 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Explainable Decisions in Dynamic Digital Twins
May 23, 2024


Dynamic data-driven Digital Twins (DDTs) can enable informed decision-making and provide an optimisation platform for the underlying system. By leveraging principles of Dynamic Data-Driven Applications Systems (DDDAS), DDTs can formulate computational modalities for feedback loops, model updates and decision-making, including autonomous ones. However, understanding autonomous decision-making often requires technical and domain-specific knowledge. This paper explores using large language models (LLMs) to provide an explainability platform for DDTs, generating natural language explanations of the system's decision-making by leveraging domain-specific knowledge bases. A case study from smart agriculture is presented.
Towards A Flexible Accuracy-Oriented Deep Learning Module Inference Latency Prediction Framework for Adaptive Optimization Algorithms
Dec 11, 2023With the rapid development of Deep Learning, more and more applications on the cloud and edge tend to utilize large DNN (Deep Neural Network) models for improved task execution efficiency as well as decision-making quality. Due to memory constraints, models are commonly optimized using compression, pruning, and partitioning algorithms to become deployable onto resource-constrained devices. As the conditions in the computational platform change dynamically, the deployed optimization algorithms should accordingly adapt their solutions. To perform frequent evaluations of these solutions in a timely fashion, RMs (Regression Models) are commonly trained to predict the relevant solution quality metrics, such as the resulted DNN module inference latency, which is the focus of this paper. Existing prediction frameworks specify different RM training workflows, but none of them allow flexible configurations of the input parameters (e.g., batch size, device utilization rate) and of the selected RMs for different modules. In this paper, a deep learning module inference latency prediction framework is proposed, which i) hosts a set of customizable input parameters to train multiple different RMs per DNN module (e.g., convolutional layer) with self-generated datasets, and ii) automatically selects a set of trained RMs leading to the highest possible overall prediction accuracy, while keeping the prediction time / space consumption as low as possible. Furthermore, a new RM, namely MEDN (Multi-task Encoder-Decoder Network), is proposed as an alternative solution. Comprehensive experiment results show that MEDN is fast and lightweight, and capable of achieving the highest overall prediction accuracy and R-squared value. The Time/Space-efficient Auto-selection algorithm also manages to improve the overall accuracy by 2.5% and R-squared by 0.39%, compared to the MEDN single-selection scheme.
A Baselined Gated Attention Recurrent Network for Request Prediction in Ridesharing
Jul 11, 2022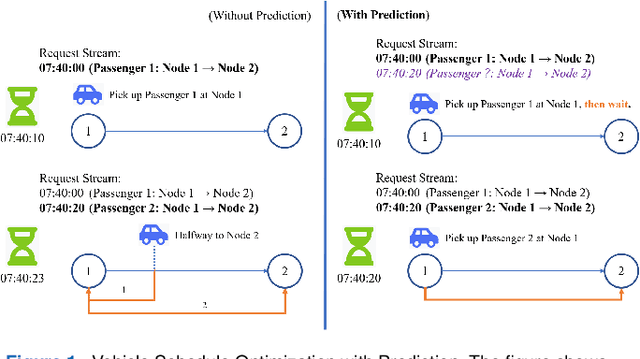
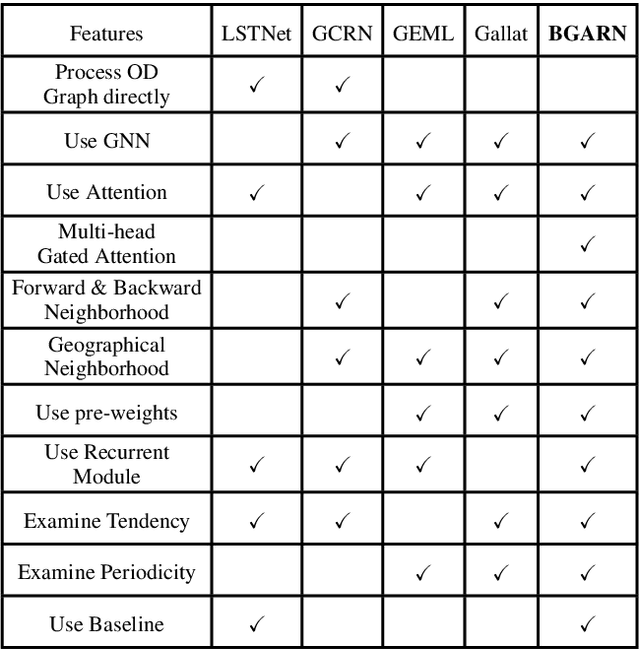
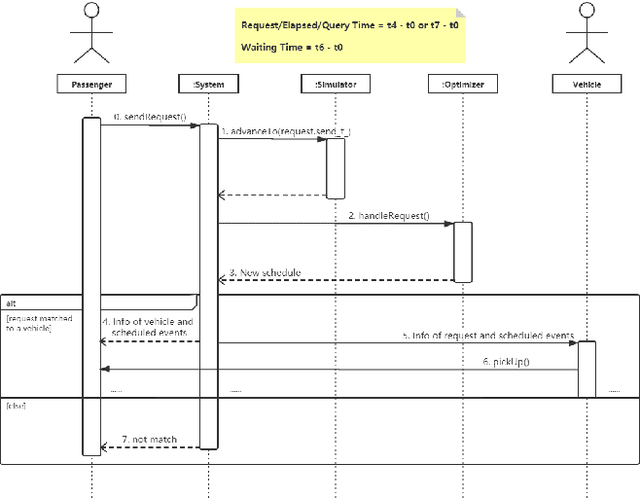
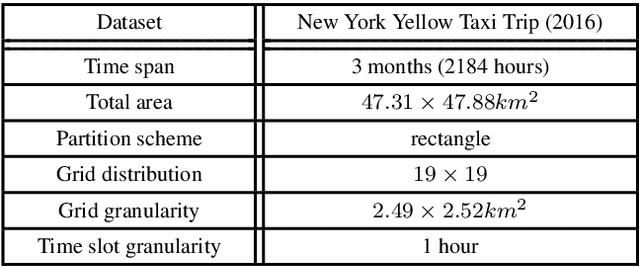
Ridesharing has received global popularity due to its convenience and cost efficiency for both drivers and passengers and its strong potential to contribute to the implementation of the UN Sustainable Development Goals. As a result recent years have witnessed an explosion of research interest in the RSODP (Origin-Destination Prediction for Ridesharing) problem with the goal of predicting the future ridesharing requests and providing schedules for vehicles ahead of time. Most of existing prediction models utilise Deep Learning, however they fail to effectively consider both spatial and temporal dynamics. In this paper the Baselined Gated Attention Recurrent Network (BGARN), is proposed, which uses graph convolution with multi-head gated attention to extract spatial features, a recurrent module to extract temporal features, and a baselined transferring layer to calculate the final results. The model is implemented with PyTorch and DGL (Deep Graph Library) and is experimentally evaluated using the New York Taxi Demand Dataset. The results show that BGARN outperforms all the other existing models in terms of prediction accuracy.