 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Attention-Based Mechanism for Bimodal Emotion Classification
Jun 28, 2024



Big data contain rich information for machine learning algorithms to utilize when learning important features during classification tasks. Human beings express their emotion using certain words, speech (tone, pitch, speed) or facial expression. Artificial Intelligence approach to emotion classification are largely based on learning from textual information. However, public datasets containing text and speech data provide sufficient resources to train machine learning algorithms for the tack of emotion classification. In this paper, we present novel bimodal deep learning-based architectures enhanced with attention mechanism trained and tested on text and speech data for emotion classification. We report details of different deep learning based architectures and show the performance of each architecture including rigorous error analyses. Our finding suggests that deep learning based architectures trained on different types of data (text and speech) outperform architectures trained only on text or speech. Our proposed attention-based bimodal architecture outperforms several state-of-the-art systems in emotion classification.
A Literature Survey of Recent Advances in Chatbots
Jan 17, 2022
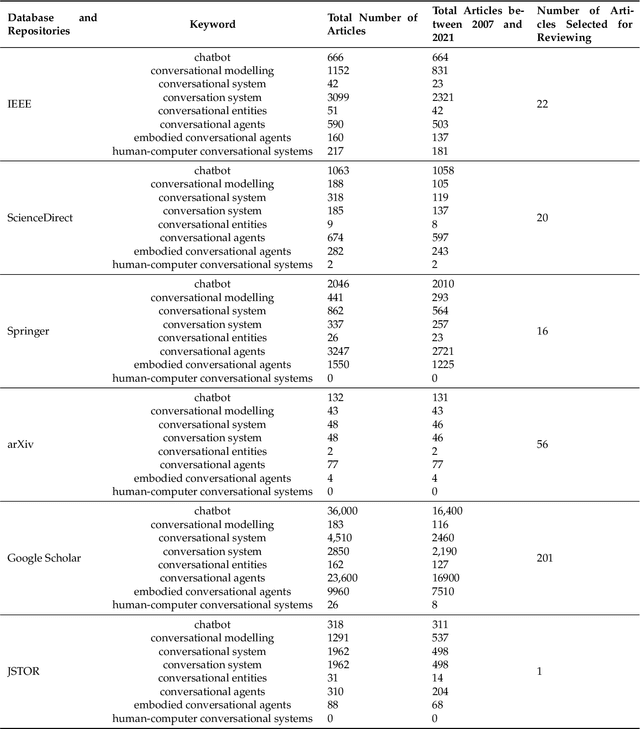
Chatbots are intelligent conversational computer systems designed to mimic human conversation to enable automated online guidance and support. The increased benefits of chatbots led to their wide adoption by many industries in order to provide virtual assistance to customers. Chatbots utilise methods and algorithms from two Artificial Intelligence domains: Natural Language Processing and Machine Learning. However, there are many challenges and limitations in their application. In this survey we review recent advances on chatbots, where Artificial Intelligence and Natural Language processing are used. We highlight the main challenges and limitations of current work and make recommendations for future research investigation.
TMIXT: A process flow for Transcribing MIXed handwritten and machine-printed Text
Apr 28, 2019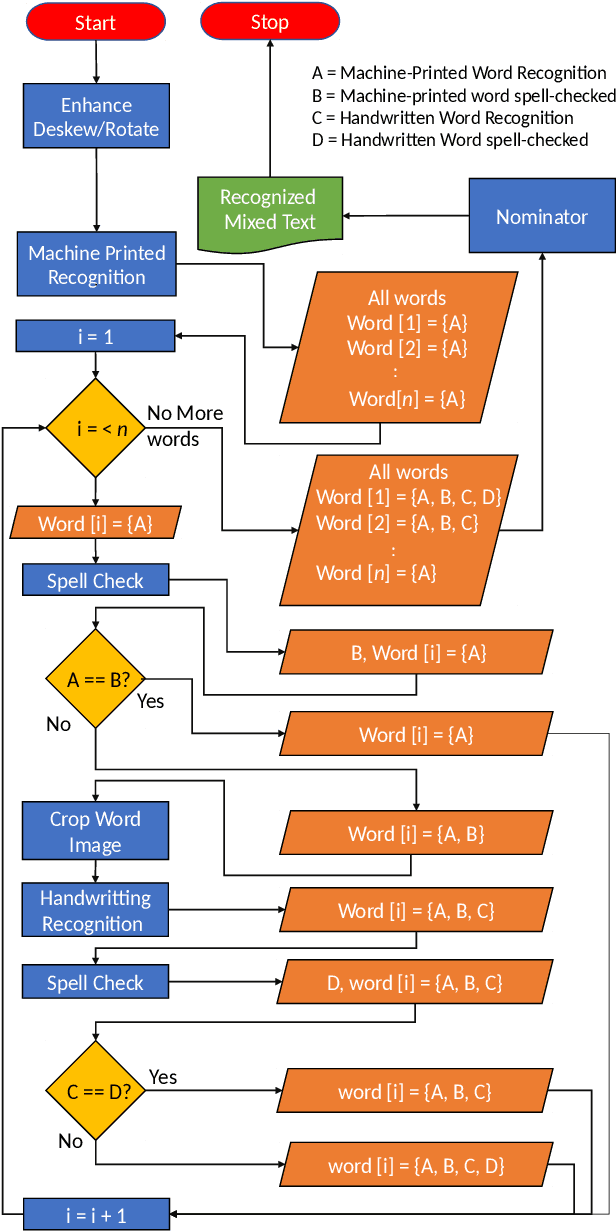



Handling large corpuses of documents is of significant importance in many fields, no more so than in the areas of crime investigation and defence, where an organisation may be presented with a large volume of scanned documents which need to be processed in a finite time. However, this problem is exacerbated both by the volume, in terms of scanned documents and the complexity of the pages, which need to be processed. Often containing many different elements, which each need to be processed and understood. Text recognition, which is a primary task of this process, is usually dependent upon the type of text, being either handwritten or machine-printed. Accordingly, the recognition involves prior classification of the text category, before deciding on the recognition method to be applied. This poses a more challenging task if a document contains both handwritten and machine-printed text. In this work, we present a generic process flow for text recognition in scanned documents containing mixed handwritten and machine-printed text without the need to classify text in advance. We realize the proposed process flow using several open-source image processing and text recognition packages1. The evaluation is performed using a specially developed variant, presented in this work, of the IAM handwriting database, where we achieve an average transcription accuracy of nearly 80% for pages containing both printed and handwritten text.
* big data, unstructured data, Optical Character Recognition (OCR), Handwritten Text Recognition (HTR), machine-printed text recognition, IAM handwriting database, TMIXT
An Exploration of Dropout with RNNs for Natural Language Inference
Oct 22, 2018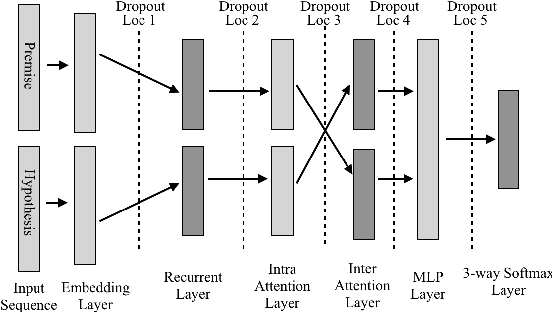
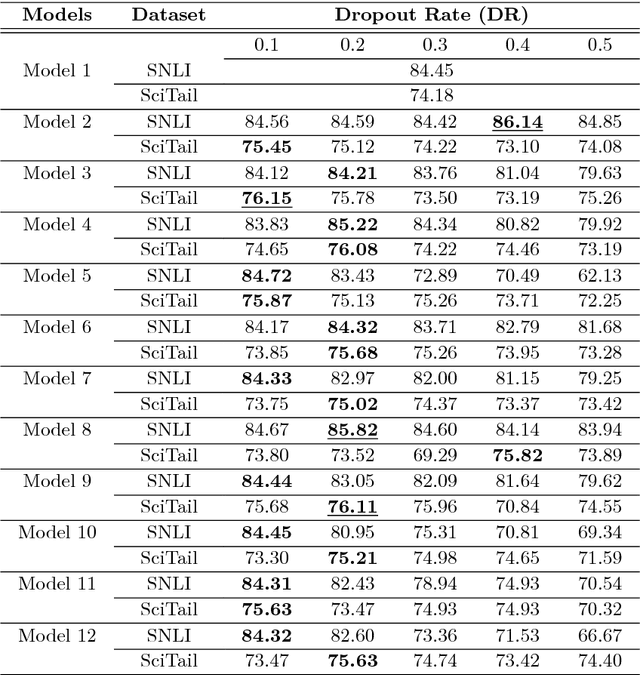
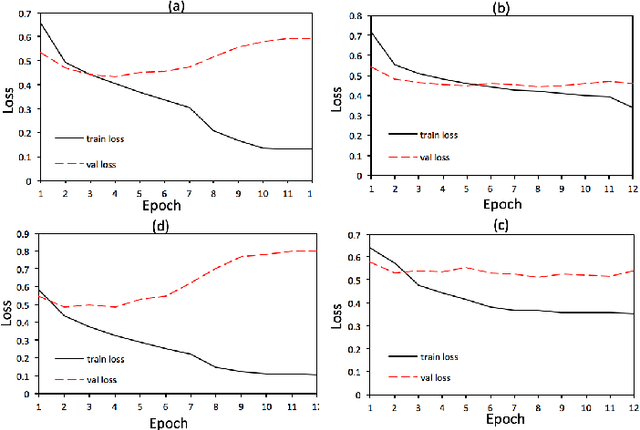
Dropout is a crucial regularization technique for the Recurrent Neural Network (RNN) models of Natural Language Inference (NLI). However, dropout has not been evaluated for the effectiveness at different layers and dropout rates in NLI models. In this paper, we propose a novel RNN model for NLI and empirically evaluate the effect of applying dropout at different layers in the model. We also investigate the impact of varying dropout rates at these layers. Our empirical evaluation on a large (Stanford Natural Language Inference (SNLI)) and a small (SciTail) dataset suggest that dropout at each feed-forward connection severely affects the model accuracy at increasing dropout rates. We also show that regularizing the embedding layer is efficient for SNLI whereas regularizing the recurrent layer improves the accuracy for SciTail. Our model achieved an accuracy 86.14% on the SNLI dataset and 77.05% on SciTail.