 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of ML-Based Surrogates in Bayesian Approaches to Inverse Problems
Oct 23, 2023


Neural networks have become a powerful tool as surrogate models to provide numerical solutions for scientific problems with increased computational efficiency. This efficiency can be advantageous for numerically challenging problems where time to solution is important or when evaluation of many similar analysis scenarios is required. One particular area of scientific interest is the setting of inverse problems, where one knows the forward dynamics of a system are described by a partial differential equation and the task is to infer properties of the system given (potentially noisy) observations of these dynamics. We consider the inverse problem of inferring the location of a wave source on a square domain, given a noisy solution to the 2-D acoustic wave equation. Under the assumption of Gaussian noise, a likelihood function for source location can be formulated, which requires one forward simulation of the system per evaluation. Using a standard neural network as a surrogate model makes it computationally feasible to evaluate this likelihood several times, and so Markov Chain Monte Carlo methods can be used to evaluate the posterior distribution of the source location. We demonstrate that this method can accurately infer source-locations from noisy data.
TMIXT: A process flow for Transcribing MIXed handwritten and machine-printed Text
Apr 28, 2019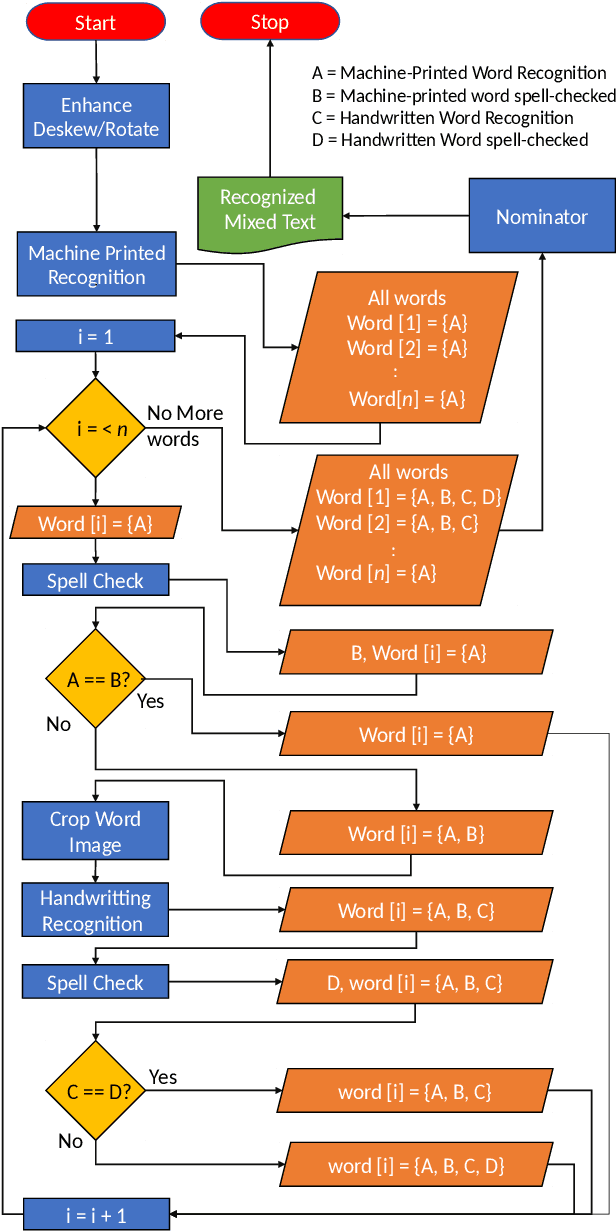



Handling large corpuses of documents is of significant importance in many fields, no more so than in the areas of crime investigation and defence, where an organisation may be presented with a large volume of scanned documents which need to be processed in a finite time. However, this problem is exacerbated both by the volume, in terms of scanned documents and the complexity of the pages, which need to be processed. Often containing many different elements, which each need to be processed and understood. Text recognition, which is a primary task of this process, is usually dependent upon the type of text, being either handwritten or machine-printed. Accordingly, the recognition involves prior classification of the text category, before deciding on the recognition method to be applied. This poses a more challenging task if a document contains both handwritten and machine-printed text. In this work, we present a generic process flow for text recognition in scanned documents containing mixed handwritten and machine-printed text without the need to classify text in advance. We realize the proposed process flow using several open-source image processing and text recognition packages1. The evaluation is performed using a specially developed variant, presented in this work, of the IAM handwriting database, where we achieve an average transcription accuracy of nearly 80% for pages containing both printed and handwritten text.
* big data, unstructured data, Optical Character Recognition (OCR), Handwritten Text Recognition (HTR), machine-printed text recognition, IAM handwriting database, TMIXT
SMS Spam Filtering using Probabilistic Topic Modelling and Stacked Denoising Autoencoder
Jun 17, 2016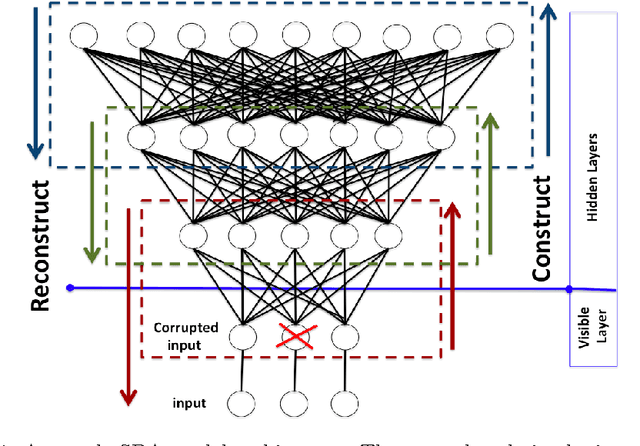



In This paper we present a novel approach to spam filtering and demonstrate its applicability with respect to SMS messages. Our approach requires minimum features engineering and a small set of la- belled data samples. Features are extracted using topic modelling based on latent Dirichlet allocation, and then a comprehensive data model is created using a Stacked Denoising Autoencoder (SDA). Topic modelling summarises the data providing ease of use and high interpretability by visualising the topics using word clouds. Given that the SMS messages can be regarded as either spam (unwanted) or ham (wanted), the SDA is able to model the messages and accurately discriminate between the two classes without the need for a pre-labelled training set. The results are compared against the state-of-the-art spam detection algorithms with our proposed approach achieving over 97% accuracy which compares favourably to the best reported algorithms presented in the literature.