 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Prediction of Dynamic Physical Simulations With Pixel-Space Spatiotemporal Transformers
Oct 23, 2025Inspired by the performance and scalability of autoregressive large language models (LLMs), transformer-based models have seen recent success in the visual domain. This study investigates a transformer adaptation for video prediction with a simple end-to-end approach, comparing various spatiotemporal self-attention layouts. Focusing on causal modeling of physical simulations over time; a common shortcoming of existing video-generative approaches, we attempt to isolate spatiotemporal reasoning via physical object tracking metrics and unsupervised training on physical simulation datasets. We introduce a simple yet effective pure transformer model for autoregressive video prediction, utilizing continuous pixel-space representations for video prediction. Without the need for complex training strategies or latent feature-learning components, our approach significantly extends the time horizon for physically accurate predictions by up to 50% when compared with existing latent-space approaches, while maintaining comparable performance on common video quality metrics. In addition, we conduct interpretability experiments to identify network regions that encode information useful to perform accurate estimations of PDE simulation parameters via probing models, and find that this generalizes to the estimation of out-of-distribution simulation parameters. This work serves as a platform for further attention-based spatiotemporal modeling of videos via a simple, parameter efficient, and interpretable approach.
* 14 pages, 14 figures
Everything is a Video: Unifying Modalities through Next-Frame Prediction
Nov 15, 2024Multimodal learning, which involves integrating information from various modalities such as text, images, audio, and video, is pivotal for numerous complex tasks like visual question answering, cross-modal retrieval, and caption generation. Traditional approaches rely on modality-specific encoders and late fusion techniques, which can hinder scalability and flexibility when adapting to new tasks or modalities. To address these limitations, we introduce a novel framework that extends the concept of task reformulation beyond natural language processing (NLP) to multimodal learning. We propose to reformulate diverse multimodal tasks into a unified next-frame prediction problem, allowing a single model to handle different modalities without modality-specific components. This method treats all inputs and outputs as sequential frames in a video, enabling seamless integration of modalities and effective knowledge transfer across tasks. Our approach is evaluated on a range of tasks, including text-to-text, image-to-text, video-to-video, video-to-text, and audio-to-text, demonstrating the model's ability to generalize across modalities with minimal adaptation. We show that task reformulation can significantly simplify multimodal model design across various tasks, laying the groundwork for more generalized multimodal foundation models.
Trying Bilinear Pooling in Video-QA
Dec 18, 2020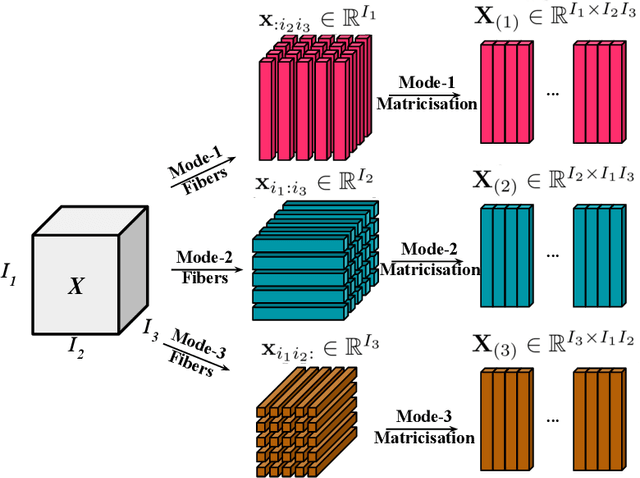
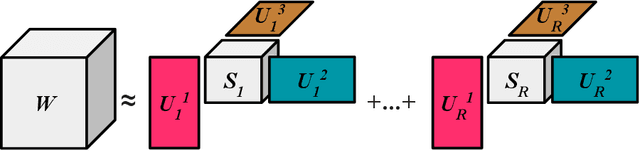
Bilinear pooling (BLP) refers to a family of operations recently developed for fusing features from different modalities predominantly developed for VQA models. A bilinear (outer-product) expansion is thought to encourage models to learn interactions between two feature spaces and has experimentally outperformed `simpler' vector operations (concatenation and element-wise-addition/multiplication) on VQA benchmarks. Successive BLP techniques have yielded higher performance with lower computational expense and are often implemented alongside attention mechanisms. However, despite significant progress in VQA, BLP methods have not been widely applied to more recently explored video question answering (video-QA) tasks. In this paper, we begin to bridge this research gap by applying BLP techniques to various video-QA benchmarks, namely: TVQA, TGIF-QA, Ego-VQA and MSVD-QA. We share our results on the TVQA baseline model, and the recently proposed heterogeneous-memory-enchanced multimodal attention (HME) model. Our experiments include both simply replacing feature concatenation in the existing models with BLP, and a modified version of the TVQA baseline to accommodate BLP we name the `dual-stream' model. We find that our relatively simple integration of BLP does not increase, and mostly harms, performance on these video-QA benchmarks. Using recently proposed theoretical multimodal fusion taxonomies, we offer insight into why BLP-driven performance gain for video-QA benchmarks may be more difficult to achieve than in earlier VQA models. We suggest a few additional `best-practices' to consider when applying BLP to video-QA. We stress that video-QA models should carefully consider where the complex representational potential from BLP is actually needed to avoid computational expense on `redundant' fusion.
On Modality Bias in the TVQA Dataset
Dec 18, 2020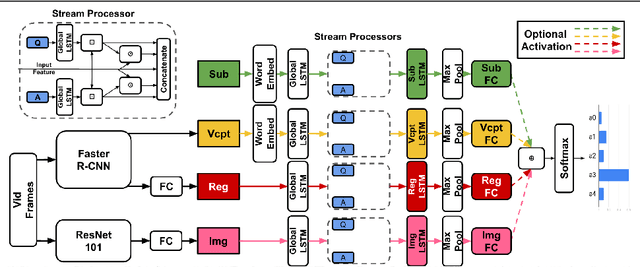
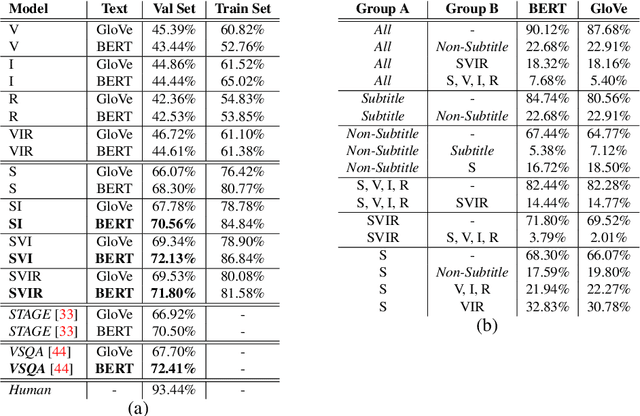
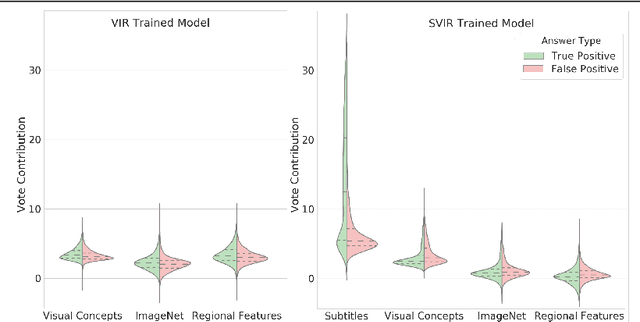

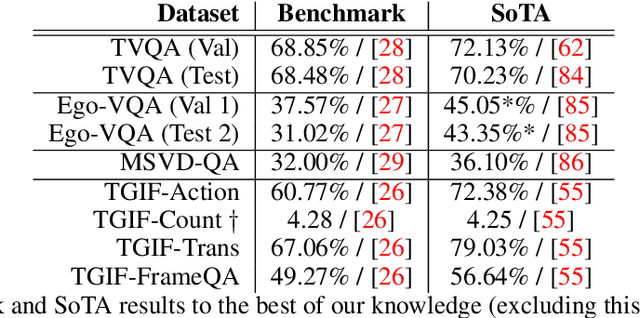
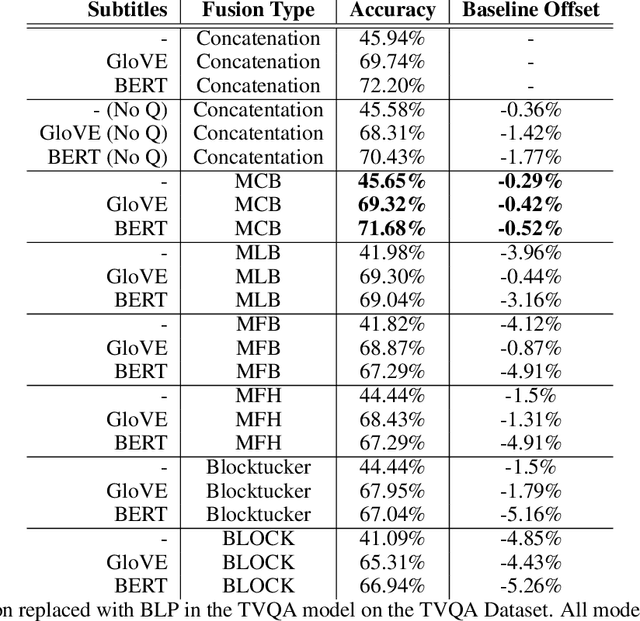
TVQA is a large scale video question answering (video-QA) dataset based on popular TV shows. The questions were specifically designed to require "both vision and language understanding to answer". In this work, we demonstrate an inherent bias in the dataset towards the textual subtitle modality. We infer said bias both directly and indirectly, notably finding that models trained with subtitles learn, on-average, to suppress video feature contribution. Our results demonstrate that models trained on only the visual information can answer ~45% of the questions, while using only the subtitles achieves ~68%. We find that a bilinear pooling based joint representation of modalities damages model performance by 9% implying a reliance on modality specific information. We also show that TVQA fails to benefit from the RUBi modality bias reduction technique popularised in VQA. By simply improving text processing using BERT embeddings with the simple model first proposed for TVQA, we achieve state-of-the-art results (72.13%) compared to the highly complex STAGE model (70.50%). We recommend a multimodal evaluation framework that can highlight biases in models and isolate visual and textual reliant subsets of data. Using this framework we propose subsets of TVQA that respond exclusively to either or both modalities in order to facilitate multimodal modelling as TVQA originally intended.
Bilinear Fusion of Commonsense Knowledge with Attention-Based NLI Models
Oct 22, 2020

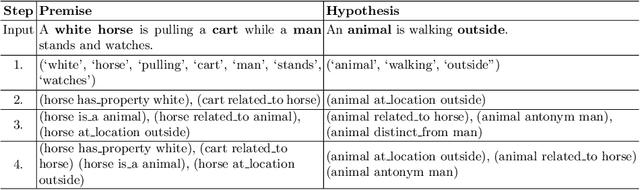

We consider the task of incorporating real-world commonsense knowledge into deep Natural Language Inference (NLI) models. Existing external knowledge incorporation methods are limited to lexical level knowledge and lack generalization across NLI models, datasets, and commonsense knowledge sources. To address these issues, we propose a novel NLI model-independent neural framework, BiCAM. BiCAM incorporates real-world commonsense knowledge into NLI models. Combined with convolutional feature detectors and bilinear feature fusion, BiCAM provides a conceptually simple mechanism that generalizes well. Quantitative evaluations with two state-of-the-art NLI baselines on SNLI and SciTail datasets in conjunction with ConceptNet and Aristo Tuple KGs show that BiCAM considerably improves the accuracy the incorporated NLI baselines. For example, our BiECAM model, an instance of BiCAM, on the challenging SciTail dataset, improves the accuracy of incorporated baselines by 7.0% with ConceptNet, and 8.0% with Aristo Tuple KG.