 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardDance: Reward Scaling in Visual Generation
Sep 10, 2025Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.
Seedream 3.0 Technical Report
Apr 16, 2025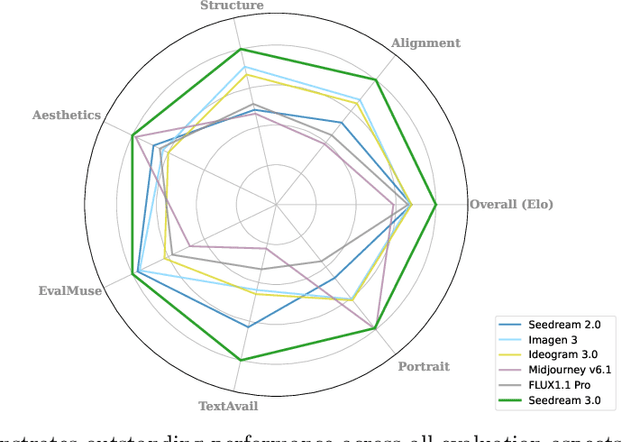


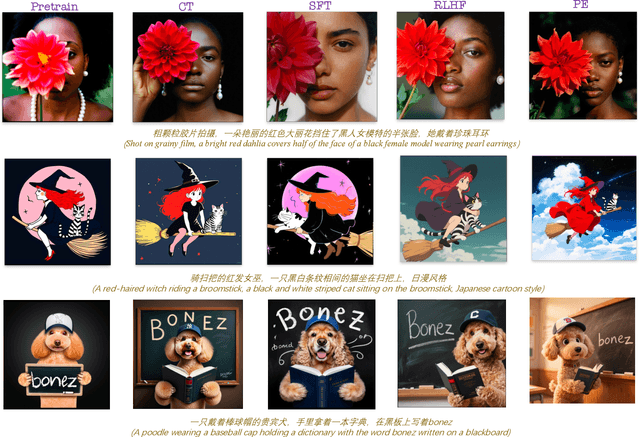
We present Seedream 3.0, a high-performance Chinese-English bilingual image generation foundation model. We develop several technical improvements to address existing challenges in Seedream 2.0, including alignment with complicated prompts, fine-grained typography generation, suboptimal visual aesthetics and fidelity, and limited image resolutions. Specifically, the advancements of Seedream 3.0 stem from improvements across the entire pipeline, from data construction to model deployment. At the data stratum, we double the dataset using a defect-aware training paradigm and a dual-axis collaborative data-sampling framework. Furthermore, we adopt several effective techniques such as mixed-resolution training, cross-modality RoPE, representation alignment loss, and resolution-aware timestep sampling in the pre-training phase. During the post-training stage, we utilize diversified aesthetic captions in SFT, and a VLM-based reward model with scaling, thereby achieving outputs that well align with human preferences. Furthermore, Seedream 3.0 pioneers a novel acceleration paradigm. By employing consistent noise expectation and importance-aware timestep sampling, we achieve a 4 to 8 times speedup while maintaining image quality. Seedream 3.0 demonstrates significant improvements over Seedream 2.0: it enhances overall capabilities, in particular for text-rendering in complicated Chinese characters which is important to professional typography generation. In addition, it provides native high-resolution output (up to 2K), allowing it to generate images with high visual quality.
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
Mar 10, 2025Rapid advancement of diffusion models has catalyzed remarkable progress in the field of image generation. However, prevalent models such as Flux, SD3.5 and Midjourney, still grapple with issues like model bias, limited text rendering capabilities, and insufficient understanding of Chinese cultural nuances. To address these limitations, we present Seedream 2.0, a native Chinese-English bilingual image generation foundation model that excels across diverse dimensions, which adeptly manages text prompt in both Chinese and English, supporting bilingual image generation and text rendering. We develop a powerful data system that facilitates knowledge integration, and a caption system that balances the accuracy and richness for image description. Particularly, Seedream is integrated with a self-developed bilingual large language model as a text encoder, allowing it to learn native knowledge directly from massive data. This enable it to generate high-fidelity images with accurate cultural nuances and aesthetic expressions described in either Chinese or English. Beside, Glyph-Aligned ByT5 is applied for flexible character-level text rendering, while a Scaled ROPE generalizes well to untrained resolutions. Multi-phase post-training optimizations, including SFT and RLHF iterations, further improve the overall capability. Through extensive experimentation, we demonstrate that Seedream 2.0 achieves state-of-the-art performance across multiple aspects, including prompt-following, aesthetics, text rendering, and structural correctness. Furthermore, Seedream 2.0 has been optimized through multiple RLHF iterations to closely align its output with human preferences, as revealed by its outstanding ELO score. In addition, it can be readily adapted to an instruction-based image editing model, such as SeedEdit, with strong editing capability that balances instruction-following and image consistency.
MSTRIQ: No Reference Image Quality Assessment Based on Swin Transformer with Multi-Stage Fusion
May 23, 2022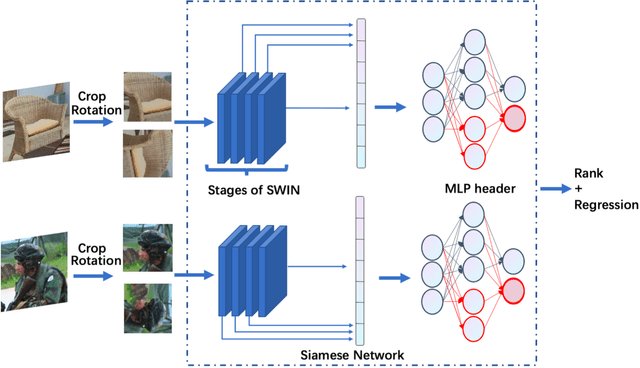
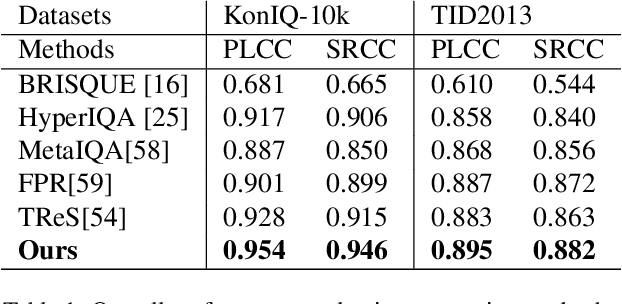
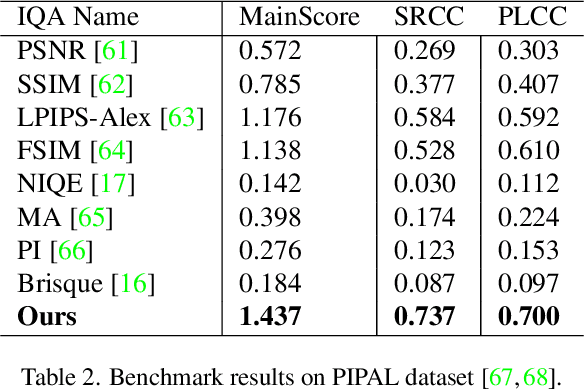
Measuring the perceptual quality of images automatically is an essential task in the area of computer vision, as degradations on image quality can exist in many processes from image acquisition, transmission to enhancing. Many Image Quality Assessment(IQA) algorithms have been designed to tackle this problem. However, it still remains un settled due to the various types of image distortions and the lack of large-scale human-rated datasets. In this paper, we propose a novel algorithm based on the Swin Transformer [31] with fused features from multiple stages, which aggregates information from both local and global features to better predict the quality. To address the issues of small-scale datasets, relative rankings of images have been taken into account together with regression loss to simultaneously optimize the model. Furthermore, effective data augmentation strategies are also used to improve the performance. In comparisons with previous works, experiments are carried out on two standard IQA datasets and a challenge dataset. The results demonstrate the effectiveness of our work. The proposed method outperforms other methods on standard datasets and ranks 2nd in the no-reference track of NTIRE 2022 Perceptual Image Quality Assessment Challenge [53]. It verifies that our method is promising in solving diverse IQA problems and thus can be used to real-word applications.