 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Safe Screening Rule with Bi-level Optimization of $ν$ Support Vector Machine
Paper and Code
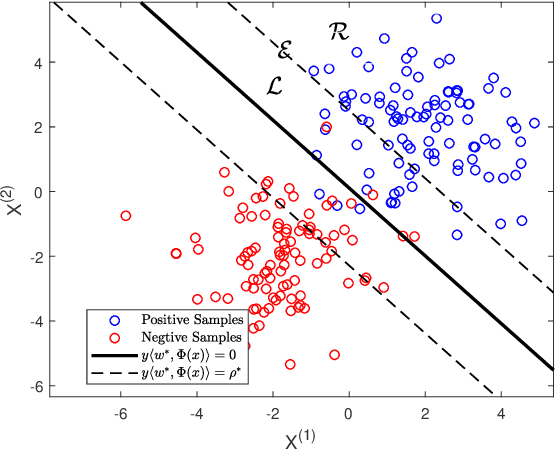
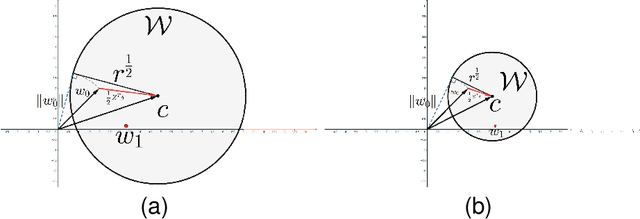
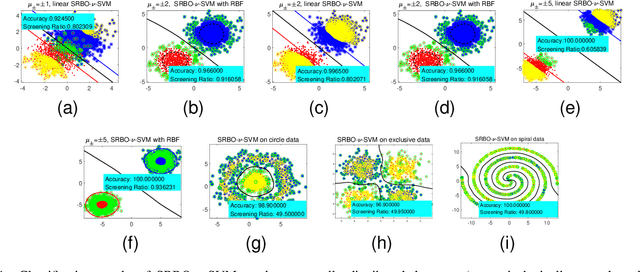
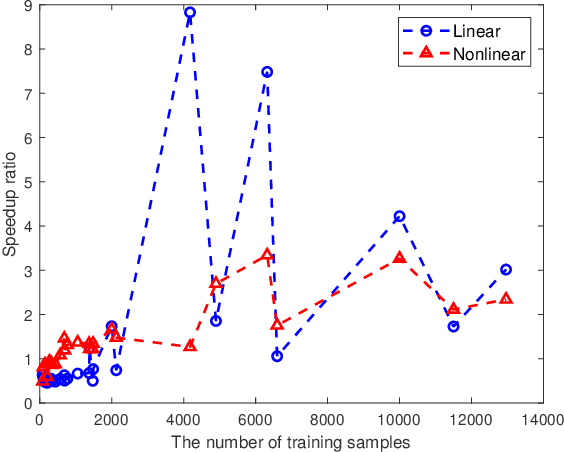
Support vector machine (SVM) has achieved many successes in machine learning, especially for a small sample problem. As a famous extension of the traditional SVM, the $\nu$ support vector machine ($\nu$-SVM) has shown outstanding performance due to its great model interpretability. However, it still faces challenges in training overhead for large-scale problems. To address this issue, we propose a safe screening rule with bi-level optimization for $\nu$-SVM (SRBO-$\nu$-SVM) which can screen out inactive samples before training and reduce the computational cost without sacrificing the prediction accuracy. Our SRBO-$\nu$-SVM is strictly deduced by integrating the Karush-Kuhn-Tucker (KKT) conditions, the variational inequalities of convex problems and the $\nu$-property. Furthermore, we develop an efficient dual coordinate descent method (DCDM) to further improve computational speed. Finally, a unified framework for SRBO is proposed to accelerate many SVM-type models, and it is successfully applied to one-class SVM. Experimental results on 6 artificial data sets and 30 benchmark data sets have verified the effectiveness and safety of our proposed methods in supervised and unsupervised tasks.