 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention Score Based Attacker for Black-box NLP Classifier
Paper and Code
Jan 01, 2022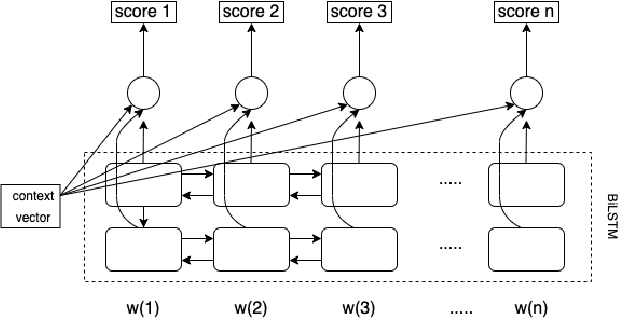
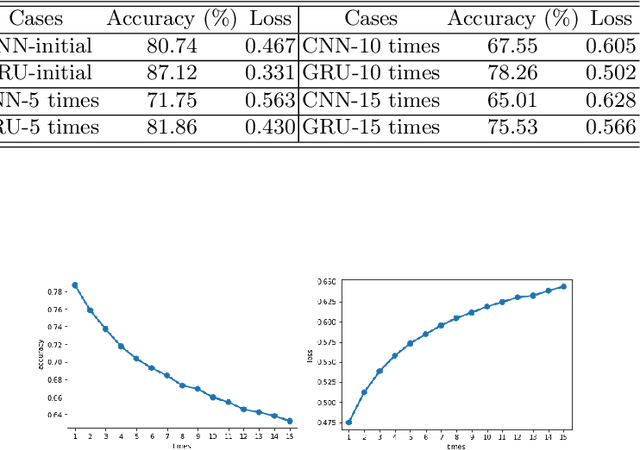
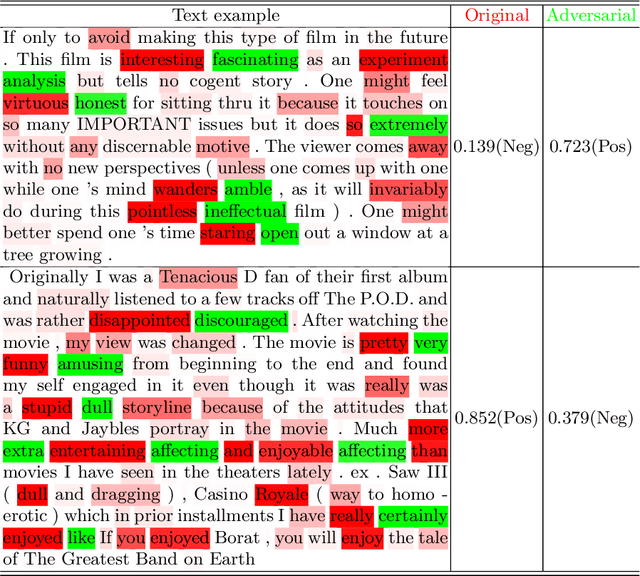
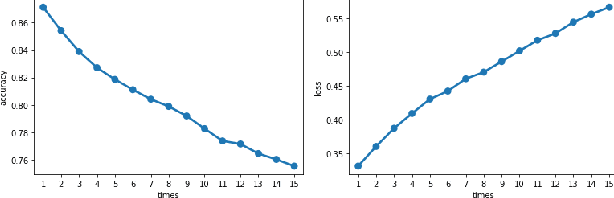
Deep neural networks have a wide range of applications in solving various real-world tasks and have achieved satisfactory results, in domains such as computer vision, image classification, and natural language processing. Meanwhile, the security and robustness of neural networks have become imperative, as diverse researches have shown the vulnerable aspects of neural networks. Case in point, in Natural language processing tasks, the neural network may be fooled by an attentively modified text, which has a high similarity to the original one. As per previous research, most of the studies are focused on the image domain; Different from image adversarial attacks, the text is represented in a discrete sequence, traditional image attack methods are not applicable in the NLP field. In this paper, we propose a word-level NLP sentiment classifier attack model, which includes a self-attention mechanism-based word selection method and a greedy search algorithm for word substitution. We experiment with our attack model by attacking GRU and 1D-CNN victim models on IMDB datasets. Experimental results demonstrate that our model achieves a higher attack success rate and more efficient than previous methods due to the efficient word selection algorithms are employed and minimized the word substitute number. Also, our model is transferable, which can be used in the image domain with several modifications.