 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Dense Representations with Inverted Indexes
Dec 04, 2023Nearly all implementations of top-$k$ retrieval with dense vector representations today take advantage of hierarchical navigable small-world network (HNSW) indexes. However, the generation of vector representations and efficiently searching large collections of vectors are distinct challenges that can be decoupled. In this work, we explore the contrarian approach of performing top-$k$ retrieval on dense vector representations using inverted indexes. We present experiments on the MS MARCO passage ranking dataset, evaluating three dimensions of interest: output quality, speed, and index size. Results show that searching dense representations using inverted indexes is possible. Our approach exhibits reasonable effectiveness with compact indexes, but is impractically slow. Thus, while workable, our solution does not provide a compelling tradeoff and is perhaps best characterized today as a "technical curiosity".
Vector Search with OpenAI Embeddings: Lucene Is All You Need
Aug 29, 2023We provide a reproducible, end-to-end demonstration of vector search with OpenAI embeddings using Lucene on the popular MS MARCO passage ranking test collection. The main goal of our work is to challenge the prevailing narrative that a dedicated vector store is necessary to take advantage of recent advances in deep neural networks as applied to search. Quite the contrary, we show that hierarchical navigable small-world network (HNSW) indexes in Lucene are adequate to provide vector search capabilities in a standard bi-encoder architecture. This suggests that, from a simple cost-benefit analysis, there does not appear to be a compelling reason to introduce a dedicated vector store into a modern "AI stack" for search, since such applications have already received substantial investments in existing, widely deployed infrastructure.
Anserini Gets Dense Retrieval: Integration of Lucene's HNSW Indexes
Apr 24, 2023
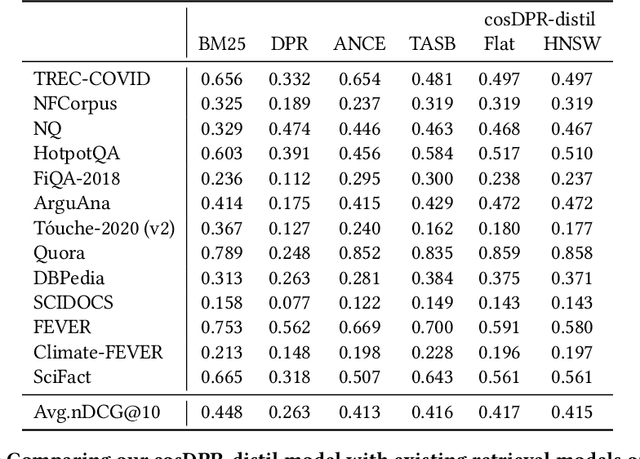

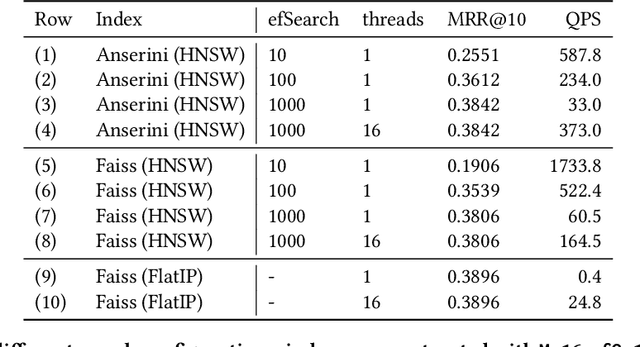
Anserini is a Lucene-based toolkit for reproducible information retrieval research in Java that has been gaining traction in the community. It provides retrieval capabilities for both "traditional" bag-of-words retrieval models such as BM25 as well as retrieval using learned sparse representations such as SPLADE. With Pyserini, which provides a Python interface to Anserini, users gain access to both sparse and dense retrieval models, as Pyserini implements bindings to the Faiss vector search library alongside Lucene inverted indexes in a uniform, consistent interface. Nevertheless, hybrid fusion techniques that integrate sparse and dense retrieval models need to stitch together results from two completely different "software stacks", which creates unnecessary complexities and inefficiencies. However, the introduction of HNSW indexes for dense vector search in Lucene promises the integration of both dense and sparse retrieval within a single software framework. We explore exactly this integration in the context of Anserini. Experiments on the MS MARCO passage and BEIR datasets show that our Anserini HNSW integration supports (reasonably) effective and (reasonably) efficient approximate nearest neighbor search for dense retrieval models, using only Lucene.
Effective Explanations for Entity Resolution Models
Apr 01, 2022

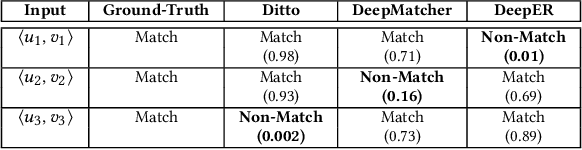
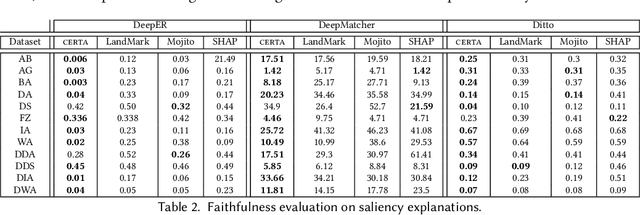
Entity resolution (ER) aims at matching records that refer to the same real-world entity. Although widely studied for the last 50 years, ER still represents a challenging data management problem, and several recent works have started to investigate the opportunity of applying deep learning (DL) techniques to solve this problem. In this paper, we study the fundamental problem of explainability of the DL solution for ER. Understanding the matching predictions of an ER solution is indeed crucial to assess the trustworthiness of the DL model and to discover its biases. We treat the DL model as a black box classifier and - while previous approaches to provide explanations for DL predictions are agnostic to the classification task. we propose the CERTA approach that is aware of the semantics of the ER problem. Our approach produces both saliency explanations, which associate each attribute with a saliency score, and counterfactual explanations, which provide examples of values that can flip the prediction. CERTA builds on a probabilistic framework that aims at computing the explanations evaluating the outcomes produced by using perturbed copies of the input records. We experimentally evaluate CERTA's explanations of state-of-the-art ER solutions based on DL models using publicly available datasets, and demonstrate the effectiveness of CERTA over recently proposed methods for this problem.
TrustyAI Explainability Toolkit
Apr 26, 2021



Artificial intelligence (AI) is becoming increasingly more popular and can be found in workplaces and homes around the world. However, how do we ensure trust in these systems? Regulation changes such as the GDPR mean that users have a right to understand how their data has been processed as well as saved. Therefore if, for example, you are denied a loan you have the right to ask why. This can be hard if the method for working this out uses "black box" machine learning techniques such as neural networks. TrustyAI is a new initiative which looks into explainable artificial intelligence (XAI) solutions to address trustworthiness in ML as well as decision services landscapes. In this paper we will look at how TrustyAI can support trust in decision services and predictive models. We investigate techniques such as LIME, SHAP and counterfactuals, benchmarking both LIME and counterfactual techniques against existing implementations. We also look into an extended version of SHAP, which supports background data selection to be evaluated based on quantitative data and allows for error bounds.
Affect Enriched Word Embeddings for News Information Retrieval
Sep 04, 2019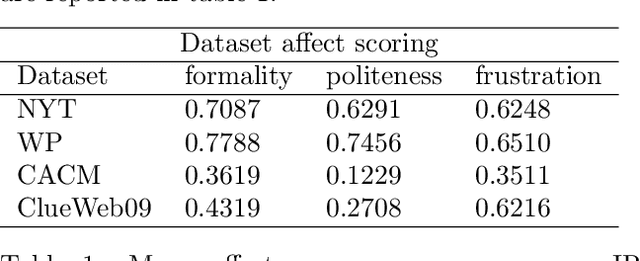
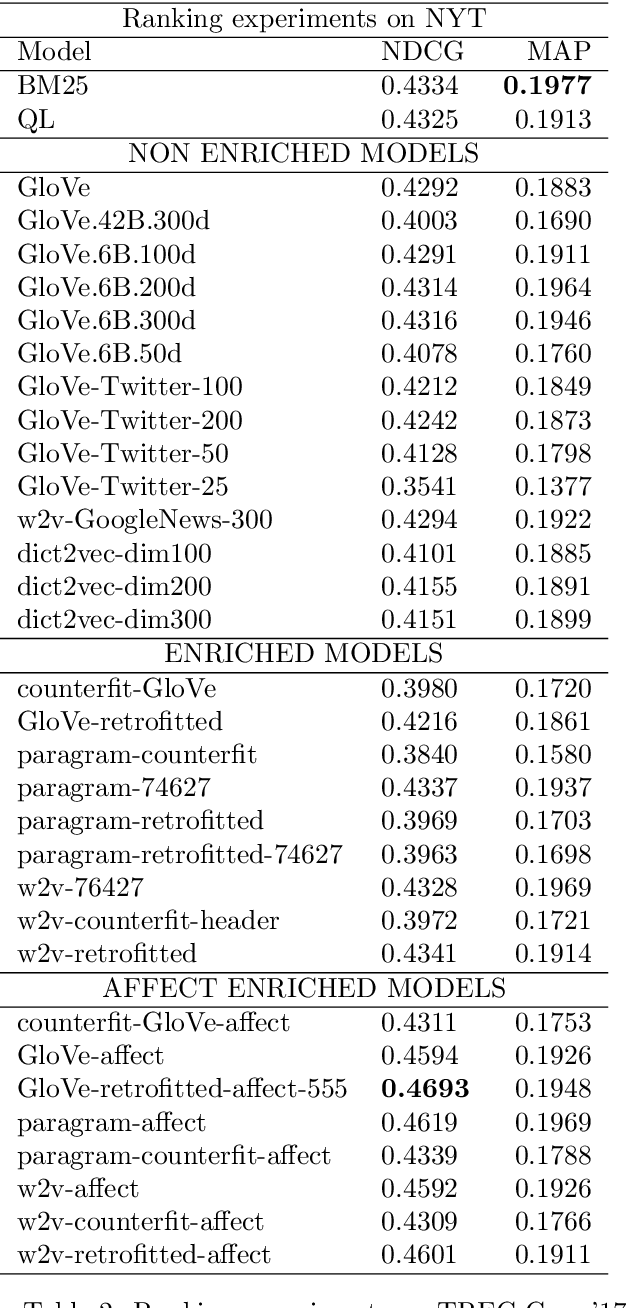
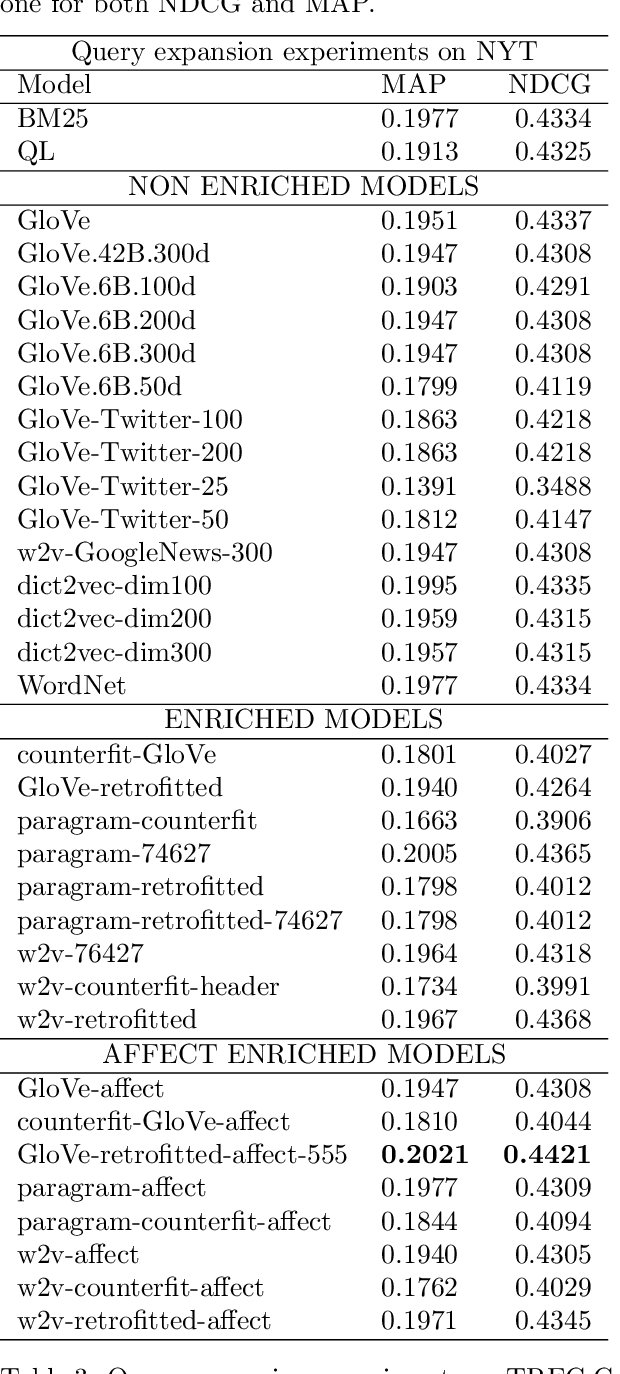
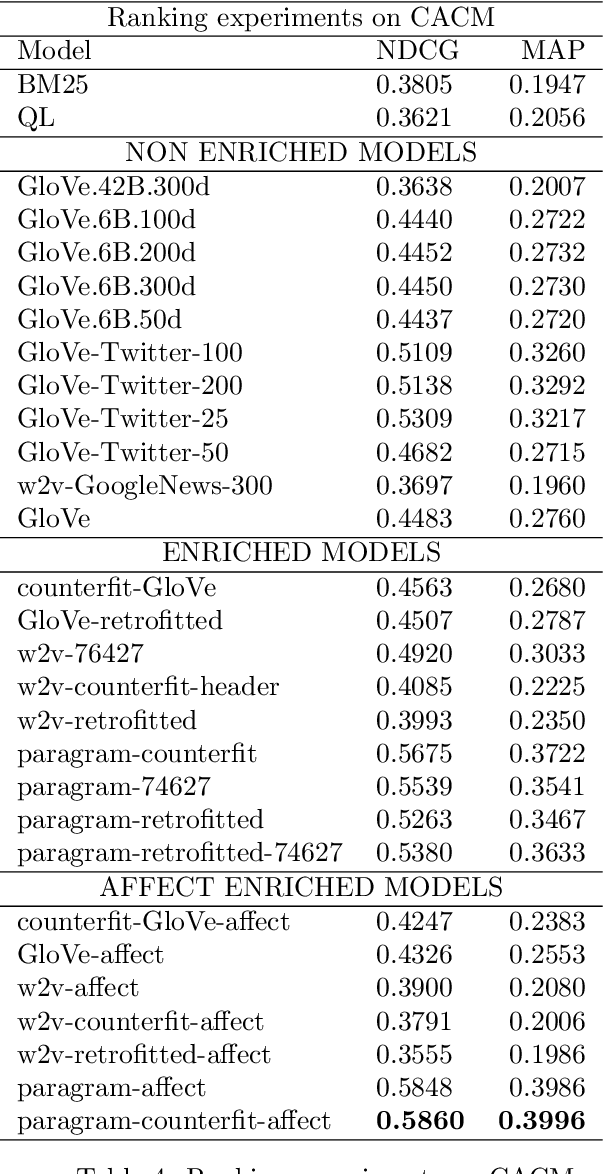
Distributed representations of words have shown to be useful to improve the effectiveness of IR systems in many sub-tasks like query expansion, retrieval and ranking. Algorithms like word2vec, GloVe and others are also key factors in many improvements in different NLP tasks. One common issue with such embedding models is that words like happy and sad appear in similar contexts and hence are wrongly clustered close in the embedding space. In this paper we leverage Aff2Vec, a set of word embeddings models which include affect information, in order to better capture the affect aspect in news text to achieve better results in information retrieval tasks, also such embeddings are less hit by the synonym/antonym issue. We evaluate their effectiveness on two IR related tasks (query expansion and ranking) over the New York Times dataset (TREC-core '17) comparing them against other word embeddings based models and classic ranking models.