 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExBERT: An External Knowledge Enhanced BERT for Natural Language Inference
Aug 03, 2021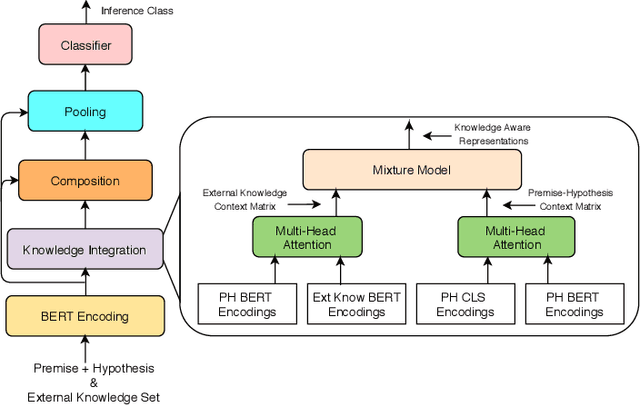
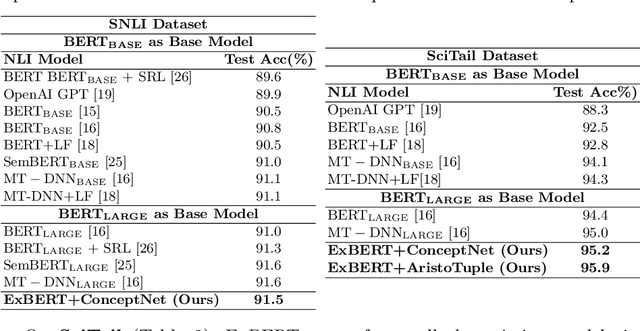

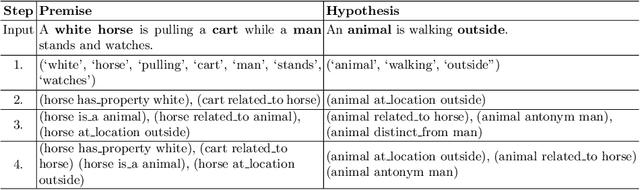
Neural language representation models such as BERT, pre-trained on large-scale unstructured corpora lack explicit grounding to real-world commonsense knowledge and are often unable to remember facts required for reasoning and inference. Natural Language Inference (NLI) is a challenging reasoning task that relies on common human understanding of language and real-world commonsense knowledge. We introduce a new model for NLI called External Knowledge Enhanced BERT (ExBERT), to enrich the contextual representation with real-world commonsense knowledge from external knowledge sources and enhance BERT's language understanding and reasoning capabilities. ExBERT takes full advantage of contextual word representations obtained from BERT and employs them to retrieve relevant external knowledge from knowledge graphs and to encode the retrieved external knowledge. Our model adaptively incorporates the external knowledge context required for reasoning over the inputs. Extensive experiments on the challenging SciTail and SNLI benchmarks demonstrate the effectiveness of ExBERT: in comparison to the previous state-of-the-art, we obtain an accuracy of 95.9% on SciTail and 91.5% on SNLI.
Bilinear Fusion of Commonsense Knowledge with Attention-Based NLI Models
Oct 22, 2020


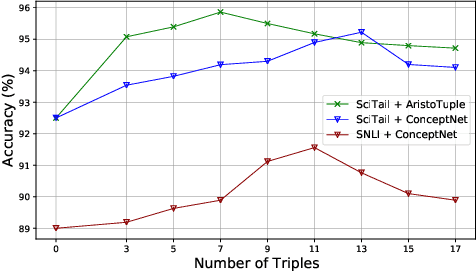
We consider the task of incorporating real-world commonsense knowledge into deep Natural Language Inference (NLI) models. Existing external knowledge incorporation methods are limited to lexical level knowledge and lack generalization across NLI models, datasets, and commonsense knowledge sources. To address these issues, we propose a novel NLI model-independent neural framework, BiCAM. BiCAM incorporates real-world commonsense knowledge into NLI models. Combined with convolutional feature detectors and bilinear feature fusion, BiCAM provides a conceptually simple mechanism that generalizes well. Quantitative evaluations with two state-of-the-art NLI baselines on SNLI and SciTail datasets in conjunction with ConceptNet and Aristo Tuple KGs show that BiCAM considerably improves the accuracy the incorporated NLI baselines. For example, our BiECAM model, an instance of BiCAM, on the challenging SciTail dataset, improves the accuracy of incorporated baselines by 7.0% with ConceptNet, and 8.0% with Aristo Tuple KG.
An Exploration of Dropout with RNNs for Natural Language Inference
Oct 22, 2018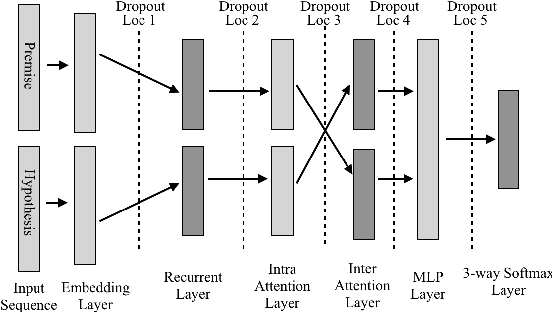
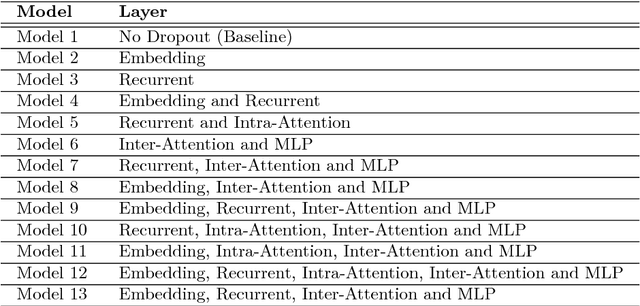
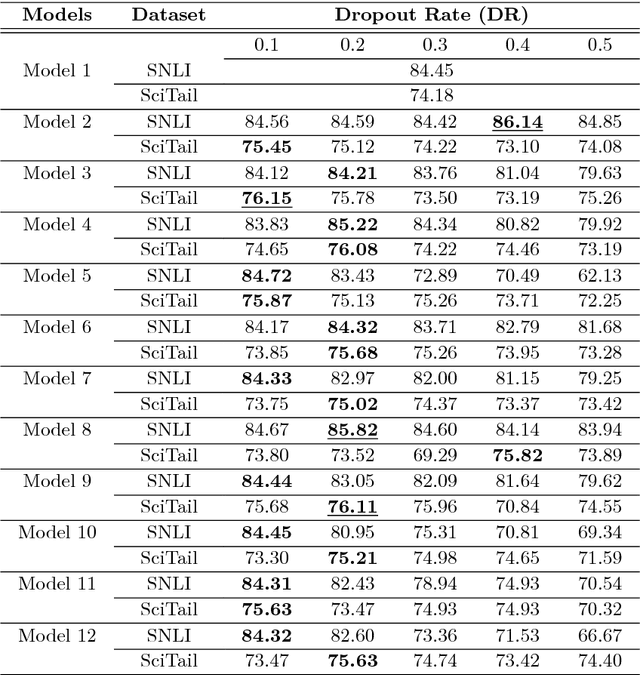
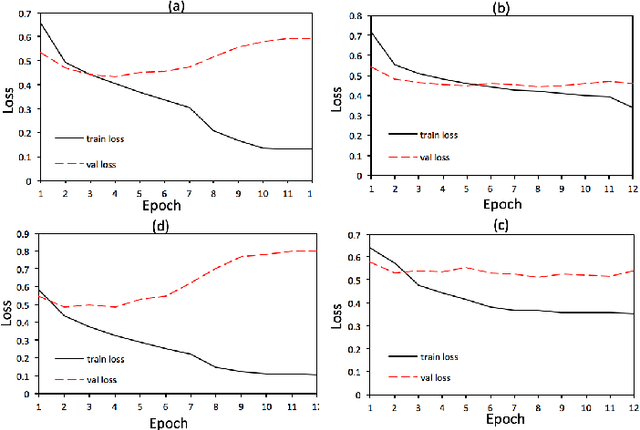
Dropout is a crucial regularization technique for the Recurrent Neural Network (RNN) models of Natural Language Inference (NLI). However, dropout has not been evaluated for the effectiveness at different layers and dropout rates in NLI models. In this paper, we propose a novel RNN model for NLI and empirically evaluate the effect of applying dropout at different layers in the model. We also investigate the impact of varying dropout rates at these layers. Our empirical evaluation on a large (Stanford Natural Language Inference (SNLI)) and a small (SciTail) dataset suggest that dropout at each feed-forward connection severely affects the model accuracy at increasing dropout rates. We also show that regularizing the embedding layer is efficient for SNLI whereas regularizing the recurrent layer improves the accuracy for SciTail. Our model achieved an accuracy 86.14% on the SNLI dataset and 77.05% on SciTail.