 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaccinating Federated Learning for Robust Modulation Classification in Distributed Wireless Networks
Oct 16, 2024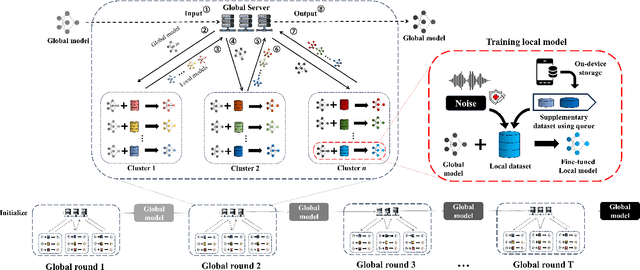
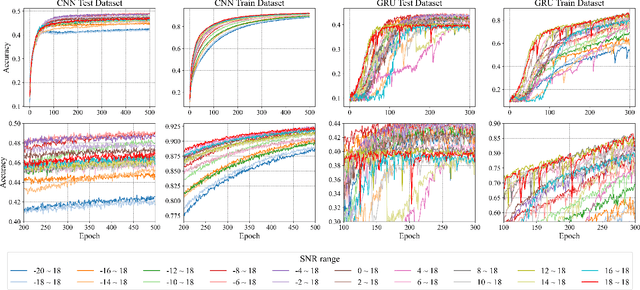
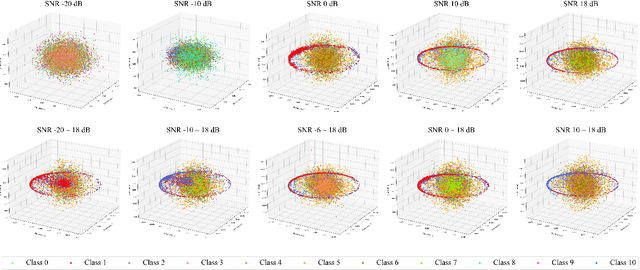
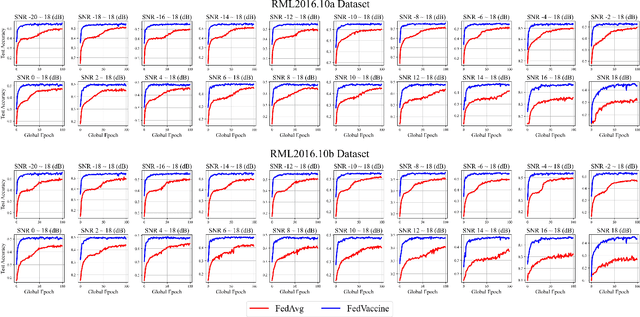
Automatic modulation classification (AMC) serves a vital role in ensuring efficient and reliable communication services within distributed wireless networks. Recent developments have seen a surge in interest in deep neural network (DNN)-based AMC models, with Federated Learning (FL) emerging as a promising framework. Despite these advancements, the presence of various noises within the signal exerts significant challenges while optimizing models to capture salient features. Furthermore, existing FL-based AMC models commonly rely on linear aggregation strategies, which face notable difficulties in integrating locally fine-tuned parameters within practical non-IID (Independent and Identically Distributed) environments, thereby hindering optimal learning convergence. To address these challenges, we propose FedVaccine, a novel FL model aimed at improving generalizability across signals with varying noise levels by deliberately introducing a balanced level of noise. This is accomplished through our proposed harmonic noise resilience approach, which identifies an optimal noise tolerance for DNN models, thereby regulating the training process and mitigating overfitting. Additionally, FedVaccine overcomes the limitations of existing FL-based AMC models' linear aggregation by employing a split-learning strategy using structural clustering topology and local queue data structure, enabling adaptive and cumulative updates to local models. Our experimental results, including IID and non-IID datasets as well as ablation studies, confirm FedVaccine's robust performance and superiority over existing FL-based AMC approaches across different noise levels. These findings highlight FedVaccine's potential to enhance the reliability and performance of AMC systems in practical wireless network environments.
drGAT: Attention-Guided Gene Assessment of Drug Response Utilizing a Drug-Cell-Gene Heterogeneous Network
May 14, 2024



Drug development is a lengthy process with a high failure rate. Increasingly, machine learning is utilized to facilitate the drug development processes. These models aim to enhance our understanding of drug characteristics, including their activity in biological contexts. However, a major challenge in drug response (DR) prediction is model interpretability as it aids in the validation of findings. This is important in biomedicine, where models need to be understandable in comparison with established knowledge of drug interactions with proteins. drGAT, a graph deep learning model, leverages a heterogeneous graph composed of relationships between proteins, cell lines, and drugs. drGAT is designed with two objectives: DR prediction as a binary sensitivity prediction and elucidation of drug mechanism from attention coefficients. drGAT has demonstrated superior performance over existing models, achieving 78\% accuracy (and precision), and 76\% F1 score for 269 DNA-damaging compounds of the NCI60 drug response dataset. To assess the model's interpretability, we conducted a review of drug-gene co-occurrences in Pubmed abstracts in comparison to the top 5 genes with the highest attention coefficients for each drug. We also examined whether known relationships were retained in the model by inspecting the neighborhoods of topoisomerase-related drugs. For example, our model retained TOP1 as a highly weighted predictive feature for irinotecan and topotecan, in addition to other genes that could potentially be regulators of the drugs. Our method can be used to accurately predict sensitivity to drugs and may be useful in the identification of biomarkers relating to the treatment of cancer patients.
Real-time Interface Control with Motion Gesture Recognition based on Non-contact Capacitive Sensing
Jan 05, 2022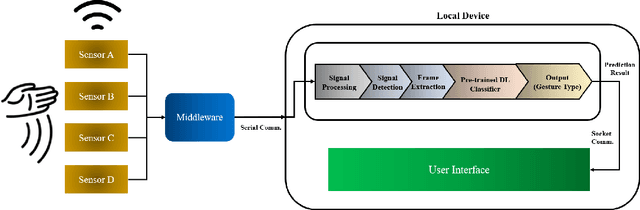
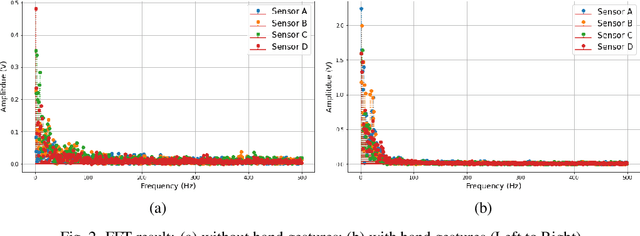
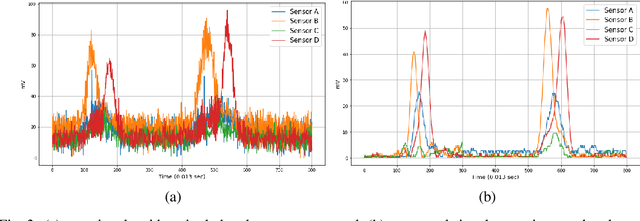
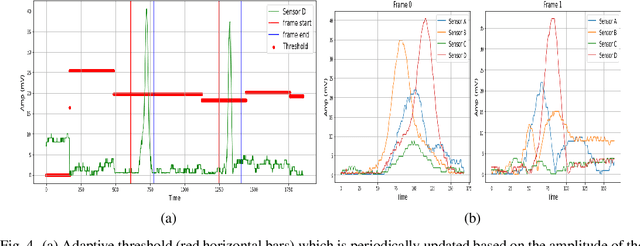
Capacitive sensing is a prominent technology that is cost-effective and low power consuming with fast recognition speed compared to existing sensing systems. On account of these advantages, Capacitive sensing has been widely studied and commercialized in the domains of touch sensing, localization, existence detection, and contact sensing interface application such as human-computer interaction. However, as a non-contact proximity sensing scheme is easily affected by the disturbance of peripheral objects or surroundings, it requires considerable sensitive data processing than contact sensing, limiting the use of its further utilization. In this paper, we propose a real-time interface control framework based on non-contact hand motion gesture recognition through processing the raw signals, detecting the electric field disturbance triggered by the hand gesture movements near the capacitive sensor using adaptive threshold, and extracting the significant signal frame, covering the authentic signal intervals with 98.8% detection rate and 98.4% frame correction rate. Through the GRU model trained with the extracted signal frame, we classify the 10 hand motion gesture types with 98.79% accuracy. The framework transmits the classification result and maneuvers the interface of the foreground process depending on the input. This study suggests the feasibility of intuitive interface technology, which accommodates the flexible interaction between human to machine similar to Natural User Interface, and uplifts the possibility of commercialization based on measuring the electric field disturbance through non-contact proximity sensing which is state-of-the-art sensing technology.
An Attention Score Based Attacker for Black-box NLP Classifier
Jan 01, 2022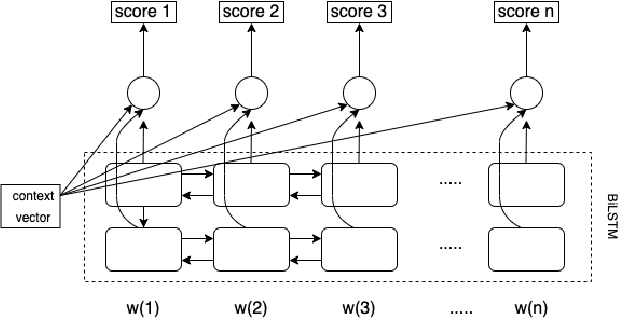
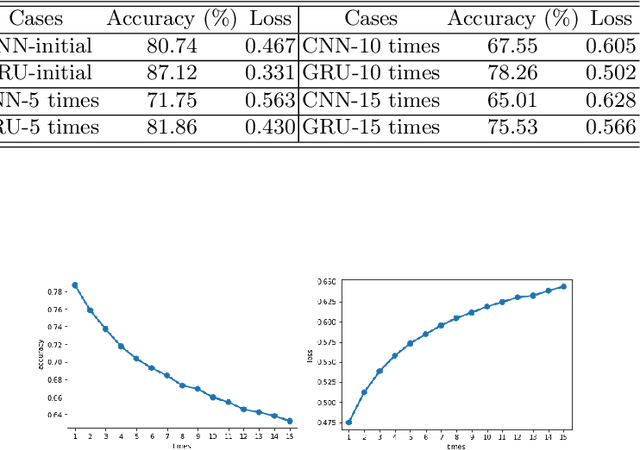
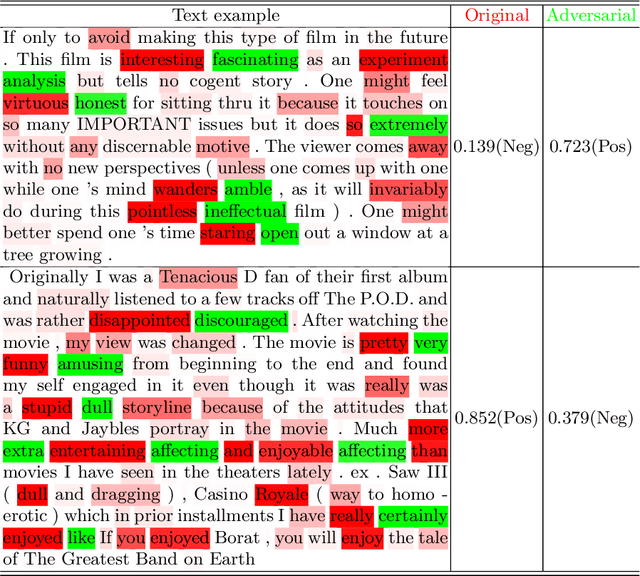
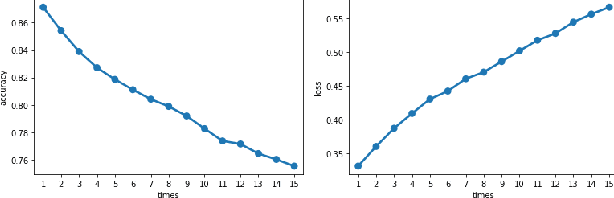
Deep neural networks have a wide range of applications in solving various real-world tasks and have achieved satisfactory results, in domains such as computer vision, image classification, and natural language processing. Meanwhile, the security and robustness of neural networks have become imperative, as diverse researches have shown the vulnerable aspects of neural networks. Case in point, in Natural language processing tasks, the neural network may be fooled by an attentively modified text, which has a high similarity to the original one. As per previous research, most of the studies are focused on the image domain; Different from image adversarial attacks, the text is represented in a discrete sequence, traditional image attack methods are not applicable in the NLP field. In this paper, we propose a word-level NLP sentiment classifier attack model, which includes a self-attention mechanism-based word selection method and a greedy search algorithm for word substitution. We experiment with our attack model by attacking GRU and 1D-CNN victim models on IMDB datasets. Experimental results demonstrate that our model achieves a higher attack success rate and more efficient than previous methods due to the efficient word selection algorithms are employed and minimized the word substitute number. Also, our model is transferable, which can be used in the image domain with several modifications.
Robust Convergence in Federated Learning through Label-wise Clustering
Dec 28, 2021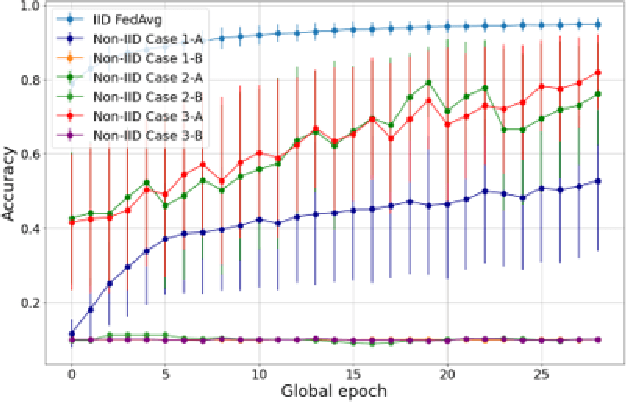
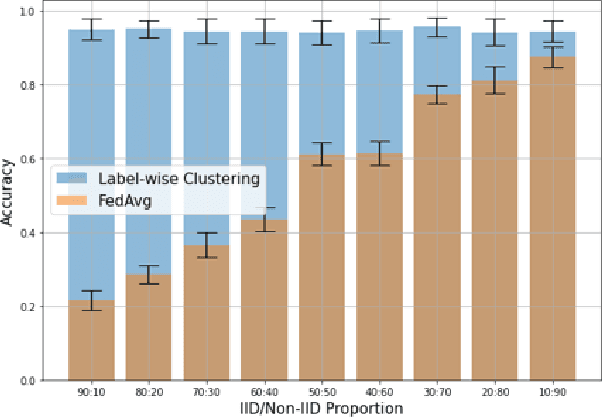
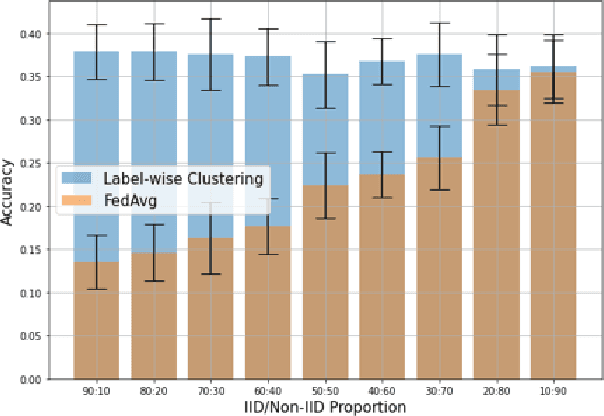
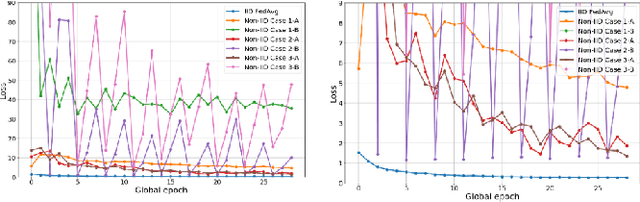
Non-IID dataset and heterogeneous environment of the local clients are regarded as a major issue in Federated Learning (FL), causing a downturn in the convergence without achieving satisfactory performance. In this paper, we propose a novel Label-wise clustering algorithm that guarantees the trainability among geographically dispersed heterogeneous local clients, by selecting only the local models trained with a dataset that approximates into uniformly distributed class labels, which is likely to obtain faster minimization of the loss and increment the accuracy among the FL network. Through conducting experiments on the suggested six common non-IID scenarios, we empirically show that the vanilla FL aggregation model is incapable of gaining robust convergence generating biased pre-trained local models and drifting the local weights to mislead the trainability in the worst case. Moreover, we quantitatively estimate the expected performance of the local models before training, which offers a global server to select the optimal clients, saving additional computational costs. Ultimately, in order to gain resolution of the non-convergence in such non-IID situations, we design clustering algorithms based on local input class labels, accommodating the diversity and assorting clients that could lead the overall system to attain the swift convergence as global training continues. Our paper shows that proposed Label-wise clustering demonstrates prompt and robust convergence compared to other FL algorithms when local training datasets are non-IID or coexist with IID through multiple experiments.