 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safe Screening Rule with Bi-level Optimization of $ν$ Support Vector Machine
Mar 04, 2024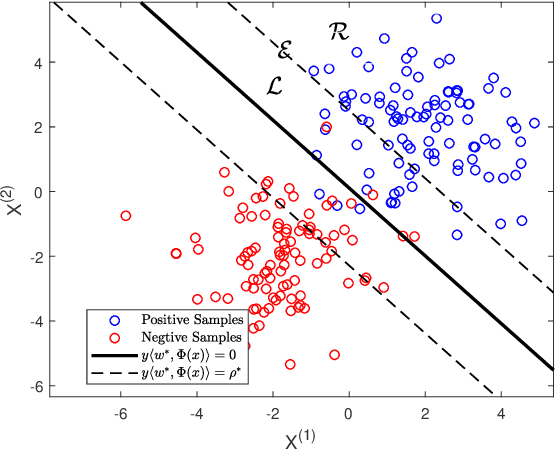
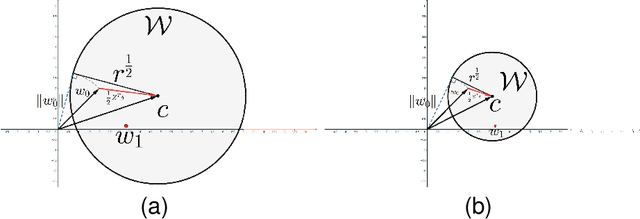
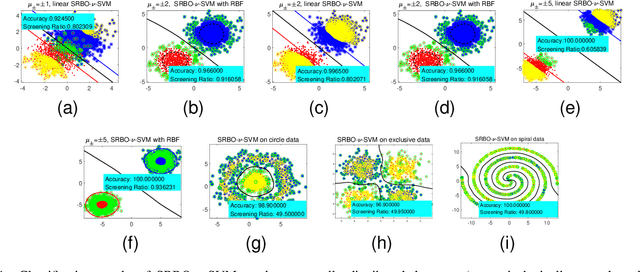
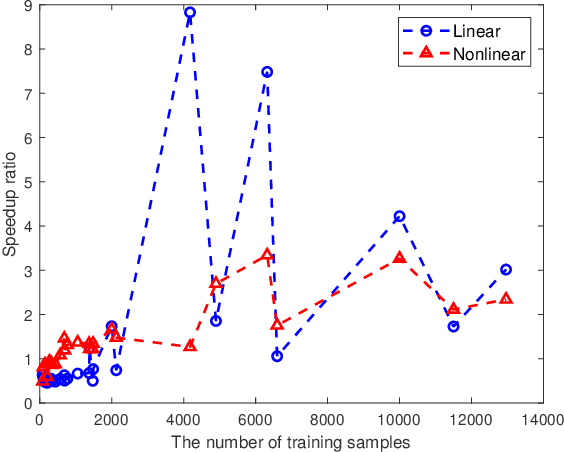
Support vector machine (SVM) has achieved many successes in machine learning, especially for a small sample problem. As a famous extension of the traditional SVM, the $\nu$ support vector machine ($\nu$-SVM) has shown outstanding performance due to its great model interpretability. However, it still faces challenges in training overhead for large-scale problems. To address this issue, we propose a safe screening rule with bi-level optimization for $\nu$-SVM (SRBO-$\nu$-SVM) which can screen out inactive samples before training and reduce the computational cost without sacrificing the prediction accuracy. Our SRBO-$\nu$-SVM is strictly deduced by integrating the Karush-Kuhn-Tucker (KKT) conditions, the variational inequalities of convex problems and the $\nu$-property. Furthermore, we develop an efficient dual coordinate descent method (DCDM) to further improve computational speed. Finally, a unified framework for SRBO is proposed to accelerate many SVM-type models, and it is successfully applied to one-class SVM. Experimental results on 6 artificial data sets and 30 benchmark data sets have verified the effectiveness and safety of our proposed methods in supervised and unsupervised tasks.
DKiS: Decay weight invertible image steganography with private key
Nov 30, 2023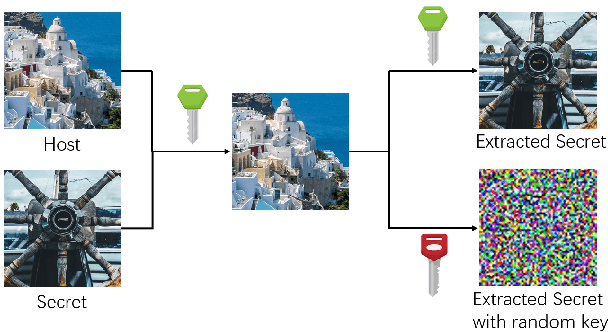
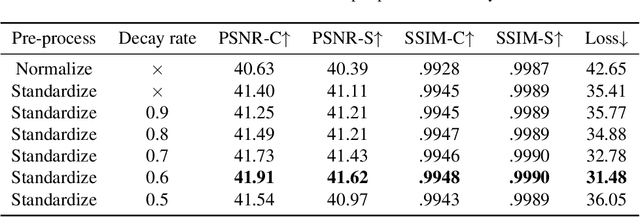
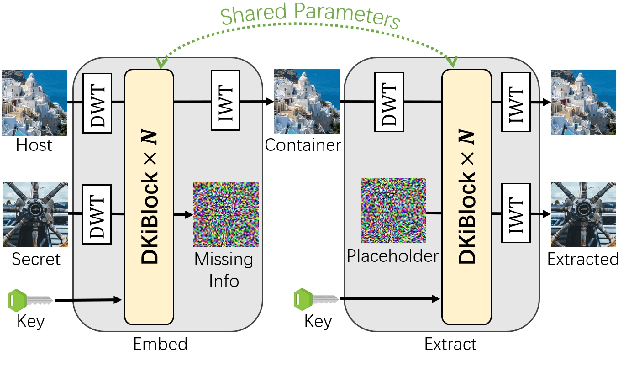

Image steganography, the practice of concealing information within another image, traditionally faces security challenges when its methods become publicly known. To counteract this, we introduce a novel private key-based image steganography technique. This approach ensures the security of hidden information, requiring a corresponding private key for access, irrespective of the public knowledge of the steganography method. We present experimental evidence demonstrating our method's effectiveness, showcasing its real-world applicability. Additionally, we identified a critical challenge in the invertible image steganography process: the transfer of non-essential, or `garbage', information from the secret to the host pipeline. To address this, we introduced the decay weight to control the information transfer, filtering out irrelevant data and enhancing the performance of image steganography. Our code is publicly accessible at https://github.com/yanghangAI/DKiS, and a practical demonstration is available at http://yanghang.site/hidekey.
PRIS: Practical robust invertible network for image steganography
Sep 24, 2023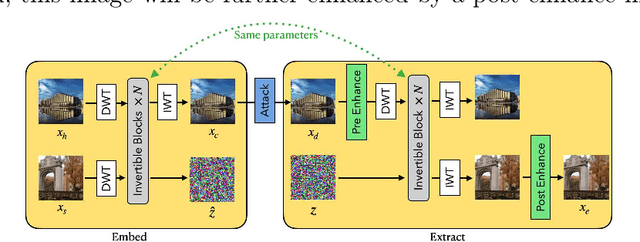
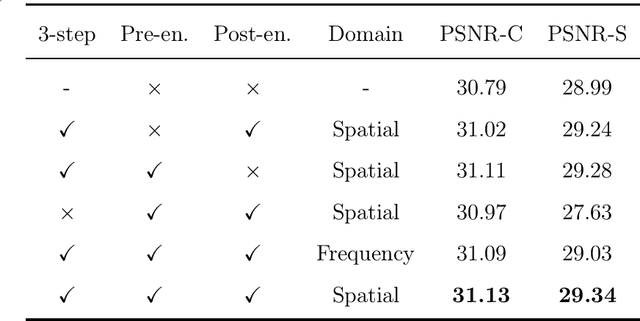
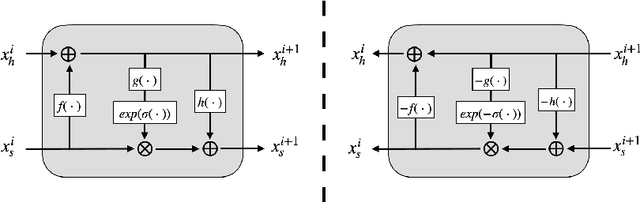
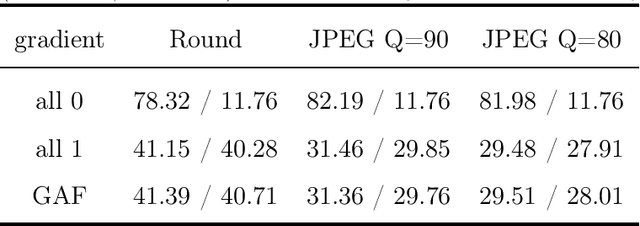
Image steganography is a technique of hiding secret information inside another image, so that the secret is not visible to human eyes and can be recovered when needed. Most of the existing image steganography methods have low hiding robustness when the container images affected by distortion. Such as Gaussian noise and lossy compression. This paper proposed PRIS to improve the robustness of image steganography, it based on invertible neural networks, and put two enhance modules before and after the extraction process with a 3-step training strategy. Moreover, rounding error is considered which is always ignored by existing methods, but actually it is unavoidable in practical. A gradient approximation function (GAF) is also proposed to overcome the undifferentiable issue of rounding distortion. Experimental results show that our PRIS outperforms the state-of-the-art robust image steganography method in both robustness and practicability. Codes are available at https://github.com/yanghangAI/PRIS, demonstration of our model in practical at http://yanghang.site/hide/.
MSTRIQ: No Reference Image Quality Assessment Based on Swin Transformer with Multi-Stage Fusion
May 23, 2022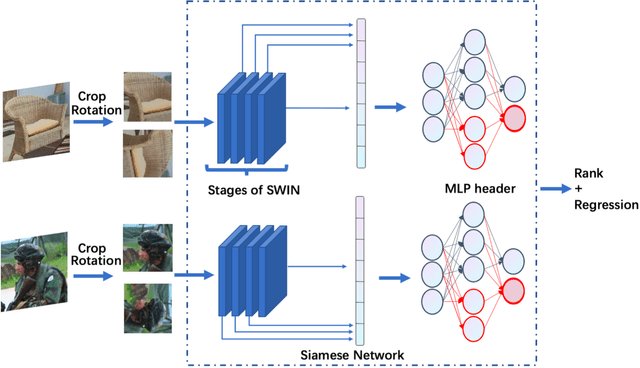
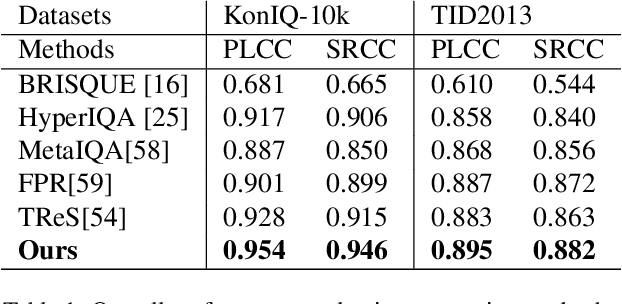
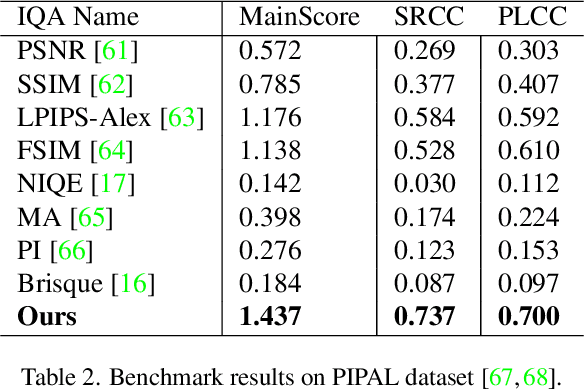
Measuring the perceptual quality of images automatically is an essential task in the area of computer vision, as degradations on image quality can exist in many processes from image acquisition, transmission to enhancing. Many Image Quality Assessment(IQA) algorithms have been designed to tackle this problem. However, it still remains un settled due to the various types of image distortions and the lack of large-scale human-rated datasets. In this paper, we propose a novel algorithm based on the Swin Transformer [31] with fused features from multiple stages, which aggregates information from both local and global features to better predict the quality. To address the issues of small-scale datasets, relative rankings of images have been taken into account together with regression loss to simultaneously optimize the model. Furthermore, effective data augmentation strategies are also used to improve the performance. In comparisons with previous works, experiments are carried out on two standard IQA datasets and a challenge dataset. The results demonstrate the effectiveness of our work. The proposed method outperforms other methods on standard datasets and ranks 2nd in the no-reference track of NTIRE 2022 Perceptual Image Quality Assessment Challenge [53]. It verifies that our method is promising in solving diverse IQA problems and thus can be used to real-word applications.
Multi-task nonparallel support vector machine for classification
Apr 05, 2022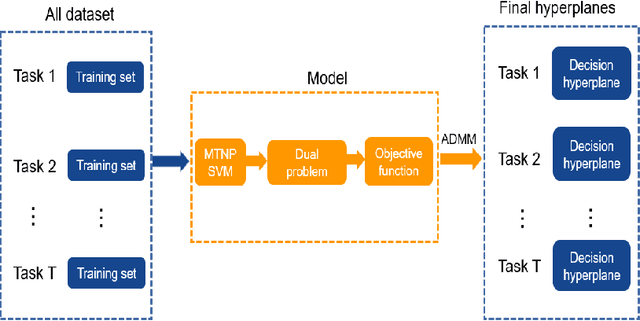
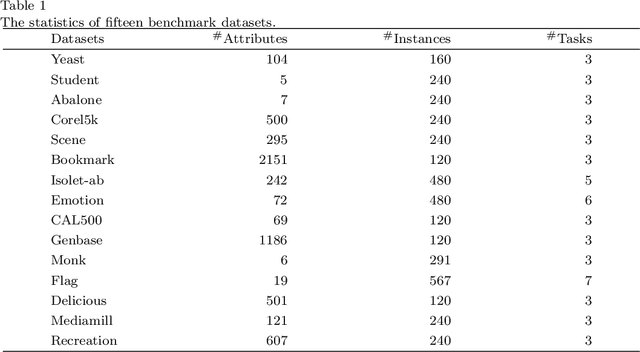
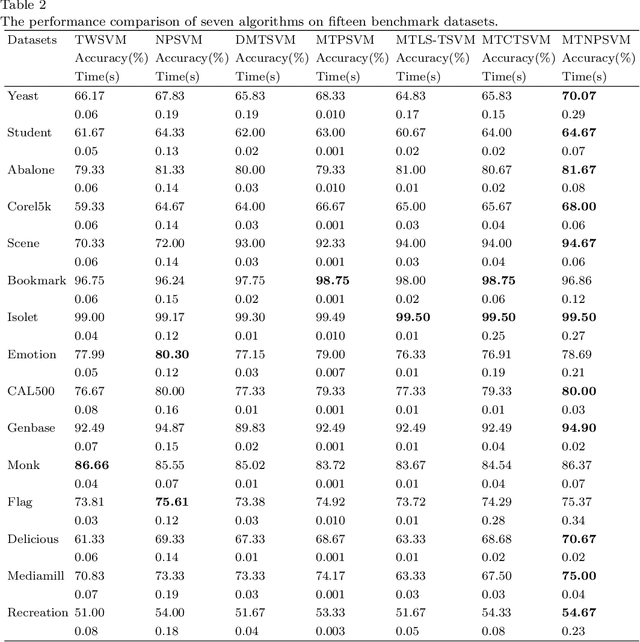
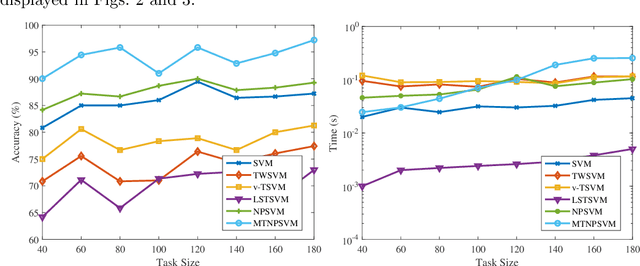
Direct multi-task twin support vector machine (DMTSVM) explores the shared information between multiple correlated tasks, then it produces better generalization performance. However, it contains matrix inversion operation when solving the dual problems, so it costs much running time. Moreover, kernel trick cannot be directly utilized in the nonlinear case. To effectively avoid above problems, a novel multi-task nonparallel support vector machine (MTNPSVM) including linear and nonlinear cases is proposed in this paper. By introducing epsilon-insensitive loss instead of square loss in DMTSVM, MTNPSVM effectively avoids matrix inversion operation and takes full advantage of the kernel trick. Theoretical implication of the model is further discussed. To further improve the computational efficiency, the alternating direction method of multipliers (ADMM) is employed when solving the dual problem. The computational complexity and convergence of the algorithm are provided. In addition, the property and sensitivity of the parameter in model are further explored. The experimental results on fifteen benchmark datasets and twelve image datasets demonstrate the validity of MTNPSVM in comparison with the state-of-the-art algorithms. Finally, it is applied to real Chinese Wine dataset, and also verifies its effectiveness.
Multi-Class Classification from Single-Class Data with Confidences
Jun 16, 2021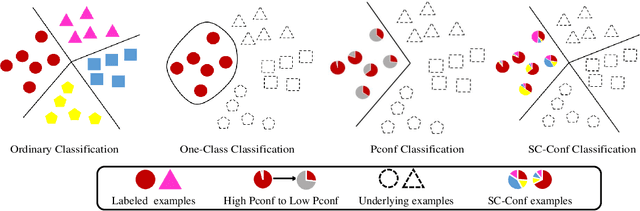


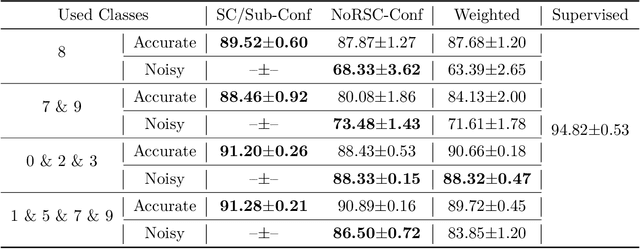
Can we learn a multi-class classifier from only data of a single class? We show that without any assumptions on the loss functions, models, and optimizers, we can successfully learn a multi-class classifier from only data of a single class with a rigorous consistency guarantee when confidences (i.e., the class-posterior probabilities for all the classes) are available. Specifically, we propose an empirical risk minimization framework that is loss-/model-/optimizer-independent. Instead of constructing a boundary between the given class and other classes, our method can conduct discriminative classification between all the classes even if no data from the other classes are provided. We further theoretically and experimentally show that our method can be Bayes-consistent with a simple modification even if the provided confidences are highly noisy. Then, we provide an extension of our method for the case where data from a subset of all the classes are available. Experimental results demonstrate the effectiveness of our methods.
Learning from Similarity-Confidence Data
Feb 13, 2021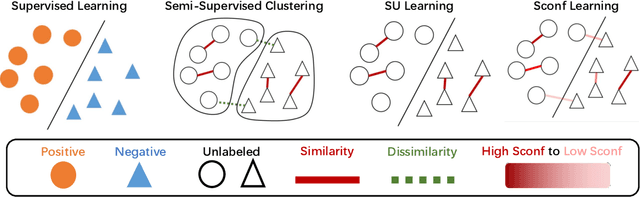

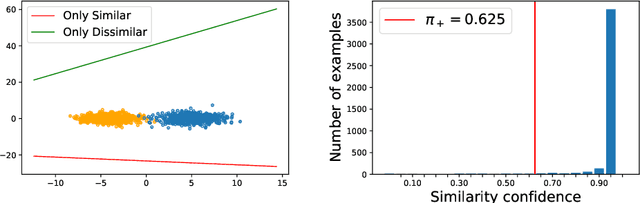
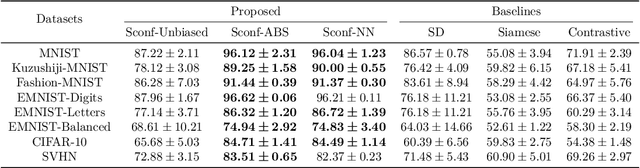
Weakly supervised learning has drawn considerable attention recently to reduce the expensive time and labor consumption of labeling massive data. In this paper, we investigate a novel weakly supervised learning problem of learning from similarity-confidence (Sconf) data, where we aim to learn an effective binary classifier from only unlabeled data pairs equipped with confidence that illustrates their degree of similarity (two examples are similar if they belong to the same class). To solve this problem, we propose an unbiased estimator of the classification risk that can be calculated from only Sconf data and show that the estimation error bound achieves the optimal convergence rate. To alleviate potential overfitting when flexible models are used, we further employ a risk correction scheme on the proposed risk estimator. Experimental results demonstrate the effectiveness of the proposed methods.
Multi-Complementary and Unlabeled Learning for Arbitrary Losses and Models
Jan 26, 2020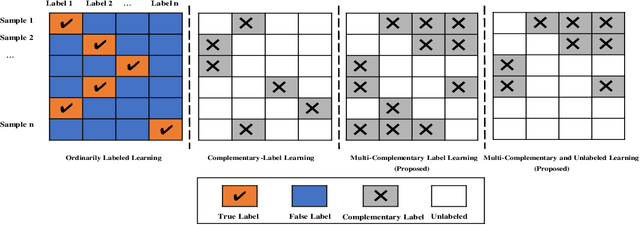


A weakly-supervised learning framework named as complementary-label learning has been proposed recently, where each sample is equipped with a single complementary label that denotes one of the classes the sample does not belong to. However, the existing complementary-label learning methods cannot learn from the easily accessible unlabeled samples and samples with multiple complementary labels, which are more informative. In this paper, to remove these limitations, we propose the novel multi-complementary and unlabeled learning framework that allows unbiased estimation of classification risk from samples with any number of complementary labels and unlabeled samples, for arbitrary loss functions and models. We first give an unbiased estimator of the classification risk from samples with multiple complementary labels, and then further improve the estimator by incorporating unlabeled samples into the risk formulation. The estimation error bounds show that the proposed methods are in the optimal parametric convergence rate. Finally, the experiments on both linear and deep models show the effectiveness of our methods.