 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMy Emotion on your face: The use of Facial Keypoint Detection to preserve Emotions in Latent Space Editing
May 09, 2025Generative Adversarial Network approaches such as StyleGAN/2 provide two key benefits: the ability to generate photo-realistic face images and possessing a semantically structured latent space from which these images are created. Many approaches have emerged for editing images derived from vectors in the latent space of a pre-trained StyleGAN/2 models by identifying semantically meaningful directions (e.g., gender or age) in the latent space. By moving the vector in a specific direction, the ideal result would only change the target feature while preserving all the other features. Providing an ideal data augmentation approach for gesture research as it could be used to generate numerous image variations whilst keeping the facial expressions intact. However, entanglement issues, where changing one feature inevitably affects other features, impacts the ability to preserve facial expressions. To address this, we propose the use of an addition to the loss function of a Facial Keypoint Detection model to restrict changes to the facial expressions. Building on top of an existing model, adding the proposed Human Face Landmark Detection (HFLD) loss, provided by a pre-trained Facial Keypoint Detection model, to the original loss function. We quantitatively and qualitatively evaluate the existing and our extended model, showing the effectiveness of our approach in addressing the entanglement issue and maintaining the facial expression. Our approach achieves up to 49% reduction in the change of emotion in our experiments. Moreover, we show the benefit of our approach by comparing with state-of-the-art models. By increasing the ability to preserve the facial gesture and expression during facial transformation, we present a way to create human face images with fixed expression but different appearances, making it a reliable data augmentation approach for Facial Gesture and Expression research.
Predicting the Performance of a Computing System with Deep Networks
Feb 27, 2023Predicting the performance and energy consumption of computing hardware is critical for many modern applications. This will inform procurement decisions, deployment decisions, and autonomic scaling. Existing approaches to understanding the performance of hardware largely focus around benchmarking -- leveraging standardised workloads which seek to be representative of an end-user's needs. Two key challenges are present; benchmark workloads may not be representative of an end-user's workload, and benchmark scores are not easily obtained for all hardware. Within this paper, we demonstrate the potential to build Deep Learning models to predict benchmark scores for unseen hardware. We undertake our evaluation with the openly available SPEC 2017 benchmark results. We evaluate three different networks, one fully-connected network along with two Convolutional Neural Networks (one bespoke and one ResNet inspired) and demonstrate impressive $R^2$ scores of 0.96, 0.98 and 0.94 respectively.
Siamese Neural Networks for Skin Cancer Classification and New Class Detection using Clinical and Dermoscopic Image Datasets
Dec 12, 2022



Skin cancer is the most common malignancy in the world. Automated skin cancer detection would significantly improve early detection rates and prevent deaths. To help with this aim, a number of datasets have been released which can be used to train Deep Learning systems - these have produced impressive results for classification. However, this only works for the classes they are trained on whilst they are incapable of identifying skin lesions from previously unseen classes, making them unconducive for clinical use. We could look to massively increase the datasets by including all possible skin lesions, though this would always leave out some classes. Instead, we evaluate Siamese Neural Networks (SNNs), which not only allows us to classify images of skin lesions, but also allow us to identify those images which are different from the trained classes - allowing us to determine that an image is not an example of our training classes. We evaluate SNNs on both dermoscopic and clinical images of skin lesions. We obtain top-1 classification accuracy levels of 74.33% and 85.61% on clinical and dermoscopic datasets, respectively. Although this is slightly lower than the state-of-the-art results, the SNN approach has the advantage that it can detect out-of-class examples. Our results highlight the potential of an SNN approach as well as pathways towards future clinical deployment.
Analysis of Reinforcement Learning for determining task replication in workflows
Sep 14, 2022

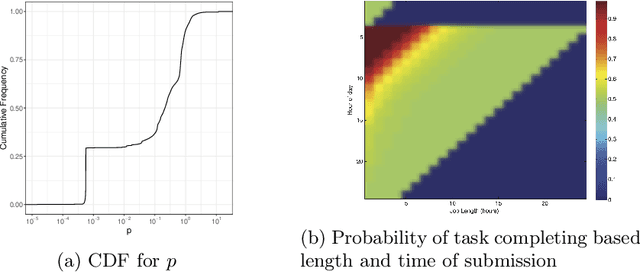
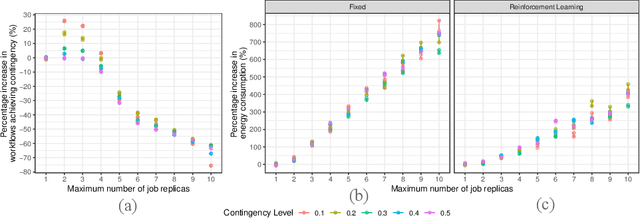
Executing workflows on volunteer computing resources where individual tasks may be forced to relinquish their resource for the resource's primary use leads to unpredictability and often significantly increases execution time. Task replication is one approach that can ameliorate this challenge. This comes at the expense of a potentially significant increase in system load and energy consumption. We propose the use of Reinforcement Learning (RL) such that a system may `learn' the `best' number of replicas to run to increase the number of workflows which complete promptly whilst minimising the additional workload on the system when replicas are not beneficial. We show, through simulation, that we can save 34% of the energy consumption using RL compared to a fixed number of replicas with only a 4% decrease in workflows achieving a pre-defined overhead bound.
Long-term Reproducibility for Neural Architecture Search
Jul 18, 2022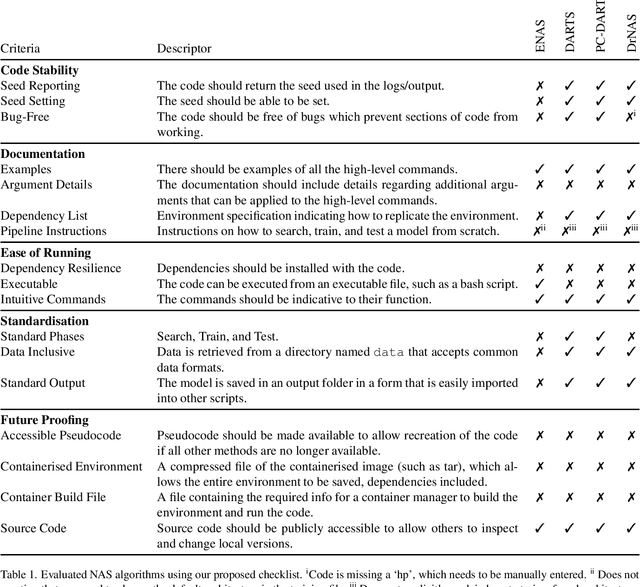
It is a sad reflection of modern academia that code is often ignored after publication -- there is no academic 'kudos' for bug fixes / maintenance. Code is often unavailable or, if available, contains bugs, is incomplete, or relies on out-of-date / unavailable libraries. This has a significant impact on reproducibility and general scientific progress. Neural Architecture Search (NAS) is no exception to this, with some prior work in reproducibility. However, we argue that these do not consider long-term reproducibility issues. We therefore propose a checklist for long-term NAS reproducibility. We evaluate our checklist against common NAS approaches along with proposing how we can retrospectively make these approaches more long-term reproducible.
SpiderNet: Hybrid Differentiable-Evolutionary Architecture Search via Train-Free Metrics
Apr 20, 2022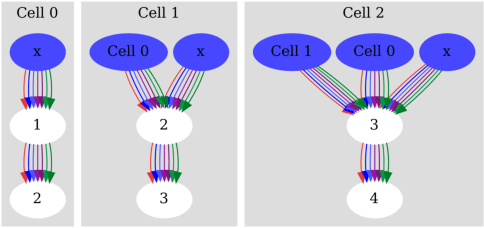

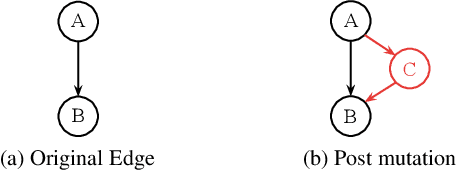
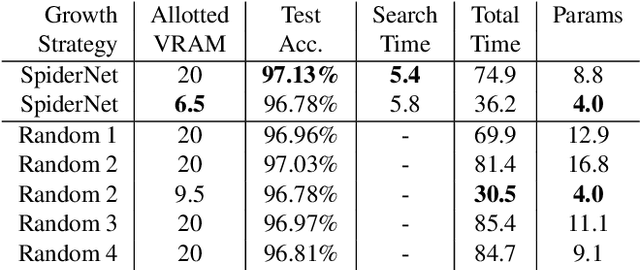
Neural Architecture Search (NAS) algorithms are intended to remove the burden of manual neural network design, and have shown to be capable of designing excellent models for a variety of well-known problems. However, these algorithms require a variety of design parameters in the form of user configuration or hard-coded decisions which limit the variety of networks that can be discovered. This means that NAS algorithms do not eliminate model design tuning, they instead merely shift the burden of where that tuning needs to be applied. In this paper, we present SpiderNet, a hybrid differentiable-evolutionary and hardware-aware algorithm that rapidly and efficiently produces state-of-the-art networks. More importantly, SpiderNet is a proof-of-concept of a minimally-configured NAS algorithm; the majority of design choices seen in other algorithms are incorporated into SpiderNet's dynamically-evolving search space, minimizing the number of user choices to just two: reduction cell count and initial channel count. SpiderNet produces models highly-competitive with the state-of-the-art, and outperforms random search in accuracy, runtime, memory size, and parameter count.
Application of deep learning to camera trap data for ecologists in planning / engineering -- Can captivity imagery train a model which generalises to the wild?
Nov 24, 2021
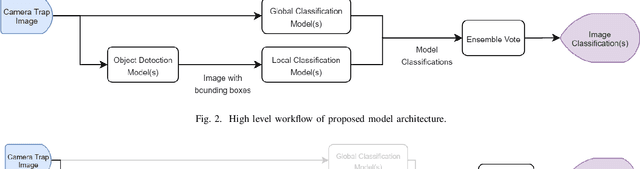


Understanding the abundance of a species is the first step towards understanding both its long-term sustainability and the impact that we may be having upon it. Ecologists use camera traps to remotely survey for the presence of specific animal species. Previous studies have shown that deep learning models can be trained to automatically detect and classify animals within camera trap imagery with high levels of confidence. However, the ability to train these models is reliant upon having enough high-quality training data. What happens when the animal is rare or the data sets are non-existent? This research proposes an approach of using images of rare animals in captivity (focusing on the Scottish wildcat) to generate the training dataset. We explore the challenges associated with generalising a model trained on captivity data when applied to data collected in the wild. The research is contextualised by the needs of ecologists in planning/engineering. Following precedents from other research, this project establishes an ensemble for object detection, image segmentation and image classification models which are then tested using different image manipulation and class structuring techniques to encourage model generalisation. The research concludes, in the context of Scottish wildcat, that models trained on captivity imagery cannot be generalised to wild camera trap imagery using existing techniques. However, final model performances based on a two-class model Wildcat vs Not Wildcat achieved an overall accuracy score of 81.6% and Wildcat accuracy score of 54.8% on a test set in which only 1% of images contained a wildcat. This suggests using captivity images is feasible with further research. This is the first research which attempts to generate a training set based on captivity data and the first to explore the development of such models in the context of ecologists in planning/engineering.
Not Half Bad: Exploring Half-Precision in Graph Convolutional Neural Networks
Oct 23, 2020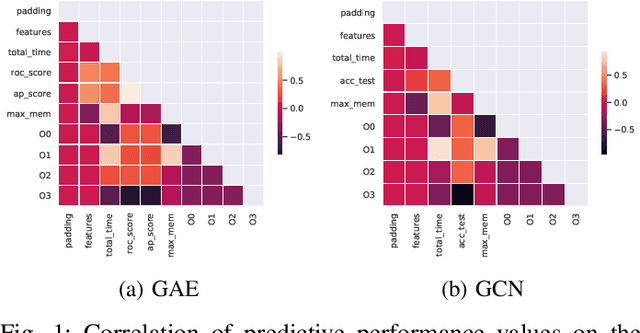
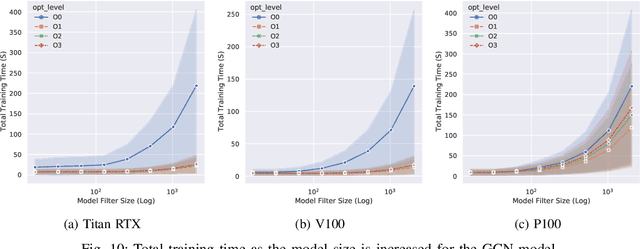
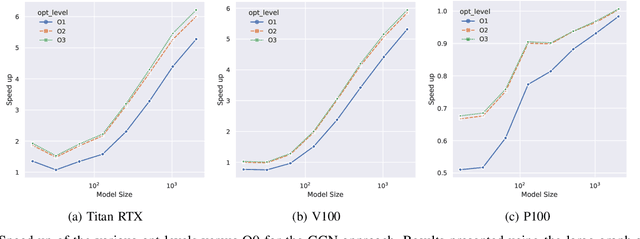
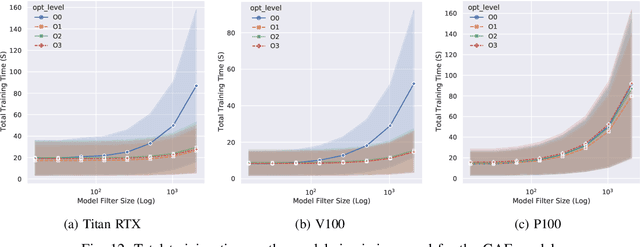
With the growing significance of graphs as an effective representation of data in numerous applications, efficient graph analysis using modern machine learning is receiving a growing level of attention. Deep learning approaches often operate over the entire adjacency matrix -- as the input and intermediate network layers are all designed in proportion to the size of the adjacency matrix -- leading to intensive computation and large memory requirements as the graph size increases. It is therefore desirable to identify efficient measures to reduce both run-time and memory requirements allowing for the analysis of the largest graphs possible. The use of reduced precision operations within the forward and backward passes of a deep neural network along with novel specialised hardware in modern GPUs can offer promising avenues towards efficiency. In this paper, we provide an in-depth exploration of the use of reduced-precision operations, easily integrable into the highly popular PyTorch framework, and an analysis of the effects of Tensor Cores on graph convolutional neural networks. We perform an extensive experimental evaluation of three GPU architectures and two widely-used graph analysis tasks (vertex classification and link prediction) using well-known benchmark and synthetically generated datasets. Thus allowing us to make important observations on the effects of reduced-precision operations and Tensor Cores on computational and memory usage of graph convolutional neural networks -- often neglected in the literature.
Rank over Class: The Untapped Potential of Ranking in Natural Language Processing
Sep 20, 2020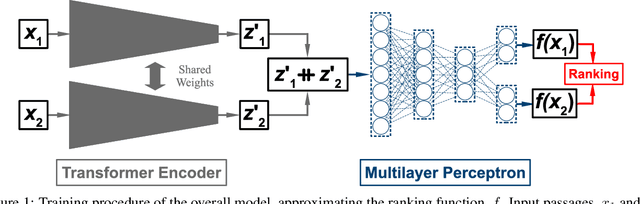
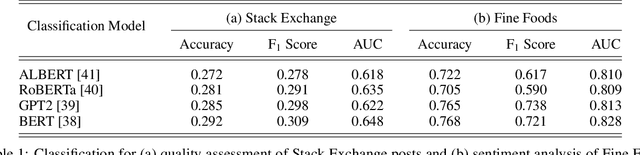
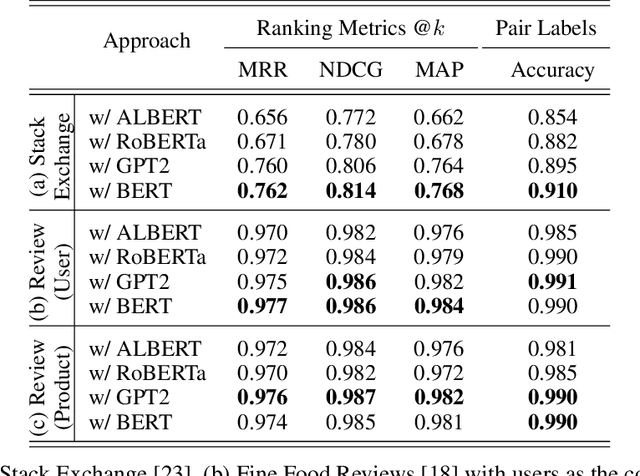
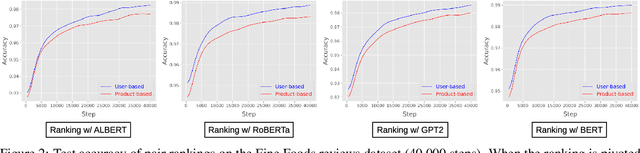
Text classification has long been a staple in natural language processing with applications spanning across sentiment analysis, online content tagging, recommender systems and spam detection. However, text classification, by nature, suffers from a variety of issues stemming from dataset imbalance, text ambiguity, subjectivity and the lack of linguistic context in the data. In this paper, we explore the use of text ranking, commonly used in information retrieval, to carry out challenging classification-based tasks. We propose a novel end-to-end ranking approach consisting of a Transformer network responsible for producing representations for a pair of text sequences, which are in turn passed into a context aggregating network outputting ranking scores used to determine an ordering to the sequences based on some notion of relevance. We perform numerous experiments on publicly-available datasets and investigate the possibility of applying our ranking approach to certain problems often addressed using classification. In an experiment on a heavily-skewed sentiment analysis dataset, converting ranking results to classification labels yields an approximately 22% improvement over state-of-the-art text classification, demonstrating the efficacy of text ranking over text classification in certain scenarios.
Bonsai-Net: One-Shot Neural Architecture Search via Differentiable Pruners
Jun 12, 2020

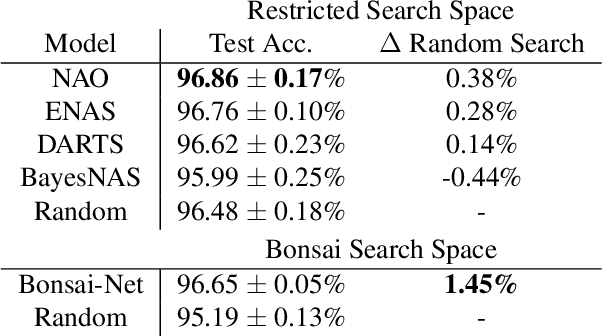

One-shot Neural Architecture Search (NAS) aims to minimize the computational expense of discovering state-of-the-art models. However, in the past year attention has been drawn to the comparable performance of naive random search across the same search spaces used by leading NAS algorithms. To address this, we explore the effects of drastically relaxing the NAS search space, and we present Bonsai-Net, an efficient one-shot NAS method to explore our relaxed search space. Bonsai-Net is built around a modified differential pruner and can consistently discover state-of-the-art architectures that are significantly better than random search with fewer parameters than other state-of-the-art methods. Additionally, Bonsai-Net performs simultaneous model search and training, dramatically reducing the total time it takes to generate fully-trained models from scratch.