 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTT-VLA: Test-Time Latent Prompt Optimization for Vision-Language-Action Models
Jun 02, 2026Vision-Language-Action (VLA) models trained on large-scale data have made remarkable progress, but they remain vulnerable to distribution shifts at deployment time. Recent VLA models suggest that prompts can serve as an efficient interface for steering policy behavior, but existing prompt-based steering typically relies on external guidance. This raises a natural question: can test-time training (TTT) for VLA be achieved by optimizing a prompt, so that the steering interface itself can be learned and adapted from interaction? We address this question with TTT-VLA, a test-time training framework based on Latent Prompt Optimization (LPO). During training, the latent prompt is learned with an additional proxy task, providing an extra learned conditioning signal for policy learning. At test time, TTT is performed by collecting interaction data from the current environment and optimizing only the latent prompt on those data using the proxy task's self-supervised signal, without modifying the policy itself. Experiments on SimplerEnv demonstrate that the proposed method consistently improves task success rates in both single- and multi-embodiment settings. Further analysis shows that the gains arise primarily from correcting a small number of critical decisions rather than globally altering policy behavior. These results suggest that LPO provides an effective and practical pathway for deployment-time improvement of foundation manipulation policies.
STRIDE: Training-Free Diversity Guidance via PCA-Directed Feature Perturbation in Single-Step Diffusion Models
May 12, 2026Distilled one-step (T=1) or few-step (T$\leq$4) diffusion models enable real-time image generation but often exhibit reduced sample diversity compared to their multi-step counterparts. In multi-step diffusion, diversity can be introduced through schedules, trajectories, or iterative optimization; however, these mechanisms are unavailable in the few-step or single-step setting, limiting the effectiveness of existing diversity-enhancing methods. A natural alternative is to perturb intermediate features, but naive feature perturbation is often ineffective, either yielding limited diversity gains or degrading generation quality. We argue that effective diversity injection in few-step models requires perturbations that respect the model's learned feature geometry. Based on this insight, we propose STRIDE, a training-free and optimization-free method that operates in a single forward pass. STRIDE injects spatially coherent (pink) noise into intermediate transformer features, projected onto the principal components of the model's own activations, ensuring that perturbations lie on the learned feature manifold. This design enables controlled variation along meaningful directions in the representation space. Extensive experiments on FLUX.1-schnell and SD3.5 Turbo across COCO, DrawBench, PartiPrompts, and GenEval show that STRIDE consistently improves diversity while maintaining strong text alignment. In particular, STRIDE reduces intra-batch similarity with minimal impact on CLIP score, and Pareto-dominates existing training-free baselines on the diversity-fidelity frontier. These results highlight that, in the absence of iterative refinement, improving diversity in few-step and one-step diffusion depends not on increasing perturbation strength, but on aligning perturbations with the model's internal representation structure.
Learning Feature Encoder with Synthetic Anomalies for Weakly Supervised Graph Anomaly Detection
May 12, 2026Weakly supervised graph anomaly detection aims to unveil unusual graph instances, e.g., nodes, whose behaviors significantly differ from normal ones, given only a limited number of annotated anomalies and abundant unlabeled samples. A major challenge is to learn a meaningful latent feature representation that reduces intra-class variance among normal data while remaining highly sensitive to anomalies. Although recent works have applied self-supervised feature learning for graph anomaly detection, their strategies are not specifically tailored to its unique requirements, motivating our exploration of a more domain-specific approach. In this paper, we introduce a weakly supervised graph anomaly detection method that leverages a feature learning strategy tailored for graph anomalies. Our approach is built upon a multi-task learning scheme that extracts robust feature representations through synthesized anomalies. We generate synthetic anomalies by perturbing the normal graph in various ways and assign a dedicated detection head to each anomaly type, ensuring that learned features are sensitive to potential deviations from normal patterns. Although synthetic anomalies may not perfectly replicate real-world patterns, they provide valuable auxiliary data for effective feature learnin, much like features learned from ImageNet classification transfer to downstream vision tasks. Additionally, we adopt a two-phase learning strategy: an initial warm-up phase using only synthetic samples, followed by a full-training phase integrating both tasks, to balance the influence of synthetic and real data. Extensive experiments on public datasets demonstrate the superior performance of our method over its competitors. Code is available at https://github.com/yj-zhou/SAWGAD.
* 14 pages, 7 figures, published by IEEE Transactions on Knowledge and Data Engineering,2026
Training-Free Instance-Aware 3D Scene Reconstruction and Diffusion-Based View Synthesis from Sparse Images
Mar 22, 2026We introduce a novel, training-free system for reconstructing, understanding, and rendering 3D indoor scenes from a sparse set of unposed RGB images. Unlike traditional radiance field approaches that require dense views and per-scene optimization, our pipeline achieves high-fidelity results without any training or pose preprocessing. The system integrates three key innovations: (1) A robust point cloud reconstruction module that filters unreliable geometry using a warping-based anomaly removal strategy; (2) A warping-guided 2D-to-3D instance lifting mechanism that propagates 2D segmentation masks into a consistent, instance-aware 3D representation; and (3) A novel rendering approach that projects the point cloud into new views and refines the renderings with a 3D-aware diffusion model. Our method leverages the generative power of diffusion to compensate for missing geometry and enhances realism, especially under sparse input conditions. We further demonstrate that object-level scene editing such as instance removal can be naturally supported in our pipeline by modifying only the point cloud, enabling the synthesis of consistent, edited views without retraining. Our results establish a new direction for efficient, editable 3D content generation without relying on scene-specific optimization. Project page: https://jiatongxia.github.io/TID3R/
Points-to-3D: Structure-Aware 3D Generation with Point Cloud Priors
Mar 19, 2026Recent progress in 3D generation has been driven largely by models conditioned on images or text, while readily available 3D priors are still underused. In many real-world scenarios, the visible-region point cloud are easy to obtain from active sensors such as LiDAR or from feed-forward predictors like VGGT, offering explicit geometric constraints that current methods fail to exploit. In this work, we introduce Points-to-3D, a diffusion-based framework that leverages point cloud priors for geometry-controllable 3D asset and scene generation. Built on a latent 3D diffusion model TRELLIS, Points-to-3D first replaces pure-noise sparse structure latent initialization with a point cloud priors tailored input formulation.A structure inpainting network, trained within the TRELLIS framework on task-specific data designed to learn global structural inpainting, is then used for inference with a staged sampling strategy (structural inpainting followed by boundary refinement), completing the global geometry while preserving the visible regions of the input priors.In practice, Points-to-3D can take either accurate point-cloud priors or VGGT-estimated point clouds from single images as input. Experiments on both objects and scene scenarios consistently demonstrate superior performance over state-of-the-art baselines in terms of rendering quality and geometric fidelity, highlighting the effectiveness of explicitly embedding point-cloud priors for achieving more accurate and structurally controllable 3D generation.
EMAG: Self-Rectifying Diffusion Sampling with Exponential Moving Average Guidance
Dec 19, 2025
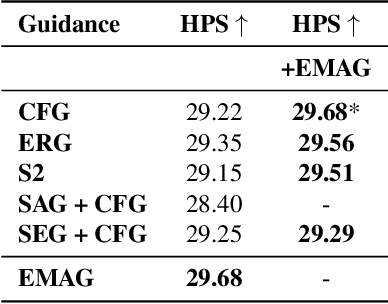

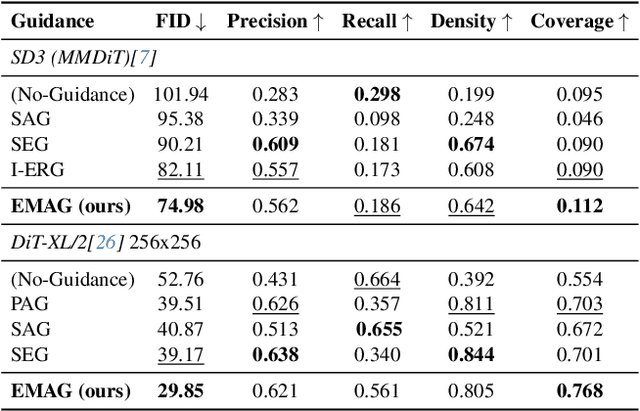
In diffusion and flow-matching generative models, guidance techniques are widely used to improve sample quality and consistency. Classifier-free guidance (CFG) is the de facto choice in modern systems and achieves this by contrasting conditional and unconditional samples. Recent work explores contrasting negative samples at inference using a weaker model, via strong/weak model pairs, attention-based masking, stochastic block dropping, or perturbations to the self-attention energy landscape. While these strategies refine the generation quality, they still lack reliable control over the granularity or difficulty of the negative samples, and target-layer selection is often fixed. We propose Exponential Moving Average Guidance (EMAG), a training-free mechanism that modifies attention at inference time in diffusion transformers, with a statistics-based, adaptive layer-selection rule. Unlike prior methods, EMAG produces harder, semantically faithful negatives (fine-grained degradations), surfacing difficult failure modes, enabling the denoiser to refine subtle artifacts, boosting the quality and human preference score (HPS) by +0.46 over CFG. We further demonstrate that EMAG naturally composes with advanced guidance techniques, such as APG and CADS, further improving HPS.
A Review of Longitudinal Radiology Report Generation: Dataset Composition, Methods, and Performance Evaluation
Oct 14, 2025Chest Xray imaging is a widely used diagnostic tool in modern medicine, and its high utilization creates substantial workloads for radiologists. To alleviate this burden, vision language models are increasingly applied to automate Chest Xray radiology report generation (CXRRRG), aiming for clinically accurate descriptions while reducing manual effort. Conventional approaches, however, typically rely on single images, failing to capture the longitudinal context necessary for producing clinically faithful comparison statements. Recently, growing attention has been directed toward incorporating longitudinal data into CXR RRG, enabling models to leverage historical studies in ways that mirror radiologists diagnostic workflows. Nevertheless, existing surveys primarily address single image CXRRRG and offer limited guidance for longitudinal settings, leaving researchers without a systematic framework for model design. To address this gap, this survey provides the first comprehensive review of longitudinal radiology report generation (LRRG). Specifically, we examine dataset construction strategies, report generation architectures alongside longitudinally tailored designs, and evaluation protocols encompassing both longitudinal specific measures and widely used benchmarks. We further summarize LRRG methods performance, alongside analyses of different ablation studies, which collectively highlight the critical role of longitudinal information and architectural design choices in improving model performance. Finally, we summarize five major limitations of current research and outline promising directions for future development, aiming to lay a foundation for advancing this emerging field.
Let Your Video Listen to Your Music!
Jun 23, 2025Aligning the rhythm of visual motion in a video with a given music track is a practical need in multimedia production, yet remains an underexplored task in autonomous video editing. Effective alignment between motion and musical beats enhances viewer engagement and visual appeal, particularly in music videos, promotional content, and cinematic editing. Existing methods typically depend on labor-intensive manual cutting, speed adjustments, or heuristic-based editing techniques to achieve synchronization. While some generative models handle joint video and music generation, they often entangle the two modalities, limiting flexibility in aligning video to music beats while preserving the full visual content. In this paper, we propose a novel and efficient framework, termed MVAA (Music-Video Auto-Alignment), that automatically edits video to align with the rhythm of a given music track while preserving the original visual content. To enhance flexibility, we modularize the task into a two-step process in our MVAA: aligning motion keyframes with audio beats, followed by rhythm-aware video inpainting. Specifically, we first insert keyframes at timestamps aligned with musical beats, then use a frame-conditioned diffusion model to generate coherent intermediate frames, preserving the original video's semantic content. Since comprehensive test-time training can be time-consuming, we adopt a two-stage strategy: pretraining the inpainting module on a small video set to learn general motion priors, followed by rapid inference-time fine-tuning for video-specific adaptation. This hybrid approach enables adaptation within 10 minutes with one epoch on a single NVIDIA 4090 GPU using CogVideoX-5b-I2V as the backbone. Extensive experiments show that our approach can achieve high-quality beat alignment and visual smoothness.
Chain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation
Jun 11, 2025We present Chain-of-Action (CoA), a novel visuo-motor policy paradigm built upon Trajectory Autoregressive Modeling. Unlike conventional approaches that predict next step action(s) forward, CoA generates an entire trajectory by explicit backward reasoning with task-specific goals through an action-level Chain-of-Thought (CoT) process. This process is unified within a single autoregressive structure: (1) the first token corresponds to a stable keyframe action that encodes the task-specific goals; and (2) subsequent action tokens are generated autoregressively, conditioned on the initial keyframe and previously predicted actions. This backward action reasoning enforces a global-to-local structure, allowing each local action to be tightly constrained by the final goal. To further realize the action reasoning structure, CoA incorporates four complementary designs: continuous action token representation; dynamic stopping for variable-length trajectory generation; reverse temporal ensemble; and multi-token prediction to balance action chunk modeling with global structure. As a result, CoA gives strong spatial generalization capabilities while preserving the flexibility and simplicity of a visuo-motor policy. Empirically, we observe CoA achieves the state-of-the-art performance across 60 RLBench tasks and 8 real-world manipulation tasks.
Enhancing Close-up Novel View Synthesis via Pseudo-labeling
Mar 20, 2025Recent methods, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS), have demonstrated remarkable capabilities in novel view synthesis. However, despite their success in producing high-quality images for viewpoints similar to those seen during training, they struggle when generating detailed images from viewpoints that significantly deviate from the training set, particularly in close-up views. The primary challenge stems from the lack of specific training data for close-up views, leading to the inability of current methods to render these views accurately. To address this issue, we introduce a novel pseudo-label-based learning strategy. This approach leverages pseudo-labels derived from existing training data to provide targeted supervision across a wide range of close-up viewpoints. Recognizing the absence of benchmarks for this specific challenge, we also present a new dataset designed to assess the effectiveness of both current and future methods in this area. Our extensive experiments demonstrate the efficacy of our approach.