 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonstationary Bandit Learning via Predictive Sampling
Paper and Code
May 04, 2022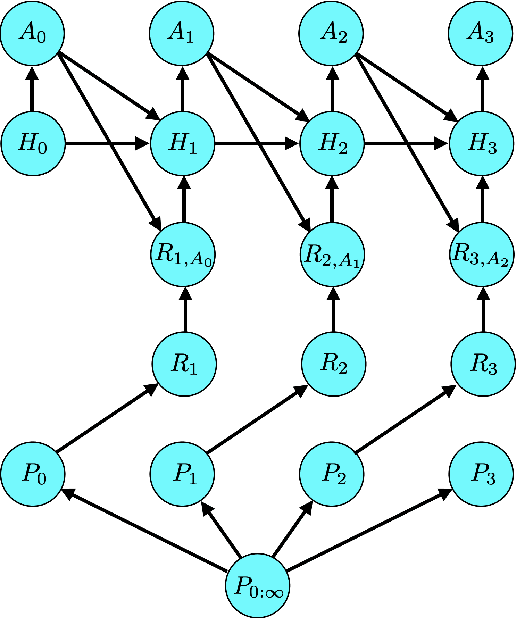

We propose predictive sampling as an approach to selecting actions that balance between exploration and exploitation in nonstationary bandit environments. When specialized to stationary environments, predictive sampling is equivalent to Thompson sampling. However, predictive sampling is effective across a range of nonstationary environments in which Thompson sampling suffers. We establish a general information-theoretic bound on the Bayesian regret of predictive sampling. We then specialize this bound to study a modulated Bernoulli bandit environment. Our analysis highlights a key advantage of predictive sampling over Thompson sampling: predictive sampling deprioritizes investments in exploration where acquired information will quickly become less relevant.