 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-PROM: A Benchmark for Visual Reasoning Using Visual Progressive Matrices
Paper and Code
Jul 29, 2019


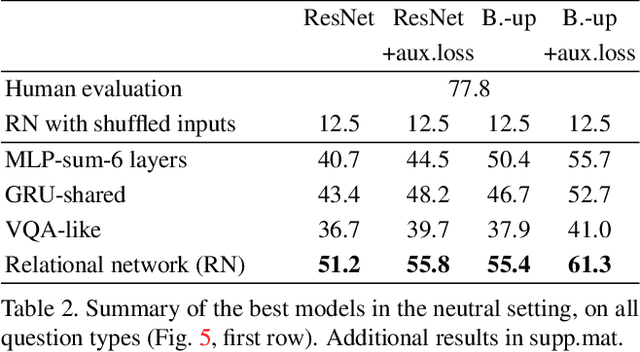
One of the primary challenges faced by deep learning is the degree to which current methods exploit superficial statistics and dataset bias, rather than learning to generalise over the specific representations they have experienced. This is a critical concern because generalisation enables robust reasoning over unseen data, whereas leveraging superficial statistics is fragile to even small changes in data distribution. To illuminate the issue and drive progress towards a solution, we propose a test that explicitly evaluates abstract reasoning over visual data. We introduce a large-scale benchmark of visual questions that involve operations fundamental to many high-level vision tasks, such as comparisons of counts and logical operations on complex visual properties. The benchmark directly measures a method's ability to infer high-level relationships and to generalise them over image-based concepts. It includes multiple training/test splits that require controlled levels of generalization. We evaluate a range of deep learning architectures, and find that existing models, including those popular for vision-and-language tasks, are unable to solve seemingly-simple instances. Models using relational networks fare better but leave substantial room for improvement.