 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Job Scheduling and Resource Management in Cloud Computing: An Algorithm-Level Review
Jan 02, 2025



Cloud computing has revolutionized the provisioning of computing resources, offering scalable, flexible, and on-demand services to meet the diverse requirements of modern applications. At the heart of efficient cloud operations are job scheduling and resource management, which are critical for optimizing system performance and ensuring timely and cost-effective service delivery. However, the dynamic and heterogeneous nature of cloud environments presents significant challenges for these tasks, as workloads and resource availability can fluctuate unpredictably. Traditional approaches, including heuristic and meta-heuristic algorithms, often struggle to adapt to these real-time changes due to their reliance on static models or predefined rules. Deep Reinforcement Learning (DRL) has emerged as a promising solution to these challenges by enabling systems to learn and adapt policies based on continuous observations of the environment, facilitating intelligent and responsive decision-making. This survey provides a comprehensive review of DRL-based algorithms for job scheduling and resource management in cloud computing, analyzing their methodologies, performance metrics, and practical applications. We also highlight emerging trends and future research directions, offering valuable insights into leveraging DRL to advance both job scheduling and resource management in cloud computing.
Large Language Models for Explainable Decisions in Dynamic Digital Twins
May 23, 2024


Dynamic data-driven Digital Twins (DDTs) can enable informed decision-making and provide an optimisation platform for the underlying system. By leveraging principles of Dynamic Data-Driven Applications Systems (DDDAS), DDTs can formulate computational modalities for feedback loops, model updates and decision-making, including autonomous ones. However, understanding autonomous decision-making often requires technical and domain-specific knowledge. This paper explores using large language models (LLMs) to provide an explainability platform for DDTs, generating natural language explanations of the system's decision-making by leveraging domain-specific knowledge bases. A case study from smart agriculture is presented.
Towards A Flexible Accuracy-Oriented Deep Learning Module Inference Latency Prediction Framework for Adaptive Optimization Algorithms
Dec 11, 2023With the rapid development of Deep Learning, more and more applications on the cloud and edge tend to utilize large DNN (Deep Neural Network) models for improved task execution efficiency as well as decision-making quality. Due to memory constraints, models are commonly optimized using compression, pruning, and partitioning algorithms to become deployable onto resource-constrained devices. As the conditions in the computational platform change dynamically, the deployed optimization algorithms should accordingly adapt their solutions. To perform frequent evaluations of these solutions in a timely fashion, RMs (Regression Models) are commonly trained to predict the relevant solution quality metrics, such as the resulted DNN module inference latency, which is the focus of this paper. Existing prediction frameworks specify different RM training workflows, but none of them allow flexible configurations of the input parameters (e.g., batch size, device utilization rate) and of the selected RMs for different modules. In this paper, a deep learning module inference latency prediction framework is proposed, which i) hosts a set of customizable input parameters to train multiple different RMs per DNN module (e.g., convolutional layer) with self-generated datasets, and ii) automatically selects a set of trained RMs leading to the highest possible overall prediction accuracy, while keeping the prediction time / space consumption as low as possible. Furthermore, a new RM, namely MEDN (Multi-task Encoder-Decoder Network), is proposed as an alternative solution. Comprehensive experiment results show that MEDN is fast and lightweight, and capable of achieving the highest overall prediction accuracy and R-squared value. The Time/Space-efficient Auto-selection algorithm also manages to improve the overall accuracy by 2.5% and R-squared by 0.39%, compared to the MEDN single-selection scheme.
Dynamic Data-Driven Digital Twins for Blockchain Systems
Dec 07, 2023In recent years, we have seen an increase in the adoption of blockchain-based systems in non-financial applications, looking to benefit from what the technology has to offer. Although many fields have managed to include blockchain in their core functionalities, the adoption of blockchain, in general, is constrained by the so-called trilemma trade-off between decentralization, scalability, and security. In our previous work, we have shown that using a digital twin for dynamically managing blockchain systems during runtime can be effective in managing the trilemma trade-off. Our Digital Twin leverages DDDAS feedback loop, which is responsible for getting the data from the system to the digital twin, conducting optimisation, and updating the physical system. This paper examines how leveraging DDDAS feedback loop can support the optimisation component of the trilemma benefiting from Reinforcement Learning agents and a simulation component to augment the quality of the learned model while reducing the computational overhead required for decision-making.
Explainable Human-in-the-loop Dynamic Data-Driven Digital Twins
Jul 19, 2022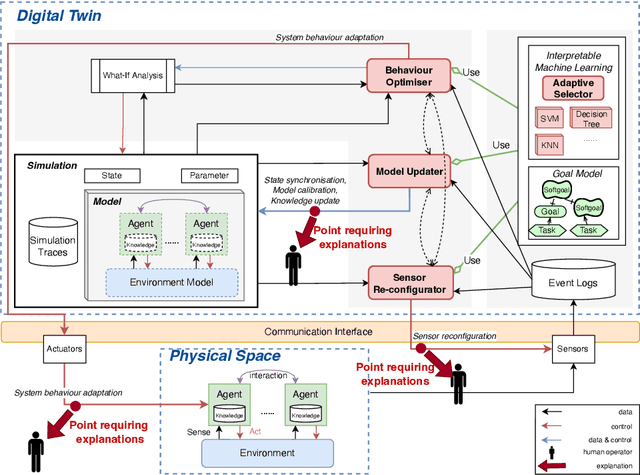
Digital Twins (DT) are essentially Dynamic Data-driven models that serve as real-time symbiotic "virtual replicas" of real-world systems. DT can leverage fundamentals of Dynamic Data-Driven Applications Systems (DDDAS) bidirectional symbiotic sensing feedback loops for its continuous updates. Sensing loops can consequently steer measurement, analysis and reconfiguration aimed at more accurate modelling and analysis in DT. The reconfiguration decisions can be autonomous or interactive, keeping human-in-the-loop. The trustworthiness of these decisions can be hindered by inadequate explainability of the rationale, and utility gained in implementing the decision for the given situation among alternatives. Additionally, different decision-making algorithms and models have varying complexity, quality and can result in different utility gained for the model. The inadequacy of explainability can limit the extent to which humans can evaluate the decisions, often leading to updates which are unfit for the given situation, erroneous, compromising the overall accuracy of the model. The novel contribution of this paper is an approach to harnessing explainability in human-in-the-loop DDDAS and DT systems, leveraging bidirectional symbiotic sensing feedback. The approach utilises interpretable machine learning and goal modelling to explainability, and considers trade-off analysis of utility gained. We use examples from smart warehousing to demonstrate the approach.
A Baselined Gated Attention Recurrent Network for Request Prediction in Ridesharing
Jul 11, 2022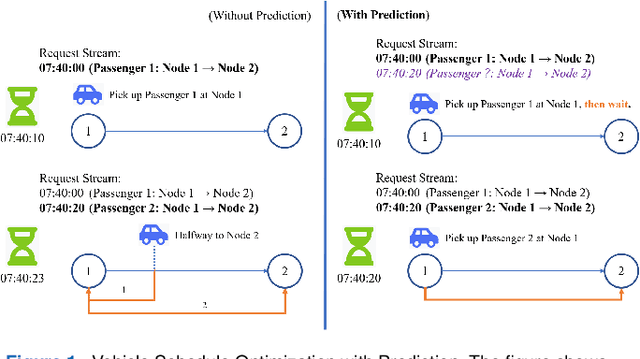
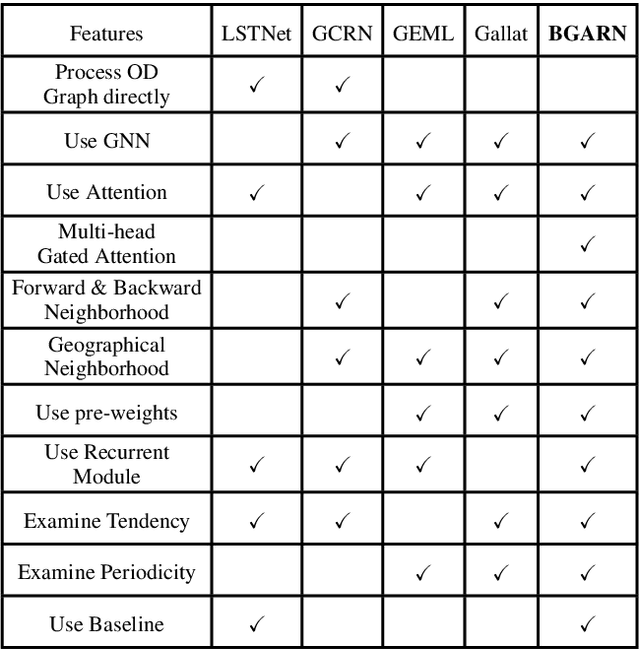
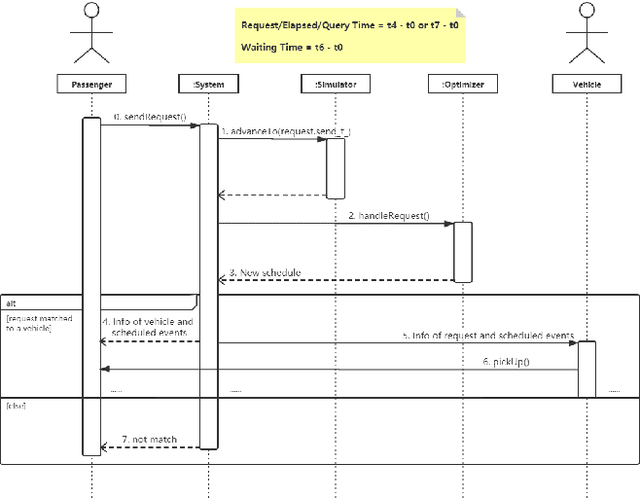
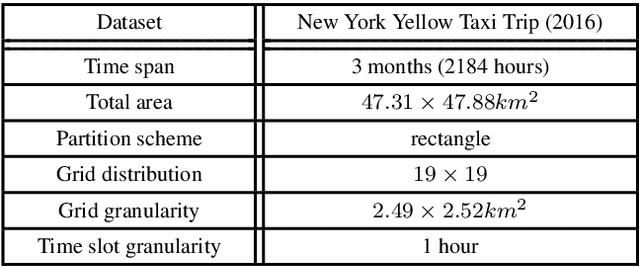
Ridesharing has received global popularity due to its convenience and cost efficiency for both drivers and passengers and its strong potential to contribute to the implementation of the UN Sustainable Development Goals. As a result recent years have witnessed an explosion of research interest in the RSODP (Origin-Destination Prediction for Ridesharing) problem with the goal of predicting the future ridesharing requests and providing schedules for vehicles ahead of time. Most of existing prediction models utilise Deep Learning, however they fail to effectively consider both spatial and temporal dynamics. In this paper the Baselined Gated Attention Recurrent Network (BGARN), is proposed, which uses graph convolution with multi-head gated attention to extract spatial features, a recurrent module to extract temporal features, and a baselined transferring layer to calculate the final results. The model is implemented with PyTorch and DGL (Deep Graph Library) and is experimentally evaluated using the New York Taxi Demand Dataset. The results show that BGARN outperforms all the other existing models in terms of prediction accuracy.
Digital Twins for Dynamic Management of Blockchain Systems
Apr 26, 2022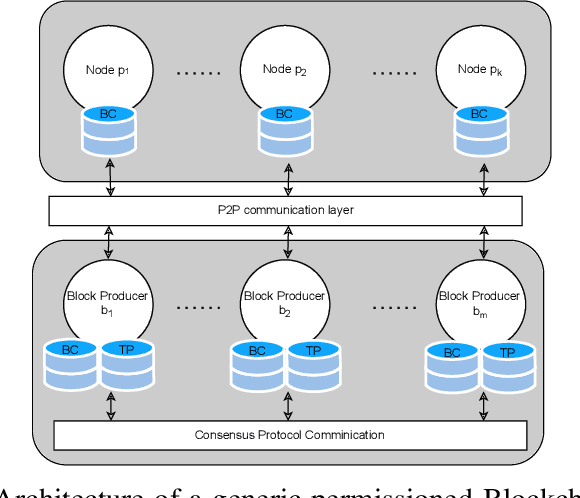
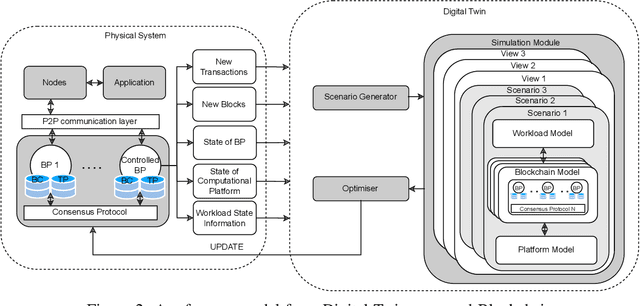
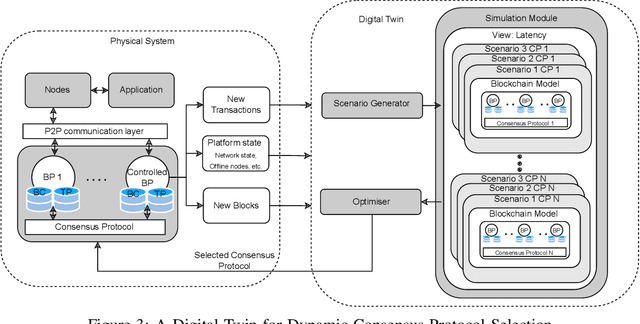
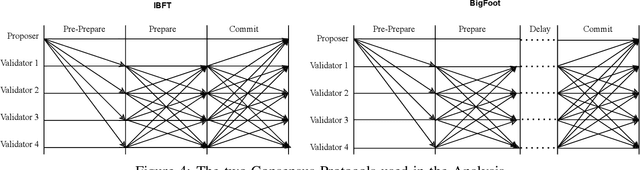
Blockchain systems are challenged by the so-called Trilemma tradeoff: decentralization, scalability and security. Infrastructure and node configuration, choice of the Consensus Protocol and complexity of the application transactions are cited amongst the factors that affect the tradeoffs balance. Given that Blockchains are complex, dynamic dynamic systems, a dynamic approach to their management and reconfiguration at runtime is deemed necessary to reflect the changes in the state of the infrastructure and application. This paper introduces the utilisation of Digital Twins for this purpose. The novel contribution of the paper is design of a framework and conceptual architecture of a Digital Twin that can assist in maintaining the Trilemma tradeoffs of time critical systems. The proposed Digital Twin is illustrated via an innovative approach to dynamic selection of Consensus Protocols. Simulations results show that the proposed framework can effectively support the dynamic adaptation and management of the Blockchain
Knowledge Equivalence in Digital Twins of Intelligent Systems
Apr 15, 2022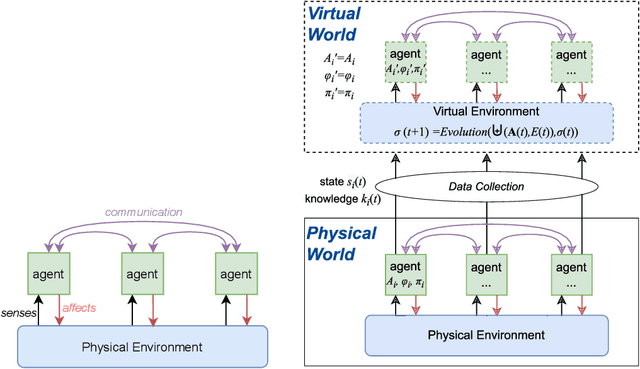
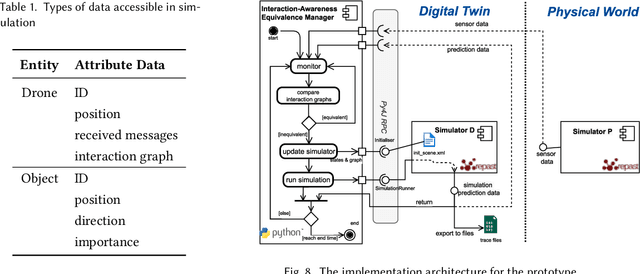
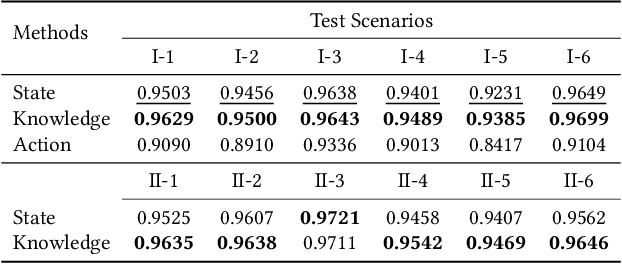
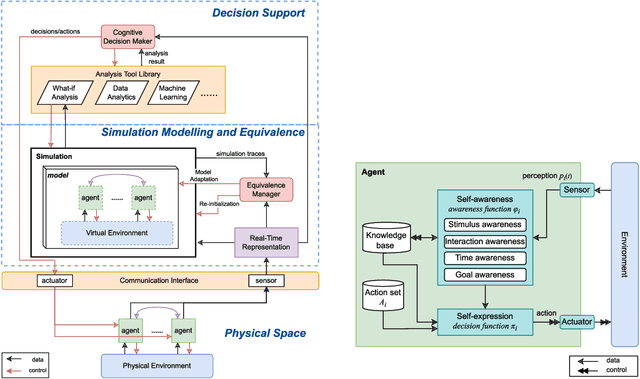
A digital twin contains up-to-date data-driven models of the physical world being studied and can use simulation to optimise the physical world. However, the analysis made by the digital twin is valid and reliable only when the model is equivalent to the physical world. Maintaining such an equivalent model is challenging, especially when the physical systems being modelled are intelligent and autonomous. The paper focuses in particular on digital twin models of intelligent systems where the systems are knowledge-aware but with limited capability. The digital twin improves the acting of the physical system at a meta-level by accumulating more knowledge in the simulated environment. The modelling of such an intelligent physical system requires replicating the knowledge-awareness capability in the virtual space. Novel equivalence maintaining techniques are needed, especially in synchronising the knowledge between the model and the physical system. This paper proposes the notion of knowledge equivalence and an equivalence maintaining approach by knowledge comparison and updates. A quantitative analysis of the proposed approach confirms that compared to state equivalence, knowledge equivalence maintenance can tolerate deviation thus reducing unnecessary updates and achieve more Pareto efficient solutions for the trade-off between update overhead and simulation reliability.
Online NEAT for Credit Evaluation -- a Dynamic Problem with Sequential Data
Jul 06, 2020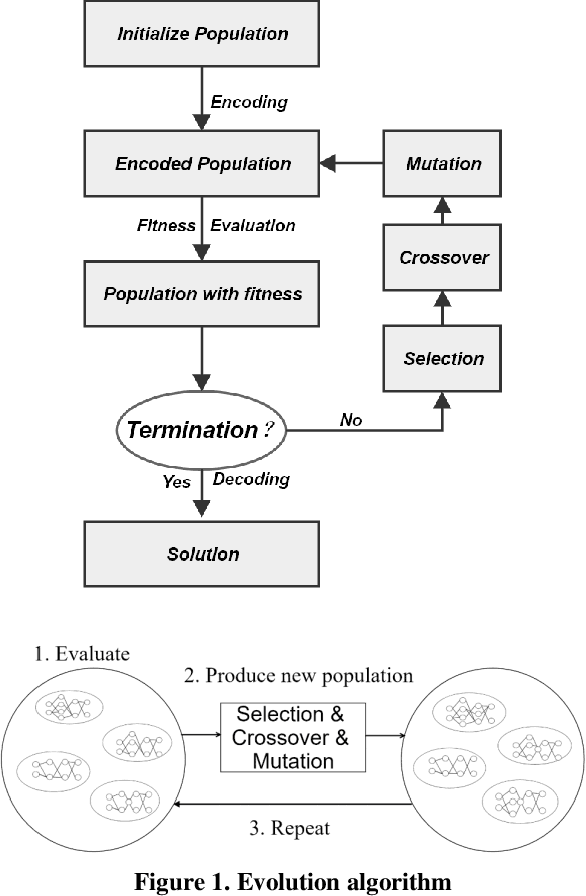


In this paper, we describe application of Neuroevolution to a P2P lending problem in which a credit evaluation model is updated based on streaming data. We apply the algorithm Neuroevolution of Augmenting Topologies (NEAT) which has not been widely applied generally in the credit evaluation domain. In addition to comparing the methodology with other widely applied machine learning techniques, we develop and evaluate several enhancements to the algorithm which make it suitable for the particular aspects of online learning that are relevant in the problem. These include handling unbalanced streaming data, high computation costs, and maintaining model similarity over time, that is training the stochastic learning algorithm with new data but minimizing model change except where there is a clear benefit for model performance
TMIXT: A process flow for Transcribing MIXed handwritten and machine-printed Text
Apr 28, 2019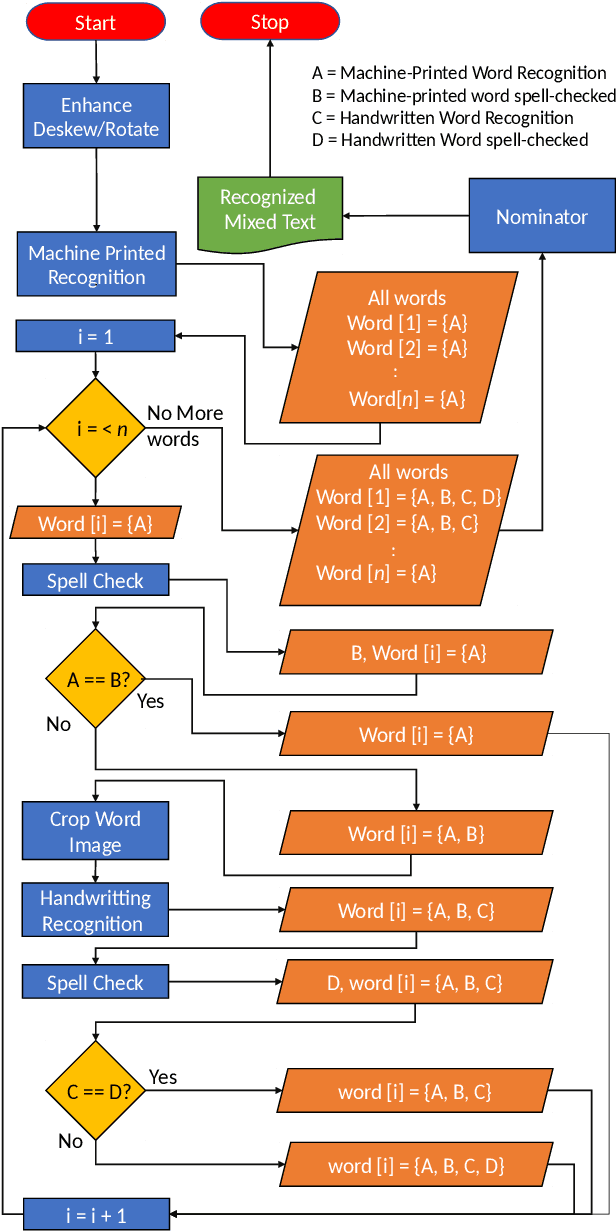



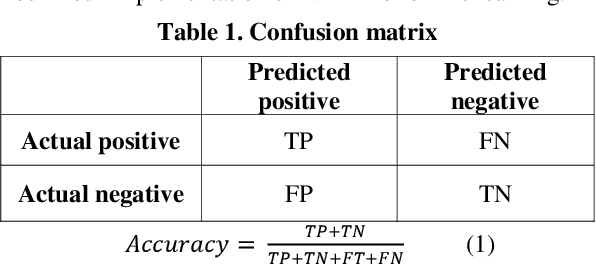
Handling large corpuses of documents is of significant importance in many fields, no more so than in the areas of crime investigation and defence, where an organisation may be presented with a large volume of scanned documents which need to be processed in a finite time. However, this problem is exacerbated both by the volume, in terms of scanned documents and the complexity of the pages, which need to be processed. Often containing many different elements, which each need to be processed and understood. Text recognition, which is a primary task of this process, is usually dependent upon the type of text, being either handwritten or machine-printed. Accordingly, the recognition involves prior classification of the text category, before deciding on the recognition method to be applied. This poses a more challenging task if a document contains both handwritten and machine-printed text. In this work, we present a generic process flow for text recognition in scanned documents containing mixed handwritten and machine-printed text without the need to classify text in advance. We realize the proposed process flow using several open-source image processing and text recognition packages1. The evaluation is performed using a specially developed variant, presented in this work, of the IAM handwriting database, where we achieve an average transcription accuracy of nearly 80% for pages containing both printed and handwritten text.
* big data, unstructured data, Optical Character Recognition (OCR), Handwritten Text Recognition (HTR), machine-printed text recognition, IAM handwriting database, TMIXT