 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGFormer: A Cross-Attention Based Grid-Free Transformer for Radio Map Estimation
Mar 22, 2026Radio map estimation (RME), which predicts wireless signal metrics at unmeasured locations from sparse measurements, has attracted growing attention as a key enabler of intelligent wireless networks. The majority of existing RME techniques employ grid-based strategies to process sparse measurements, where the pursuit of accuracy results in significant computational inefficiency and inflexibility for off-grid prediction. In contrast, grid-free approaches directly exploit coordinate features to capture location-specific spatial dependencies, enabling signal prediction at arbitrary locations without relying on predefined grids. However, current grid-free approaches demand substantial preprocessing overhead for constructing the spatial representation, leading to high complexity and constrained adaptability. To address these limitations, this paper proposes a novel cross-attention grid-free based transformer model for RME. We introduce a lightweight spatial embedding module that incorporates environmental knowledge into high-dimensional feature construction. A cross-attention transformer then models the spatial correlation between target and measurement points. The simulation results demonstrate that our proposed method reduces RMSE by up to 6%, outperforming grid-based and gridfree baselines.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025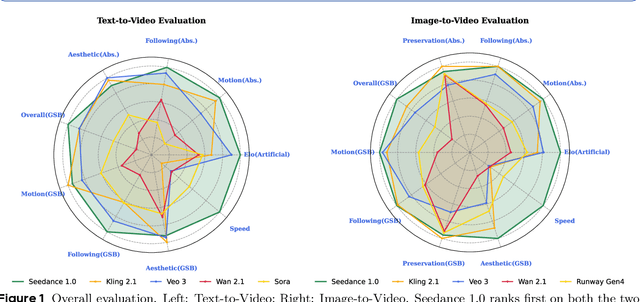
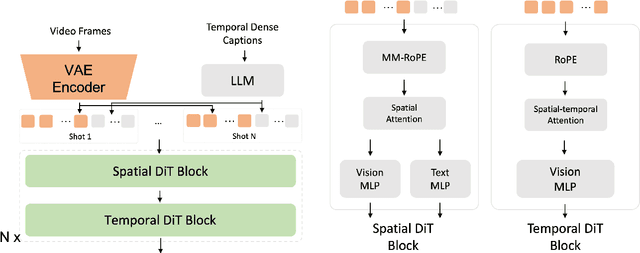
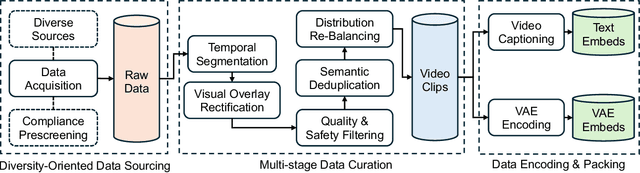
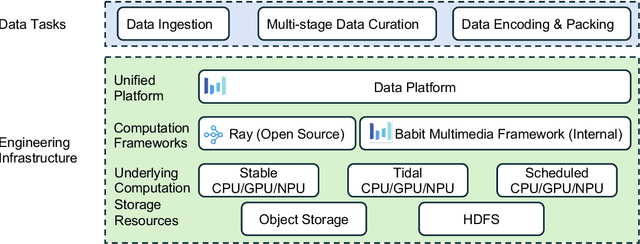
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Scaling Diffusion Transformers Efficiently via $μ$P
May 21, 2025Diffusion Transformers have emerged as the foundation for vision generative models, but their scalability is limited by the high cost of hyperparameter (HP) tuning at large scales. Recently, Maximal Update Parametrization ($\mu$P) was proposed for vanilla Transformers, which enables stable HP transfer from small to large language models, and dramatically reduces tuning costs. However, it remains unclear whether $\mu$P of vanilla Transformers extends to diffusion Transformers, which differ architecturally and objectively. In this work, we generalize standard $\mu$P to diffusion Transformers and validate its effectiveness through large-scale experiments. First, we rigorously prove that $\mu$P of mainstream diffusion Transformers, including DiT, U-ViT, PixArt-$\alpha$, and MMDiT, aligns with that of the vanilla Transformer, enabling the direct application of existing $\mu$P methodologies. Leveraging this result, we systematically demonstrate that DiT-$\mu$P enjoys robust HP transferability. Notably, DiT-XL-2-$\mu$P with transferred learning rate achieves 2.9 times faster convergence than the original DiT-XL-2. Finally, we validate the effectiveness of $\mu$P on text-to-image generation by scaling PixArt-$\alpha$ from 0.04B to 0.61B and MMDiT from 0.18B to 18B. In both cases, models under $\mu$P outperform their respective baselines while requiring small tuning cost, only 5.5% of one training run for PixArt-$\alpha$ and 3% of consumption by human experts for MMDiT-18B. These results establish $\mu$P as a principled and efficient framework for scaling diffusion Transformers.
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
May 08, 2025Recent progress in unified models for image understanding and generation has been impressive, yet most approaches remain limited to single-modal generation conditioned on multiple modalities. In this paper, we present Mogao, a unified framework that advances this paradigm by enabling interleaved multi-modal generation through a causal approach. Mogao integrates a set of key technical improvements in architecture design, including a deep-fusion design, dual vision encoders, interleaved rotary position embeddings, and multi-modal classifier-free guidance, which allow it to harness the strengths of both autoregressive models for text generation and diffusion models for high-quality image synthesis. These practical improvements also make Mogao particularly effective to process interleaved sequences of text and images arbitrarily. To further unlock the potential of unified models, we introduce an efficient training strategy on a large-scale, in-house dataset specifically curated for joint text and image generation. Extensive experiments show that Mogao not only achieves state-of-the-art performance in multi-modal understanding and text-to-image generation, but also excels in producing high-quality, coherent interleaved outputs. Its emergent capabilities in zero-shot image editing and compositional generation highlight Mogao as a practical omni-modal foundation model, paving the way for future development and scaling the unified multi-modal systems.
Seedream 3.0 Technical Report
Apr 16, 2025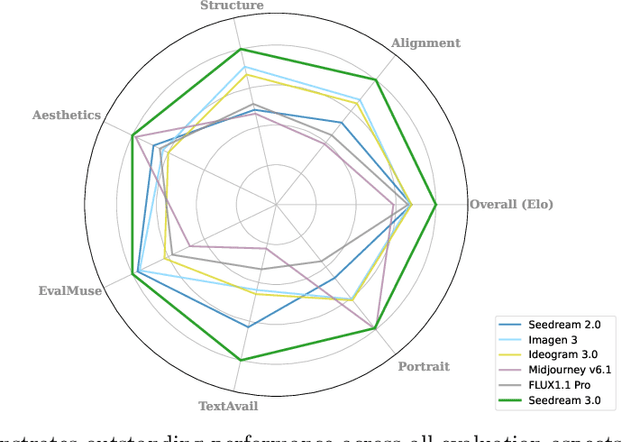


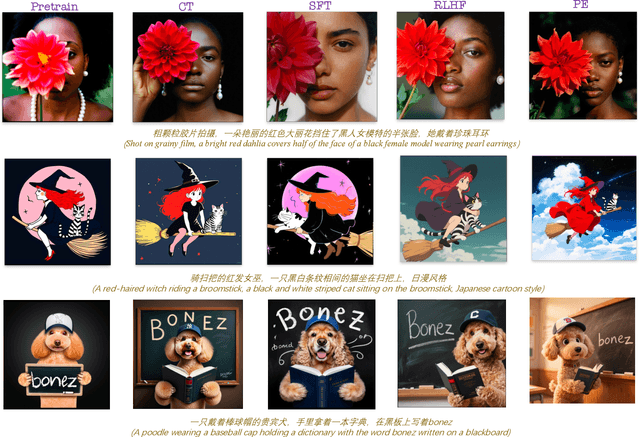
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
SimpleAR: Pushing the Frontier of Autoregressive Visual Generation through Pretraining, SFT, and RL
Apr 15, 2025



This work presents SimpleAR, a vanilla autoregressive visual generation framework without complex architecure modifications. Through careful exploration of training and inference optimization, we demonstrate that: 1) with only 0.5B parameters, our model can generate 1024x1024 resolution images with high fidelity, and achieve competitive results on challenging text-to-image benchmarks, e.g., 0.59 on GenEval and 79.66 on DPG; 2) both supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) training could lead to significant improvements on generation aesthectics and prompt alignment; and 3) when optimized with inference acceleraton techniques like vLLM, the time for SimpleAR to generate an 1024x1024 image could be reduced to around 14 seconds. By sharing these findings and open-sourcing the code, we hope to reveal the potential of autoregressive visual generation and encourage more participation in this research field. Code is available at https://github.com/wdrink/SimpleAR.
DDT: Decoupled Diffusion Transformer
Apr 09, 2025

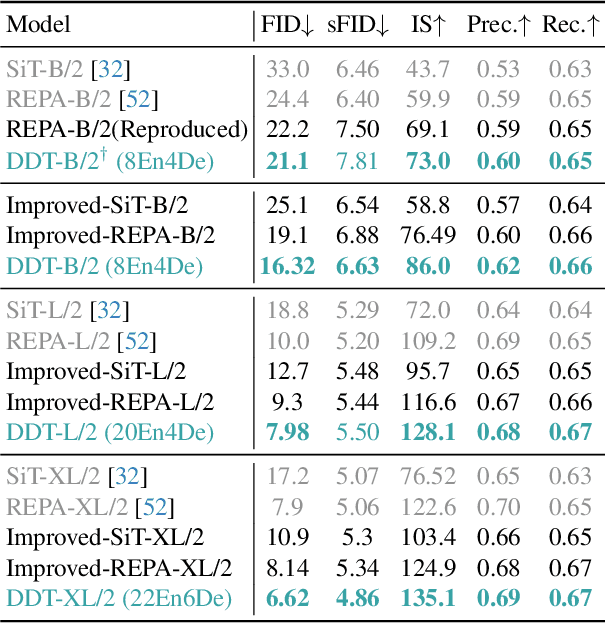

Diffusion transformers have demonstrated remarkable generation quality, albeit requiring longer training iterations and numerous inference steps. In each denoising step, diffusion transformers encode the noisy inputs to extract the lower-frequency semantic component and then decode the higher frequency with identical modules. This scheme creates an inherent optimization dilemma: encoding low-frequency semantics necessitates reducing high-frequency components, creating tension between semantic encoding and high-frequency decoding. To resolve this challenge, we propose a new \textbf{\color{ddt}D}ecoupled \textbf{\color{ddt}D}iffusion \textbf{\color{ddt}T}ransformer~(\textbf{\color{ddt}DDT}), with a decoupled design of a dedicated condition encoder for semantic extraction alongside a specialized velocity decoder. Our experiments reveal that a more substantial encoder yields performance improvements as model size increases. For ImageNet $256\times256$, Our DDT-XL/2 achieves a new state-of-the-art performance of {1.31 FID}~(nearly $4\times$ faster training convergence compared to previous diffusion transformers). For ImageNet $512\times512$, Our DDT-XL/2 achieves a new state-of-the-art FID of 1.28. Additionally, as a beneficial by-product, our decoupled architecture enhances inference speed by enabling the sharing self-condition between adjacent denoising steps. To minimize performance degradation, we propose a novel statistical dynamic programming approach to identify optimal sharing strategies.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
Towards Trustworthy Federated Learning
Mar 05, 2025



This paper develops a comprehensive framework to address three critical trustworthy challenges in federated learning (FL): robustness against Byzantine attacks, fairness, and privacy preservation. To improve the system's defense against Byzantine attacks that send malicious information to bias the system's performance, we develop a Two-sided Norm Based Screening (TNBS) mechanism, which allows the central server to crop the gradients that have the l lowest norms and h highest norms. TNBS functions as a screening tool to filter out potential malicious participants whose gradients are far from the honest ones. To promote egalitarian fairness, we adopt the q-fair federated learning (q-FFL). Furthermore, we adopt a differential privacy-based scheme to prevent raw data at local clients from being inferred by curious parties. Convergence guarantees are provided for the proposed framework under different scenarios. Experimental results on real datasets demonstrate that the proposed framework effectively improves robustness and fairness while managing the trade-off between privacy and accuracy. This work appears to be the first study that experimentally and theoretically addresses fairness, privacy, and robustness in trustworthy FL.
Distributed Swarm Learning for Edge Internet of Things
Mar 29, 2024The rapid growth of Internet of Things (IoT) has led to the widespread deployment of smart IoT devices at wireless edge for collaborative machine learning tasks, ushering in a new era of edge learning. With a huge number of hardware-constrained IoT devices operating in resource-limited wireless networks, edge learning encounters substantial challenges, including communication and computation bottlenecks, device and data heterogeneity, security risks, privacy leakages, non-convex optimization, and complex wireless environments. To address these issues, this article explores a novel framework known as distributed swarm learning (DSL), which combines artificial intelligence and biological swarm intelligence in a holistic manner. By harnessing advanced signal processing and communications, DSL provides efficient solutions and robust tools for large-scale IoT at the edge of wireless networks.