneered by Mask R-CNN. In contrast, one-stage alternatives cannot compete with Mask R-CNN in mask AP, mainly due to the difficulty of compactly representing masks, making the design of one-stage methods very challenging. In this work, we propose a simple singleshot instance segmentation framework, termed mask encoding based instance segmentation (MEInst). Instead of predicting the two-dimensional mask directly, MEInst distills it into a compact and fixed-dimensional representation vector, which allows the instance segmentation task to be incorporated into one-stage bounding-box detectors and results in a simple yet efficient instance segmentation framework. The proposed one-stage MEInst achieves 36.4% in mask AP with single-model (ResNeXt-101-FPN backbone) and single-scale testing on the MS-COCO benchmark. We show that the much simpler and flexible one-stage instance segmentation method, can also achieve competitive performance. This framework can be easily adapted for other instance-level recognition tasks. Code is available at: https://git.io/AdelaiDet
SOLOv2: Dynamic, Faster and Stronger
Mar 23, 2020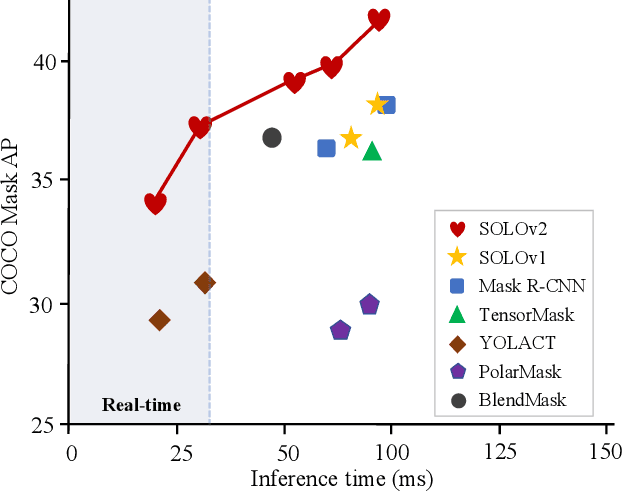
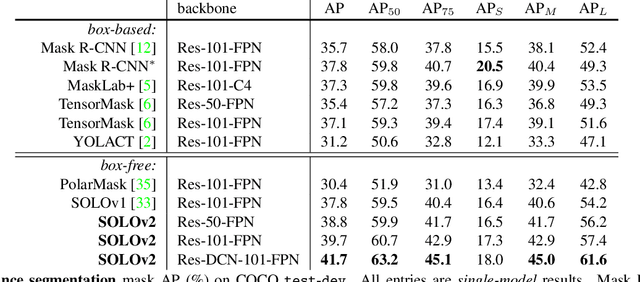
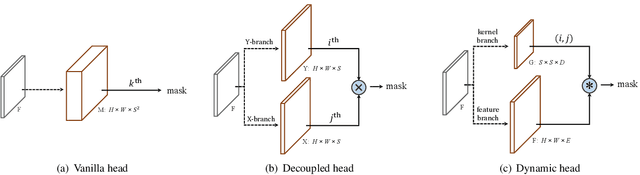
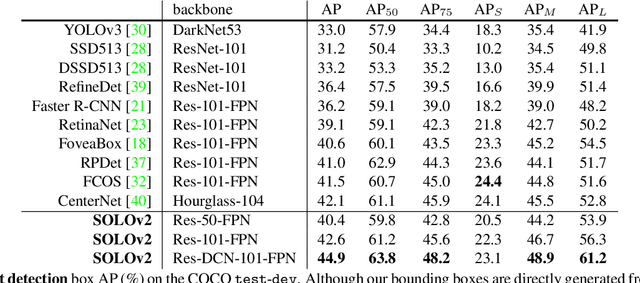
In this work, we aim at building a simple, direct, and fast instance segmentation framework with strong performance. We follow the principle of the SOLO method of Wang et al. "SOLO: segmenting objects by locations". Importantly, we take one step further by dynamically learning the mask head of the object segmenter such that the mask head is conditioned on the location. Specifically, the mask branch is decoupled into a mask kernel branch and mask feature branch, which are responsible for learning the convolution kernel and the convolved features respectively. Moreover, we propose Matrix NMS (non maximum suppression) to significantly reduce the inference time overhead due to NMS of masks. Our Matrix NMS performs NMS with parallel matrix operations in one shot, and yields better results. We demonstrate a simple direct instance segmentation system, outperforming a few state-of-the-art methods in both speed and accuracy. A light-weight version of SOLOv2 executes at 31.3 FPS and yields 37.1% AP. Moreover, our state-of-the-art results in object detection (from our mask byproduct) and panoptic segmentation show the potential to serve as a new strong baseline for many instance-level recognition tasks besides instance segmentation. Code is available at: https://git.io/AdelaiDet
Part-Guided Attention Learning for Vehicle Re-Identification
Sep 19, 2019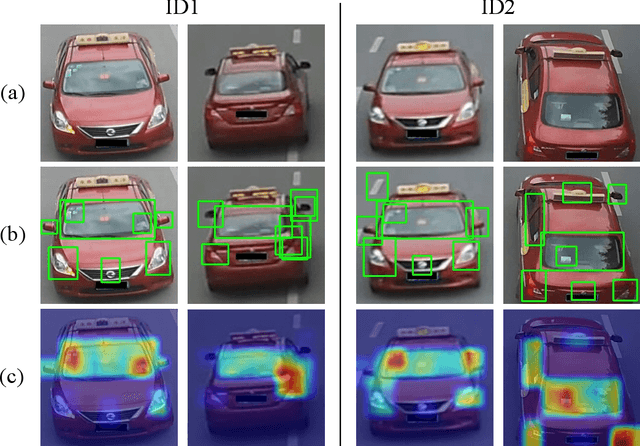
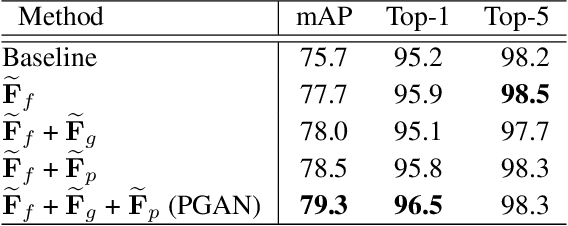
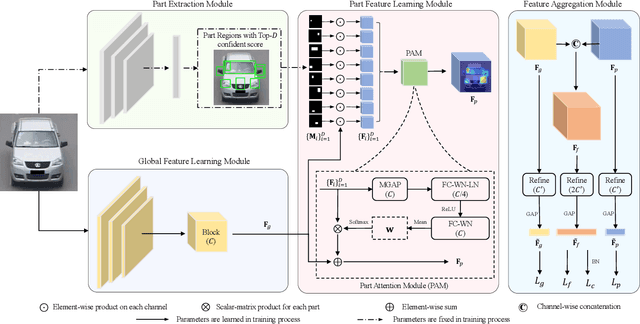
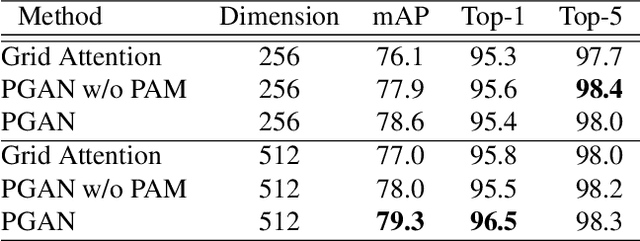
Vehicle re-identification (Re-ID) often requires one to recognize the fine-grained visual differences between vehicles. Besides the holistic appearance of vehicles which is easily affected by the viewpoint variation and distortion, vehicle parts also provide crucial cues to differentiate near-identical vehicles. Motivated by these observations, we introduce a Part-Guided Attention Network (PGAN) to pinpoint the prominent part regions and effectively combine the global and part information for discriminative feature learning. PGAN first detects the locations of different part components and salient regions regardless of the vehicle identity, which serve as the bottom-up attention to narrow down the possible searching regions. To estimate the importance of detected parts, we propose a Part Attention Module (PAM) to adaptively locate the most discriminative regions with high-attention weights and suppress the distraction of irrelevant parts with relatively low weights. The PAM is guided by the Re-ID loss and therefore provides top-down attention that enables attention to be calculated at the level of car parts and other salient regions. Finally, we aggregate the global appearance and part features to improve the feature performance further. The PGAN combines part-guided bottom-up and top-down attention, global and part visual features in an end-to-end framework. Extensive experiments demonstrate that the proposed method achieves new state-of-the-art vehicle Re-ID performance on four large-scale benchmark datasets.