 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights from the Use of Previously Unseen Neural Architecture Search Datasets
Apr 02, 2024The boundless possibility of neural networks which can be used to solve a problem -- each with different performance -- leads to a situation where a Deep Learning expert is required to identify the best neural network. This goes against the hope of removing the need for experts. Neural Architecture Search (NAS) offers a solution to this by automatically identifying the best architecture. However, to date, NAS work has focused on a small set of datasets which we argue are not representative of real-world problems. We introduce eight new datasets created for a series of NAS Challenges: AddNIST, Language, MultNIST, CIFARTile, Gutenberg, Isabella, GeoClassing, and Chesseract. These datasets and challenges are developed to direct attention to issues in NAS development and to encourage authors to consider how their models will perform on datasets unknown to them at development time. We present experimentation using standard Deep Learning methods as well as the best results from challenge participants.
SpiderNet: Hybrid Differentiable-Evolutionary Architecture Search via Train-Free Metrics
Apr 20, 2022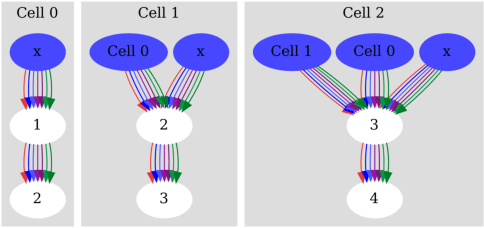

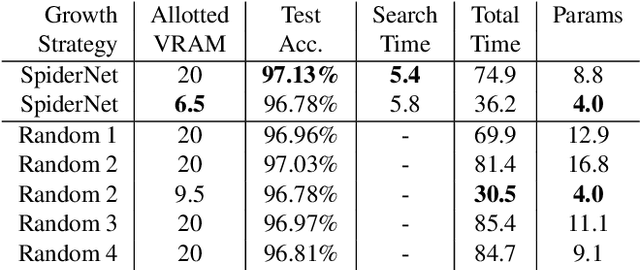
Neural Architecture Search (NAS) algorithms are intended to remove the burden of manual neural network design, and have shown to be capable of designing excellent models for a variety of well-known problems. However, these algorithms require a variety of design parameters in the form of user configuration or hard-coded decisions which limit the variety of networks that can be discovered. This means that NAS algorithms do not eliminate model design tuning, they instead merely shift the burden of where that tuning needs to be applied. In this paper, we present SpiderNet, a hybrid differentiable-evolutionary and hardware-aware algorithm that rapidly and efficiently produces state-of-the-art networks. More importantly, SpiderNet is a proof-of-concept of a minimally-configured NAS algorithm; the majority of design choices seen in other algorithms are incorporated into SpiderNet's dynamically-evolving search space, minimizing the number of user choices to just two: reduction cell count and initial channel count. SpiderNet produces models highly-competitive with the state-of-the-art, and outperforms random search in accuracy, runtime, memory size, and parameter count.
TrustyAI Explainability Toolkit
Apr 26, 2021



Artificial intelligence (AI) is becoming increasingly more popular and can be found in workplaces and homes around the world. However, how do we ensure trust in these systems? Regulation changes such as the GDPR mean that users have a right to understand how their data has been processed as well as saved. Therefore if, for example, you are denied a loan you have the right to ask why. This can be hard if the method for working this out uses "black box" machine learning techniques such as neural networks. TrustyAI is a new initiative which looks into explainable artificial intelligence (XAI) solutions to address trustworthiness in ML as well as decision services landscapes. In this paper we will look at how TrustyAI can support trust in decision services and predictive models. We investigate techniques such as LIME, SHAP and counterfactuals, benchmarking both LIME and counterfactual techniques against existing implementations. We also look into an extended version of SHAP, which supports background data selection to be evaluated based on quantitative data and allows for error bounds.
Bonsai-Net: One-Shot Neural Architecture Search via Differentiable Pruners
Jun 12, 2020

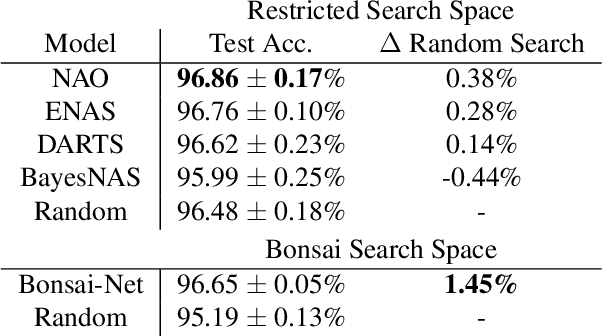

One-shot Neural Architecture Search (NAS) aims to minimize the computational expense of discovering state-of-the-art models. However, in the past year attention has been drawn to the comparable performance of naive random search across the same search spaces used by leading NAS algorithms. To address this, we explore the effects of drastically relaxing the NAS search space, and we present Bonsai-Net, an efficient one-shot NAS method to explore our relaxed search space. Bonsai-Net is built around a modified differential pruner and can consistently discover state-of-the-art architectures that are significantly better than random search with fewer parameters than other state-of-the-art methods. Additionally, Bonsai-Net performs simultaneous model search and training, dramatically reducing the total time it takes to generate fully-trained models from scratch.