 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Alignment Live-Streaming Recommendation
Apr 07, 2025



In recent years, integrated short-video and live-streaming platforms have gained massive global adoption, offering dynamic content creation and consumption. Unlike pre-recorded short videos, live-streaming enables real-time interaction between authors and users, fostering deeper engagement. However, this dynamic nature introduces a critical challenge for recommendation systems (RecSys): the same live-streaming vastly different experiences depending on when a user watching. To optimize recommendations, a RecSys must accurately interpret the real-time semantics of live content and align them with user preferences.
FARM: Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation
Feb 13, 2025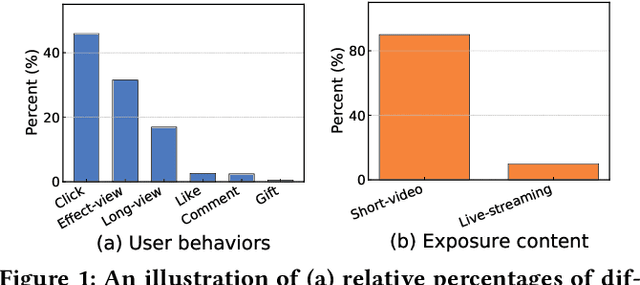
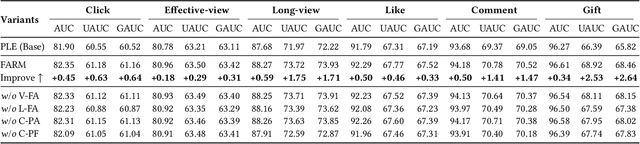
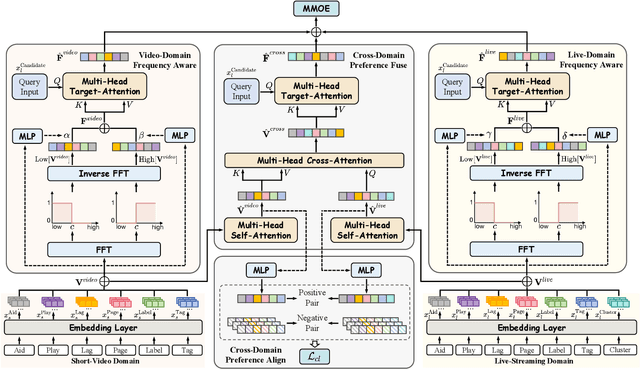
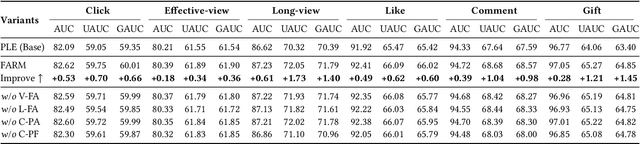
Live-streaming services have attracted widespread popularity due to their real-time interactivity and entertainment value. Users can engage with live-streaming authors by participating in live chats, posting likes, or sending virtual gifts to convey their preferences and support. However, the live-streaming services faces serious data-sparsity problem, which can be attributed to the following two points: (1) User's valuable behaviors are usually sparse, e.g., like, comment and gift, which are easily overlooked by the model, making it difficult to describe user's personalized preference. (2) The main exposure content on our platform is short-video, which is 9 times higher than the exposed live-streaming, leading to the inability of live-streaming content to fully model user preference. To this end, we propose a Frequency-Aware Model for Cross-Domain Live-Streaming Recommendation, termed as FARM. Specifically, we first present the intra-domain frequency aware module to enable our model to perceive user's sparse yet valuable behaviors, i.e., high-frequency information, supported by the Discrete Fourier Transform (DFT). To transfer user preference across the short-video and live-streaming domains, we propose a novel preference align before fuse strategy, which consists of two parts: the cross-domain preference align module to align user preference in both domains with contrastive learning, and the cross-domain preference fuse module to further fuse user preference in both domains using a serious of tailor-designed attention mechanisms. Extensive offline experiments and online A/B testing on Kuaishou live-streaming services demonstrate the effectiveness and superiority of FARM. Our FARM has been deployed in online live-streaming services and currently serves hundreds of millions of users on Kuaishou.
Neural Collaborative Filtering to Detect Anomalies in Human Semantic Trajectories
Sep 27, 2024



Human trajectory anomaly detection has become increasingly important across a wide range of applications, including security surveillance and public health. However, existing trajectory anomaly detection methods are primarily focused on vehicle-level traffic, while human-level trajectory anomaly detection remains under-explored. Since human trajectory data is often very sparse, machine learning methods have become the preferred approach for identifying complex patterns. However, concerns regarding potential biases and the robustness of these models have intensified the demand for more transparent and explainable alternatives. In response to these challenges, our research focuses on developing a lightweight anomaly detection model specifically designed to detect anomalies in human trajectories. We propose a Neural Collaborative Filtering approach to model and predict normal mobility. Our method is designed to model users' daily patterns of life without requiring prior knowledge, thereby enhancing performance in scenarios where data is sparse or incomplete, such as in cold start situations. Our algorithm consists of two main modules. The first is the collaborative filtering module, which applies collaborative filtering to model normal mobility of individual humans to places of interest. The second is the neural module, responsible for interpreting the complex spatio-temporal relationships inherent in human trajectory data. To validate our approach, we conducted extensive experiments using simulated and real-world datasets comparing to numerous state-of-the-art trajectory anomaly detection approaches.
Non-Stationary Contextual Bandit Learning via Neural Predictive Ensemble Sampling
Oct 14, 2023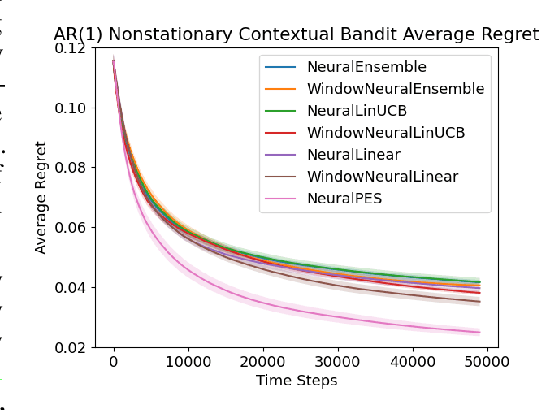


Real-world applications of contextual bandits often exhibit non-stationarity due to seasonality, serendipity, and evolving social trends. While a number of non-stationary contextual bandit learning algorithms have been proposed in the literature, they excessively explore due to a lack of prioritization for information of enduring value, or are designed in ways that do not scale in modern applications with high-dimensional user-specific features and large action set, or both. In this paper, we introduce a novel non-stationary contextual bandit algorithm that addresses these concerns. It combines a scalable, deep-neural-network-based architecture with a carefully designed exploration mechanism that strategically prioritizes collecting information with the most lasting value in a non-stationary environment. Through empirical evaluations on two real-world recommendation datasets, which exhibit pronounced non-stationarity, we demonstrate that our approach significantly outperforms the state-of-the-art baselines.
Continual Learning as Computationally Constrained Reinforcement Learning
Jul 10, 2023



An agent that efficiently accumulates knowledge to develop increasingly sophisticated skills over a long lifetime could advance the frontier of artificial intelligence capabilities. The design of such agents, which remains a long-standing challenge of artificial intelligence, is addressed by the subject of continual learning. This monograph clarifies and formalizes concepts of continual learning, introducing a framework and set of tools to stimulate further research.
A Semi-Supervised Framework for Misinformation Detection
Apr 22, 2023The spread of misinformation in social media outlets has become a prevalent societal problem and is the cause of many kinds of social unrest. Curtailing its prevalence is of great importance and machine learning has shown significant promise. However, there are two main challenges when applying machine learning to this problem. First, while much too prevalent in one respect, misinformation, actually, represents only a minor proportion of all the postings seen on social media. Second, labeling the massive amount of data necessary to train a useful classifier becomes impractical. Considering these challenges, we propose a simple semi-supervised learning framework in order to deal with extreme class imbalances that has the advantage, over other approaches, of using actual rather than simulated data to inflate the minority class. We tested our framework on two sets of Covid-related Twitter data and obtained significant improvement in F1-measure on extremely imbalanced scenarios, as compared to simple classical and deep-learning data generation methods such as SMOTE, ADASYN, or GAN-based data generation.
A Definition of Non-Stationary Bandits
Feb 23, 2023The subject of non-stationary bandit learning has attracted much recent attention. However, non-stationary bandits lack a formal definition. Loosely speaking, non-stationary bandits have typically been characterized in the literature as those for which the reward distribution changes over time. We demonstrate that this informal definition is ambiguous. Further, a widely-used notion of regret -- the dynamic regret -- is motivated by this ambiguous definition and thus problematic. In particular, even for an optimal agent, dynamic regret can suggest poor performance. The ambiguous definition also motivates a measure of the degree of non-stationarity experienced by a bandit, which often overestimates and can give rise to extremely loose regret bounds. The primary contribution of this paper is a formal definition that resolves ambiguity. This definition motivates a new notion of regret, an alternative measure of the degree of non-stationarity, and a regret analysis that leads to tighter bounds for non-stationary bandit learning. The regret analysis applies to any bandit, stationary or non-stationary, and any agent.
Brain Model State Space Reconstruction Using an LSTM Neural Network
Jan 20, 2023Objective Kalman filtering has previously been applied to track neural model states and parameters, particularly at the scale relevant to EEG. However, this approach lacks a reliable method to determine the initial filter conditions and assumes that the distribution of states remains Gaussian. This study presents an alternative, data-driven method to track the states and parameters of neural mass models (NMMs) from EEG recordings using deep learning techniques, specifically an LSTM neural network. Approach An LSTM filter was trained on simulated EEG data generated by a neural mass model using a wide range of parameters. With an appropriately customised loss function, the LSTM filter can learn the behaviour of NMMs. As a result, it can output the state vector and parameters of NMMs given observation data as the input. Main Results Test results using simulated data yielded correlations with R squared of around 0.99 and verified that the method is robust to noise and can be more accurate than a nonlinear Kalman filter when the initial conditions of the Kalman filter are not accurate. As an example of real-world application, the LSTM filter was also applied to real EEG data that included epileptic seizures, and revealed changes in connectivity strength parameters at the beginnings of seizures. Significance Tracking the state vector and parameters of mathematical brain models is of great importance in the area of brain modelling, monitoring, imaging and control. This approach has no need to specify the initial state vector and parameters, which is very difficult to do in practice because many of the variables being estimated cannot be measured directly in physiological experiments. This method may be applied using any neural mass model and, therefore, provides a general, novel, efficient approach to estimate brain model variables that are often difficult to measure.
Nonstationary Bandit Learning via Predictive Sampling
May 04, 2022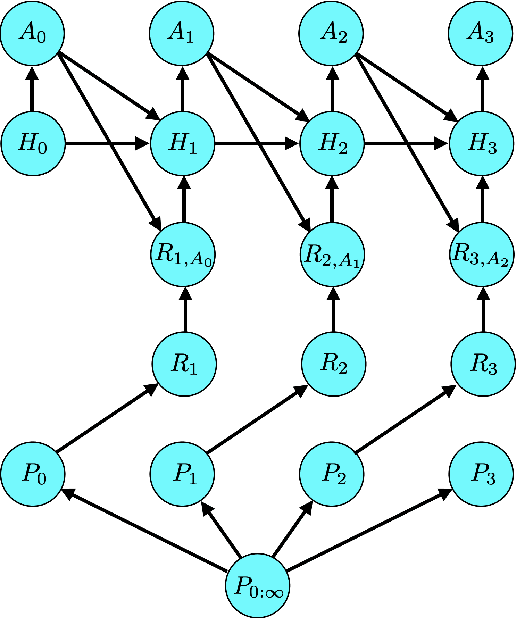

We propose predictive sampling as an approach to selecting actions that balance between exploration and exploitation in nonstationary bandit environments. When specialized to stationary environments, predictive sampling is equivalent to Thompson sampling. However, predictive sampling is effective across a range of nonstationary environments in which Thompson sampling suffers. We establish a general information-theoretic bound on the Bayesian regret of predictive sampling. We then specialize this bound to study a modulated Bernoulli bandit environment. Our analysis highlights a key advantage of predictive sampling over Thompson sampling: predictive sampling deprioritizes investments in exploration where acquired information will quickly become less relevant.
Gaussian Imagination in Bandit Learning
Jan 30, 2022
Assuming distributions are Gaussian often facilitates computations that are otherwise intractable. We study the performance of an agent that attains a bounded information ratio with respect to a bandit environment with a Gaussian prior distribution and a Gaussian likelihood function when applied instead to a Bernoulli bandit. Relative to an information-theoretic bound on the Bayesian regret the agent would incur when interacting with the Gaussian bandit, we bound the increase in regret when the agent interacts with the Bernoulli bandit. If the Gaussian prior distribution and likelihood function are sufficiently diffuse, this increase grows at a rate which is at most linear in the square-root of the time horizon, and thus the per-timestep increase vanishes. Our results formalize the folklore that so-called Bayesian agents remain effective when instantiated with diffuse misspecified distributions.