 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Agnostic to Specific: Latent Preference Diffusion for Multi-Behavior Sequential Recommendation
Feb 26, 2026Multi-behavior sequential recommendation (MBSR) aims to learn the dynamic and heterogeneous interactions of users' multi-behavior sequences, so as to capture user preferences under target behavior for the next interacted item prediction. Unlike previous methods that adopt unidirectional modeling by mapping auxiliary behaviors to target behavior, recent concerns are shifting from behavior-fixed to behavior-specific recommendation. However, these methods still ignore the user's latent preference that underlying decision-making, leading to suboptimal solutions. Meanwhile, due to the asymmetric deterministic between items and behaviors, discriminative paradigm based on preference scoring is unsuitable to capture the uncertainty from low-entropy behaviors to high-entropy items, failing to provide efficient and diverse recommendation. To address these challenges, we propose \textbf{FatsMB}, a framework based diffusion model that guides preference generation \textit{\textbf{F}rom Behavior-\textbf{A}gnostic \textbf{T}o Behavior-\textbf{S}pecific} in latent spaces, enabling diverse and accurate \textit{\textbf{M}ulti-\textbf{B}ehavior Sequential Recommendation}. Specifically, we design a Multi-Behavior AutoEncoder (MBAE) to construct a unified user latent preference space, facilitating interaction and collaboration across Behaviors, within Behavior-aware RoPE (BaRoPE) employed for multiple information fusion. Subsequently, we conduct target behavior-specific preference transfer in the latent space, enriching with informative priors. A Multi-Condition Guided Layer Normalization (MCGLN) is introduced for the denoising. Extensive experiments on real-world datasets demonstrate the effectiveness of our model.
MaRI: Accelerating Ranking Model Inference via Structural Re-parameterization in Large Scale Recommendation System
Feb 26, 2026Ranking models, i.e., coarse-ranking and fine-ranking models, serve as core components in large-scale recommendation systems, responsible for scoring massive item candidates based on user preferences. To meet the stringent latency requirements of online serving, structural lightweighting or knowledge distillation techniques are commonly employed for ranking model acceleration. However, these approaches typically lead to a non-negligible drop in accuracy. Notably, the angle of lossless acceleration by optimizing feature fusion matrix multiplication, particularly through structural reparameterization, remains underexplored. In this paper, we propose MaRI, a novel Matrix Re-parameterized Inference framework, which serves as a complementary approach to existing techniques while accelerating ranking model inference without any accuracy loss. MaRI is motivated by the observation that user-side computation is redundant in feature fusion matrix multiplication, and we therefore adopt the philosophy of structural reparameterization to alleviate such redundancy.
QARM V2: Quantitative Alignment Multi-Modal Recommendation for Reasoning User Sequence Modeling
Feb 09, 2026With the evolution of large language models (LLMs), there is growing interest in leveraging their rich semantic understanding to enhance industrial recommendation systems (RecSys). Traditional RecSys relies on ID-based embeddings for user sequence modeling in the General Search Unit (GSU) and Exact Search Unit (ESU) paradigm, which suffers from low information density, knowledge isolation, and weak generalization ability. While LLMs offer complementary strengths with dense semantic representations and strong generalization, directly applying LLM embeddings to RecSys faces critical challenges: representation unmatch with business objectives and representation unlearning end-to-end with downstream tasks. In this paper, we present QARM V2, a unified framework that bridges LLM semantic understanding with RecSys business requirements for user sequence modeling.
OneLive: Dynamically Unified Generative Framework for Live-Streaming Recommendation
Feb 09, 2026Live-streaming recommender system serves as critical infrastructure that bridges the patterns of real-time interactions between users and authors. Similar to traditional industrial recommender systems, live-streaming recommendation also relies on cascade architectures to support large-scale concurrency. Recent advances in generative recommendation unify the multi-stage recommendation process with Transformer-based architectures, offering improved scalability and higher computational efficiency. However, the inherent complexity of live-streaming prevents the direct transfer of these methods to live-streaming scenario, where continuously evolving content, limited lifecycles, strict real-time constraints, and heterogeneous multi-objectives introduce unique challenges that invalidate static tokenization and conventional model framework. To address these issues, we propose OneLive, a dynamically unified generative recommendation framework tailored for live-streaming scenario. OneLive integrates four key components: (i) A Dynamic Tokenizer that continuously encodes evolving real-time live content fused with behavior signal through residual quantization; (ii) A Time-Aware Gated Attention mechanism that explicitly models temporal dynamics for timely decision making; (iii) An efficient decoder-only generative architecture enhanced with Sequential MTP and QK Norm for stable training and accelerated inference; (iv) A Unified Multi-Objective Alignment Framework reinforces policy optimization for personalized preferences.
Radiance-Field Reinforced Pretraining: Scaling Localization Models with Unlabeled Wireless Signals
Dec 08, 2025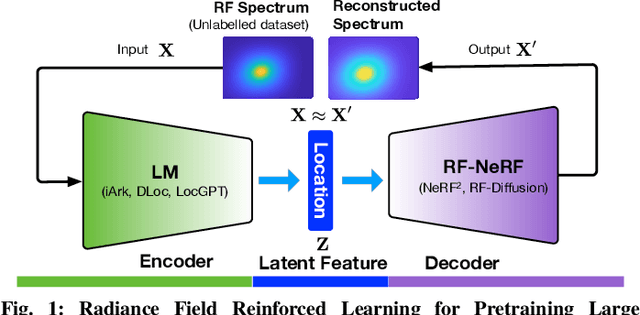
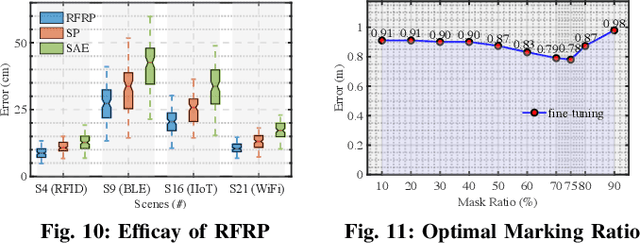
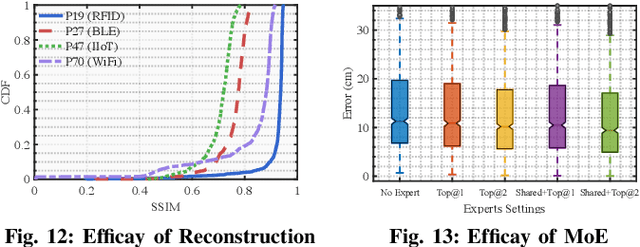
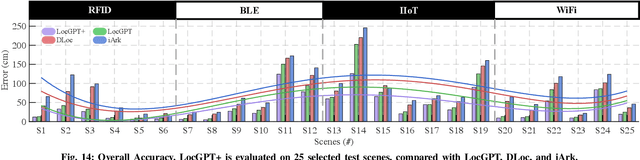
Radio frequency (RF)-based indoor localization offers significant promise for applications such as indoor navigation, augmented reality, and pervasive computing. While deep learning has greatly enhanced localization accuracy and robustness, existing localization models still face major challenges in cross-scene generalization due to their reliance on scene-specific labeled data. To address this, we introduce Radiance-Field Reinforced Pretraining (RFRP). This novel self-supervised pretraining framework couples a large localization model (LM) with a neural radio-frequency radiance field (RF-NeRF) in an asymmetrical autoencoder architecture. In this design, the LM encodes received RF spectra into latent, position-relevant representations, while the RF-NeRF decodes them to reconstruct the original spectra. This alignment between input and output enables effective representation learning using large-scale, unlabeled RF data, which can be collected continuously with minimal effort. To this end, we collected RF samples at 7,327,321 positions across 100 diverse scenes using four common wireless technologies--RFID, BLE, WiFi, and IIoT. Data from 75 scenes were used for training, and the remaining 25 for evaluation. Experimental results show that the RFRP-pretrained LM reduces localization error by over 40% compared to non-pretrained models and by 21% compared to those pretrained using supervised learning.
Decoupled Competitive Framework for Semi-supervised Medical Image Segmentation
May 30, 2025Confronting the critical challenge of insufficiently annotated samples in medical domain, semi-supervised medical image segmentation (SSMIS) emerges as a promising solution. Specifically, most methodologies following the Mean Teacher (MT) or Dual Students (DS) architecture have achieved commendable results. However, to date, these approaches face a performance bottleneck due to two inherent limitations, \textit{e.g.}, the over-coupling problem within MT structure owing to the employment of exponential moving average (EMA) mechanism, as well as the severe cognitive bias between two students of DS structure, both of which potentially lead to reduced efficacy, or even model collapse eventually. To mitigate these issues, a Decoupled Competitive Framework (DCF) is elaborated in this work, which utilizes a straightforward competition mechanism for the update of EMA, effectively decoupling students and teachers in a dynamical manner. In addition, the seamless exchange of invaluable and precise insights is facilitated among students, guaranteeing a better learning paradigm. The DCF introduced undergoes rigorous validation on three publicly accessible datasets, which encompass both 2D and 3D datasets. The results demonstrate the superiority of our method over previous cutting-edge competitors. Code will be available at https://github.com/JiaheChen2002/DCF.
LLM-Alignment Live-Streaming Recommendation
Apr 07, 2025



In recent years, integrated short-video and live-streaming platforms have gained massive global adoption, offering dynamic content creation and consumption. Unlike pre-recorded short videos, live-streaming enables real-time interaction between authors and users, fostering deeper engagement. However, this dynamic nature introduces a critical challenge for recommendation systems (RecSys): the same live-streaming vastly different experiences depending on when a user watching. To optimize recommendations, a RecSys must accurately interpret the real-time semantics of live content and align them with user preferences.
UniEDU: A Unified Language and Vision Assistant for Education Applications
Mar 26, 2025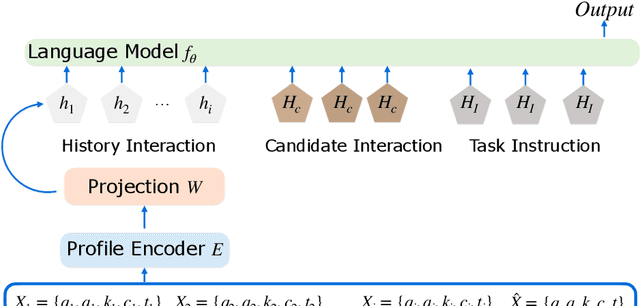
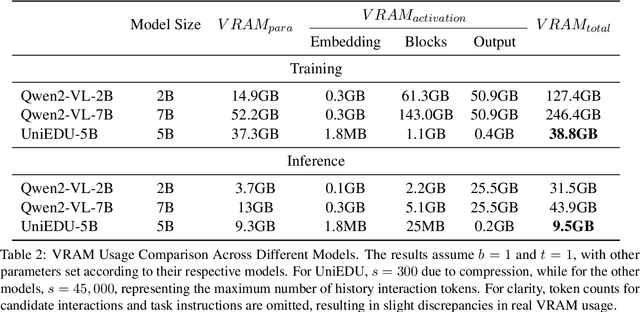
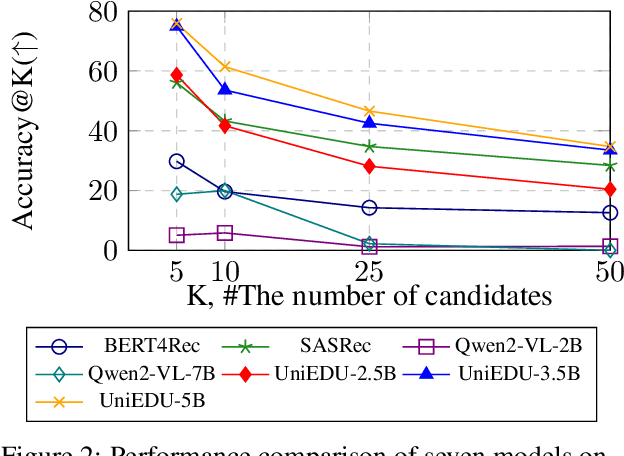
Education materials for K-12 students often consist of multiple modalities, such as text and images, posing challenges for models to fully understand nuanced information in these materials. In this paper, we propose a unified language and vision assistant UniEDU designed for various educational applications, including knowledge recommendation, knowledge tracing, time cost prediction, and user answer prediction, all within a single model. Unlike conventional task-specific models, UniEDU offers a unified solution that excels across multiple educational tasks while maintaining strong generalization capabilities. Its adaptability makes it well-suited for real-world deployment in diverse learning environments. Furthermore, UniEDU is optimized for industry-scale deployment by significantly reducing computational overhead-achieving approximately a 300\% increase in efficiency-while maintaining competitive performance with minimal degradation compared to fully fine-tuned models. This work represents a significant step toward creating versatile AI systems tailored to the evolving demands of education.
LLM Agents for Education: Advances and Applications
Mar 14, 2025Large Language Model (LLM) agents have demonstrated remarkable capabilities in automating tasks and driving innovation across diverse educational applications. In this survey, we provide a systematic review of state-of-the-art research on LLM agents in education, categorizing them into two broad classes: (1) \emph{Pedagogical Agents}, which focus on automating complex pedagogical tasks to support both teachers and students; and (2) \emph{Domain-Specific Educational Agents}, which are tailored for specialized fields such as science education, language learning, and professional development. We comprehensively examine the technological advancements underlying these LLM agents, including key datasets, benchmarks, and algorithmic frameworks that drive their effectiveness. Furthermore, we discuss critical challenges such as privacy, bias and fairness concerns, hallucination mitigation, and integration with existing educational ecosystems. This survey aims to provide a comprehensive technological overview of LLM agents for education, fostering further research and collaboration to enhance their impact for the greater good of learners and educators alike.
Corrections Meet Explanations: A Unified Framework for Explainable Grammatical Error Correction
Feb 21, 2025Grammatical Error Correction (GEC) faces a critical challenge concerning explainability, notably when GEC systems are designed for language learners. Existing research predominantly focuses on explaining grammatical errors extracted in advance, thus neglecting the relationship between explanations and corrections. To address this gap, we introduce EXGEC, a unified explainable GEC framework that integrates explanation and correction tasks in a generative manner, advocating that these tasks mutually reinforce each other. Experiments have been conducted on EXPECT, a recent human-labeled dataset for explainable GEC, comprising around 20k samples. Moreover, we detect significant noise within EXPECT, potentially compromising model training and evaluation. Therefore, we introduce an alternative dataset named EXPECT-denoised, ensuring a more objective framework for training and evaluation. Results on various NLP models (BART, T5, and Llama3) show that EXGEC models surpass single-task baselines in both tasks, demonstrating the effectiveness of our approach.