 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Modality Bias in the TVQA Dataset
Paper and Code
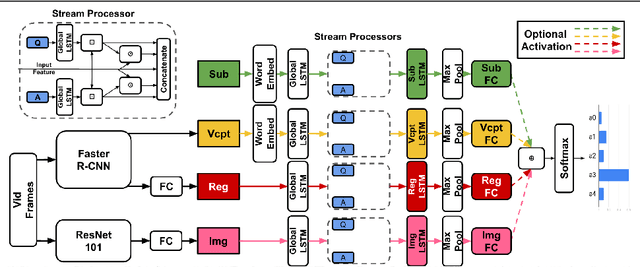
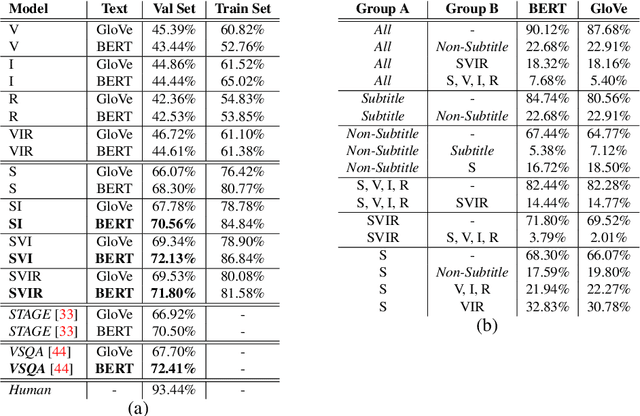
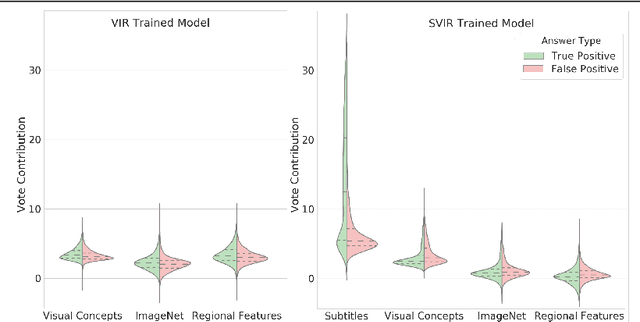

TVQA is a large scale video question answering (video-QA) dataset based on popular TV shows. The questions were specifically designed to require "both vision and language understanding to answer". In this work, we demonstrate an inherent bias in the dataset towards the textual subtitle modality. We infer said bias both directly and indirectly, notably finding that models trained with subtitles learn, on-average, to suppress video feature contribution. Our results demonstrate that models trained on only the visual information can answer ~45% of the questions, while using only the subtitles achieves ~68%. We find that a bilinear pooling based joint representation of modalities damages model performance by 9% implying a reliance on modality specific information. We also show that TVQA fails to benefit from the RUBi modality bias reduction technique popularised in VQA. By simply improving text processing using BERT embeddings with the simple model first proposed for TVQA, we achieve state-of-the-art results (72.13%) compared to the highly complex STAGE model (70.50%). We recommend a multimodal evaluation framework that can highlight biases in models and isolate visual and textual reliant subsets of data. Using this framework we propose subsets of TVQA that respond exclusively to either or both modalities in order to facilitate multimodal modelling as TVQA originally intended.