 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Longitudinal Radiology Report Generation: Dataset Composition, Methods, and Performance Evaluation
Oct 14, 2025Chest Xray imaging is a widely used diagnostic tool in modern medicine, and its high utilization creates substantial workloads for radiologists. To alleviate this burden, vision language models are increasingly applied to automate Chest Xray radiology report generation (CXRRRG), aiming for clinically accurate descriptions while reducing manual effort. Conventional approaches, however, typically rely on single images, failing to capture the longitudinal context necessary for producing clinically faithful comparison statements. Recently, growing attention has been directed toward incorporating longitudinal data into CXR RRG, enabling models to leverage historical studies in ways that mirror radiologists diagnostic workflows. Nevertheless, existing surveys primarily address single image CXRRRG and offer limited guidance for longitudinal settings, leaving researchers without a systematic framework for model design. To address this gap, this survey provides the first comprehensive review of longitudinal radiology report generation (LRRG). Specifically, we examine dataset construction strategies, report generation architectures alongside longitudinally tailored designs, and evaluation protocols encompassing both longitudinal specific measures and widely used benchmarks. We further summarize LRRG methods performance, alongside analyses of different ablation studies, which collectively highlight the critical role of longitudinal information and architectural design choices in improving model performance. Finally, we summarize five major limitations of current research and outline promising directions for future development, aiming to lay a foundation for advancing this emerging field.
Multi-Aggregator Time-Warping Heterogeneous Graph Neural Network for Personalized Micro-Video Recommendation
Jan 05, 2025



Micro-video recommendation is attracting global attention and becoming a popular daily service for people of all ages. Recently, Graph Neural Networks-based micro-video recommendation has displayed performance improvement for many kinds of recommendation tasks. However, the existing works fail to fully consider the characteristics of micro-videos, such as the high timeliness of news nature micro-video recommendation and sequential interactions of frequently changed interests. In this paper, a novel Multi-aggregator Time-warping Heterogeneous Graph Neural Network (MTHGNN) is proposed for personalized news nature micro-video recommendation based on sequential sessions, where characteristics of micro-videos are comprehensively studied, users' preference is mined via multi-aggregator, the temporal and dynamic changes of users' preference are captured, and timeliness is considered. Through the comparison with the state-of-the-arts, the experimental results validate the superiority of our MTHGNN model.
Quantum Cognition-Inspired EEG-based Recommendation via Graph Neural Networks
Jan 05, 2025



Current recommendation systems recommend goods by considering users' historical behaviors, social relations, ratings, and other multi-modals. Although outdated user information presents the trends of a user's interests, no recommendation system can know the users' real-time thoughts indeed. With the development of brain-computer interfaces, it is time to explore next-generation recommenders that show users' real-time thoughts without delay. Electroencephalography (EEG) is a promising method of collecting brain signals because of its convenience and mobility. Currently, there is only few research on EEG-based recommendations due to the complexity of learning human brain activity. To explore the utility of EEG-based recommendation, we propose a novel neural network model, QUARK, combining Quantum Cognition Theory and Graph Convolutional Networks for accurate item recommendations. Compared with the state-of-the-art recommendation models, the superiority of QUARK is confirmed via extensive experiments.
ER2Score: LLM-based Explainable and Customizable Metric for Assessing Radiology Reports with Reward-Control Loss
Nov 26, 2024



Automated radiology report generation (R2Gen) has advanced significantly, introducing challenges in accurate evaluation due to its complexity. Traditional metrics often fall short by relying on rigid word-matching or focusing only on pathological entities, leading to inconsistencies with human assessments. To bridge this gap, we introduce ER2Score, an automatic evaluation metric designed specifically for R2Gen. Our metric utilizes a reward model, guided by our margin-based reward enforcement loss, along with a tailored training data design that enables customization of evaluation criteria to suit user-defined needs. It not only scores reports according to user-specified criteria but also provides detailed sub-scores, enhancing interpretability and allowing users to adjust the criteria between different aspects of reports. Leveraging GPT-4, we designed an easy-to-use data generation pipeline, enabling us to produce extensive training data based on two distinct scoring systems, each containing reports of varying quality along with corresponding scores. These GPT-generated reports are then paired as accepted and rejected samples through our pairing rule to train an LLM towards our fine-grained reward model, which assigns higher rewards to the report with high quality. Our reward-control loss enables this model to simultaneously output multiple individual rewards corresponding to the number of evaluation criteria, with their summation as our final ER2Score. Our experiments demonstrate ER2Score's heightened correlation with human judgments and superior performance in model selection compared to traditional metrics. Notably, our model provides both an overall score and individual scores for each evaluation item, enhancing interpretability. We also demonstrate its flexible training across various evaluation systems.
KARGEN: Knowledge-enhanced Automated Radiology Report Generation Using Large Language Models
Sep 09, 2024



Harnessing the robust capabilities of Large Language Models (LLMs) for narrative generation, logical reasoning, and common-sense knowledge integration, this study delves into utilizing LLMs to enhance automated radiology report generation (R2Gen). Despite the wealth of knowledge within LLMs, efficiently triggering relevant knowledge within these large models for specific tasks like R2Gen poses a critical research challenge. This paper presents KARGEN, a Knowledge-enhanced Automated radiology Report GENeration framework based on LLMs. Utilizing a frozen LLM to generate reports, the framework integrates a knowledge graph to unlock chest disease-related knowledge within the LLM to enhance the clinical utility of generated reports. This is achieved by leveraging the knowledge graph to distill disease-related features in a designed way. Since a radiology report encompasses both normal and disease-related findings, the extracted graph-enhanced disease-related features are integrated with regional image features, attending to both aspects. We explore two fusion methods to automatically prioritize and select the most relevant features. The fused features are employed by LLM to generate reports that are more sensitive to diseases and of improved quality. Our approach demonstrates promising results on the MIMIC-CXR and IU-Xray datasets.
MRScore: Evaluating Radiology Report Generation with LLM-based Reward System
Apr 27, 2024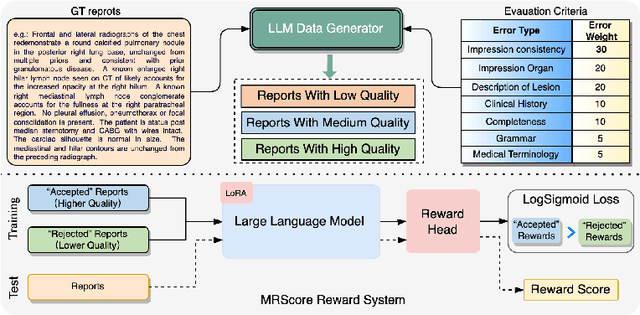
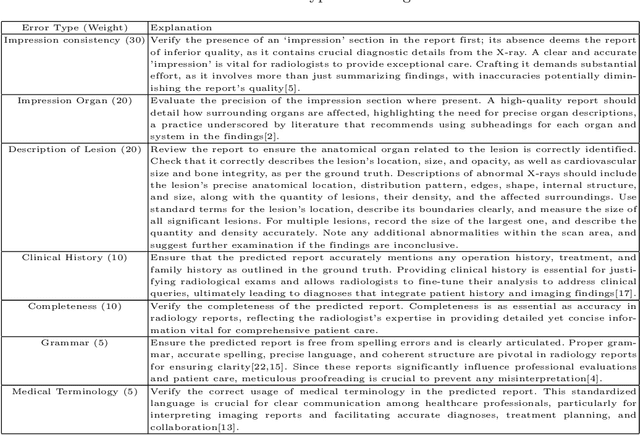
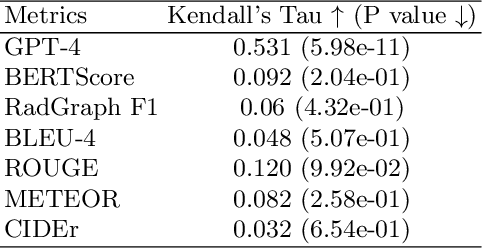
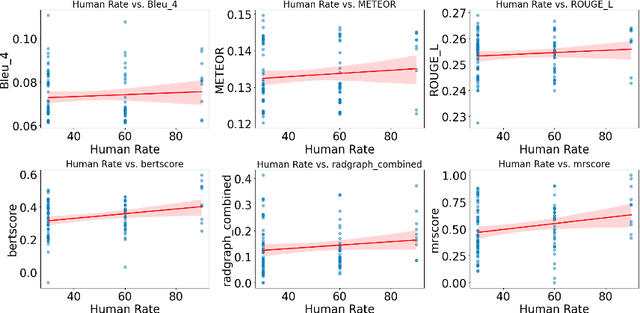
In recent years, automated radiology report generation has experienced significant growth. This paper introduces MRScore, an automatic evaluation metric tailored for radiology report generation by leveraging Large Language Models (LLMs). Conventional NLG (natural language generation) metrics like BLEU are inadequate for accurately assessing the generated radiology reports, as systematically demonstrated by our observations within this paper. To address this challenge, we collaborated with radiologists to develop a framework that guides LLMs for radiology report evaluation, ensuring alignment with human analysis. Our framework includes two key components: i) utilizing GPT to generate large amounts of training data, i.e., reports with different qualities, and ii) pairing GPT-generated reports as accepted and rejected samples and training LLMs to produce MRScore as the model reward. Our experiments demonstrate MRScore's higher correlation with human judgments and superior performance in model selection compared to traditional metrics. Our code and datasets will be available on GitHub.
Security Risks Concerns of Generative AI in the IoT
Mar 29, 2024In an era where the Internet of Things (IoT) intersects increasingly with generative Artificial Intelligence (AI), this article scrutinizes the emergent security risks inherent in this integration. We explore how generative AI drives innovation in IoT and we analyze the potential for data breaches when using generative AI and the misuse of generative AI technologies in IoT ecosystems. These risks not only threaten the privacy and efficiency of IoT systems but also pose broader implications for trust and safety in AI-driven environments. The discussion in this article extends to strategic approaches for mitigating these risks, including the development of robust security protocols, the multi-layered security approaches, and the adoption of AI technological solutions. Through a comprehensive analysis, this article aims to shed light on the critical balance between embracing AI advancements and ensuring stringent security in IoT, providing insights into the future direction of these intertwined technologies.
A Comprehensive Study of GPT-4V's Multimodal Capabilities in Medical Imaging
Nov 06, 2023This paper presents a comprehensive evaluation of GPT-4V's capabilities across diverse medical imaging tasks, including Radiology Report Generation, Medical Visual Question Answering (VQA), and Visual Grounding. While prior efforts have explored GPT-4V's performance in medical image analysis, to the best of our knowledge, our study represents the first quantitative evaluation on publicly available benchmarks. Our findings highlight GPT-4V's potential in generating descriptive reports for chest X-ray images, particularly when guided by well-structured prompts. Meanwhile, its performance on the MIMIC-CXR dataset benchmark reveals areas for improvement in certain evaluation metrics, such as CIDEr. In the domain of Medical VQA, GPT-4V demonstrates proficiency in distinguishing between question types but falls short of the VQA-RAD benchmark in terms of accuracy. Furthermore, our analysis finds the limitations of conventional evaluation metrics like the BLEU scores, advocating for the development of more semantically robust assessment methods. In the field of Visual Grounding, GPT-4V exhibits preliminary promise in recognizing bounding boxes, but its precision is lacking, especially in identifying specific medical organs and signs. Our evaluation underscores the significant potential of GPT-4V in the medical imaging domain, while also emphasizing the need for targeted refinements to fully unlock its capabilities.
Real-time Interface Control with Motion Gesture Recognition based on Non-contact Capacitive Sensing
Jan 05, 2022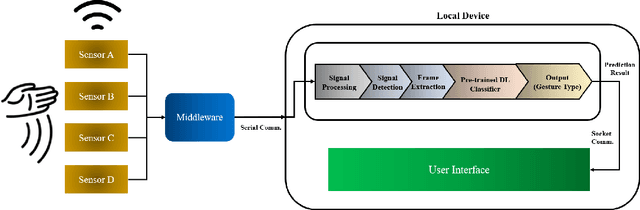
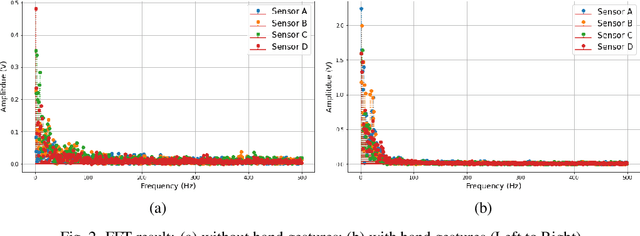
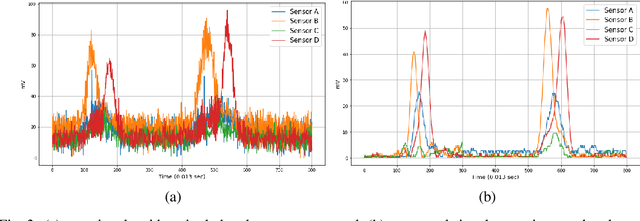
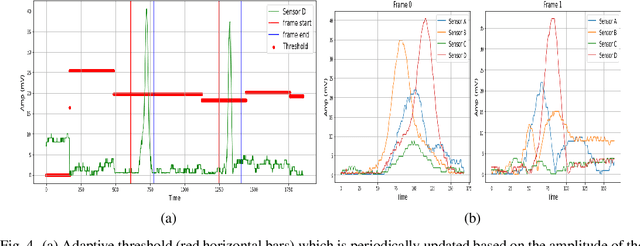
Capacitive sensing is a prominent technology that is cost-effective and low power consuming with fast recognition speed compared to existing sensing systems. On account of these advantages, Capacitive sensing has been widely studied and commercialized in the domains of touch sensing, localization, existence detection, and contact sensing interface application such as human-computer interaction. However, as a non-contact proximity sensing scheme is easily affected by the disturbance of peripheral objects or surroundings, it requires considerable sensitive data processing than contact sensing, limiting the use of its further utilization. In this paper, we propose a real-time interface control framework based on non-contact hand motion gesture recognition through processing the raw signals, detecting the electric field disturbance triggered by the hand gesture movements near the capacitive sensor using adaptive threshold, and extracting the significant signal frame, covering the authentic signal intervals with 98.8% detection rate and 98.4% frame correction rate. Through the GRU model trained with the extracted signal frame, we classify the 10 hand motion gesture types with 98.79% accuracy. The framework transmits the classification result and maneuvers the interface of the foreground process depending on the input. This study suggests the feasibility of intuitive interface technology, which accommodates the flexible interaction between human to machine similar to Natural User Interface, and uplifts the possibility of commercialization based on measuring the electric field disturbance through non-contact proximity sensing which is state-of-the-art sensing technology.
Robust Convergence in Federated Learning through Label-wise Clustering
Dec 28, 2021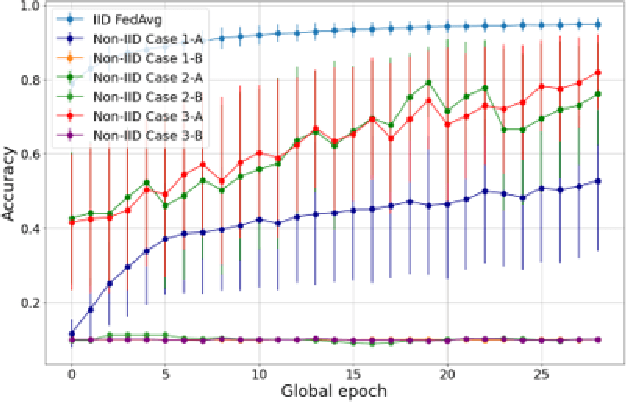
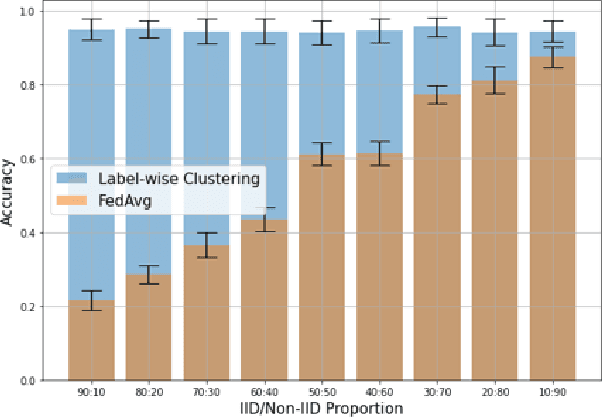
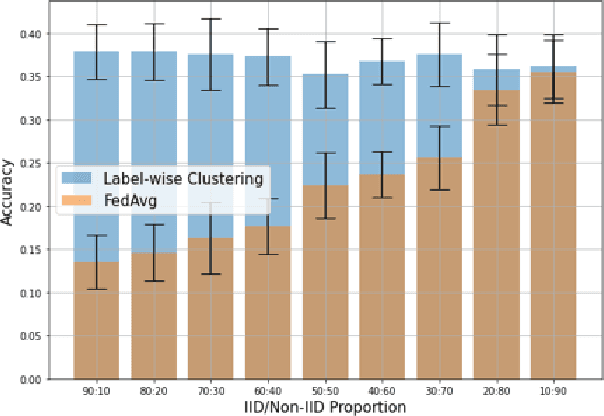
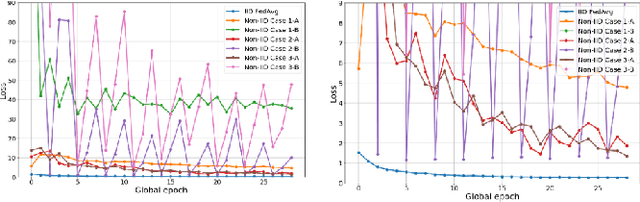
Non-IID dataset and heterogeneous environment of the local clients are regarded as a major issue in Federated Learning (FL), causing a downturn in the convergence without achieving satisfactory performance. In this paper, we propose a novel Label-wise clustering algorithm that guarantees the trainability among geographically dispersed heterogeneous local clients, by selecting only the local models trained with a dataset that approximates into uniformly distributed class labels, which is likely to obtain faster minimization of the loss and increment the accuracy among the FL network. Through conducting experiments on the suggested six common non-IID scenarios, we empirically show that the vanilla FL aggregation model is incapable of gaining robust convergence generating biased pre-trained local models and drifting the local weights to mislead the trainability in the worst case. Moreover, we quantitatively estimate the expected performance of the local models before training, which offers a global server to select the optimal clients, saving additional computational costs. Ultimately, in order to gain resolution of the non-convergence in such non-IID situations, we design clustering algorithms based on local input class labels, accommodating the diversity and assorting clients that could lead the overall system to attain the swift convergence as global training continues. Our paper shows that proposed Label-wise clustering demonstrates prompt and robust convergence compared to other FL algorithms when local training datasets are non-IID or coexist with IID through multiple experiments.