 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Explanations for Entity Resolution Models
Apr 01, 2022

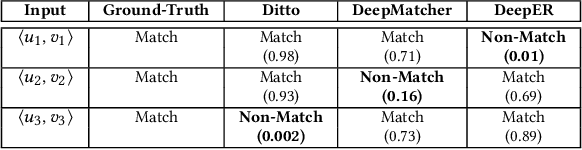
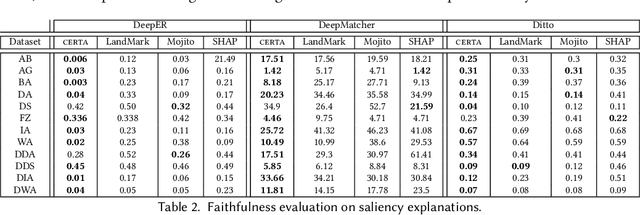
Entity resolution (ER) aims at matching records that refer to the same real-world entity. Although widely studied for the last 50 years, ER still represents a challenging data management problem, and several recent works have started to investigate the opportunity of applying deep learning (DL) techniques to solve this problem. In this paper, we study the fundamental problem of explainability of the DL solution for ER. Understanding the matching predictions of an ER solution is indeed crucial to assess the trustworthiness of the DL model and to discover its biases. We treat the DL model as a black box classifier and - while previous approaches to provide explanations for DL predictions are agnostic to the classification task. we propose the CERTA approach that is aware of the semantics of the ER problem. Our approach produces both saliency explanations, which associate each attribute with a saliency score, and counterfactual explanations, which provide examples of values that can flip the prediction. CERTA builds on a probabilistic framework that aims at computing the explanations evaluating the outcomes produced by using perturbed copies of the input records. We experimentally evaluate CERTA's explanations of state-of-the-art ER solutions based on DL models using publicly available datasets, and demonstrate the effectiveness of CERTA over recently proposed methods for this problem.
Knowledge Graph Embedding for Link Prediction: A Comparative Analysis
Mar 06, 2020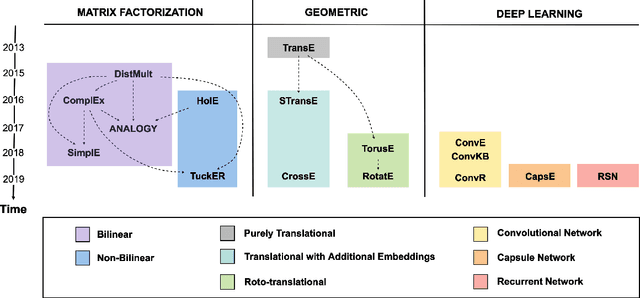
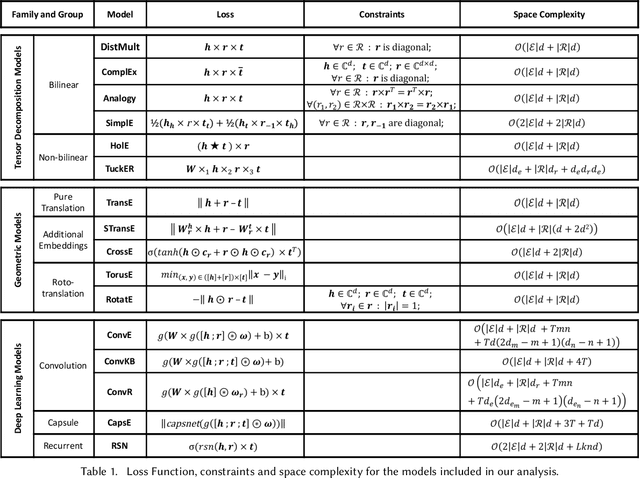
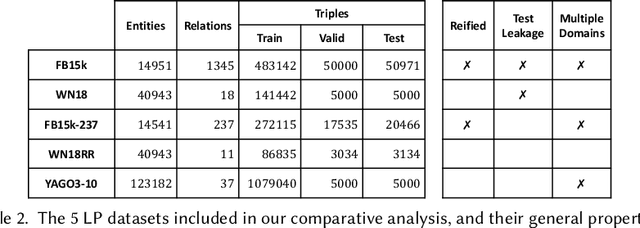
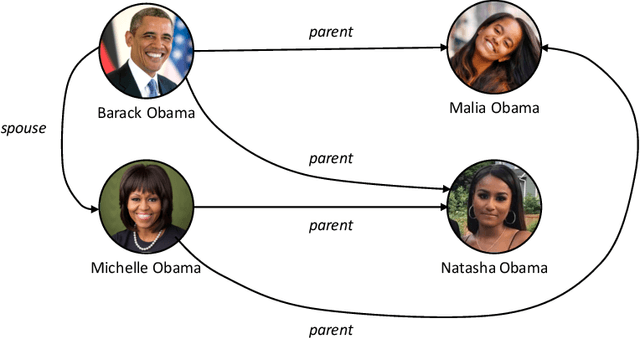
Knowledge Graphs (KGs) have found many applications in industry and academic settings, which in turn, have motivated considerable research efforts towards large-scale information extraction from a variety of sources. Despite such efforts, it is well known that even state-of-the-art KGs suffer from incompleteness. Link Prediction (LP), the task of predicting missing facts among entities already a KG, is a promising and widely studied task aimed at addressing KG incompleteness. Among the recent LP techniques, those based on KG embeddings have achieved very promising performances in some benchmarks. Despite the fast growing literature in the subject, insufficient attention has been paid to the effect of the various design choices in those methods. Moreover, the standard practice in this area is to report accuracy by aggregating over a large number of test facts in which some entities are over-represented; this allows LP methods to exhibit good performance by just attending to structural properties that include such entities, while ignoring the remaining majority of the KG. This analysis provides a comprehensive comparison of embedding-based LP methods, extending the dimensions of analysis beyond what is commonly available in the literature. We experimentally compare effectiveness and efficiency of 16 state-of-the-art methods, consider a rule-based baseline, and report detailed analysis over the most popular benchmarks in the literature.
Multikernel activation functions: formulation and a case study
Jan 29, 2019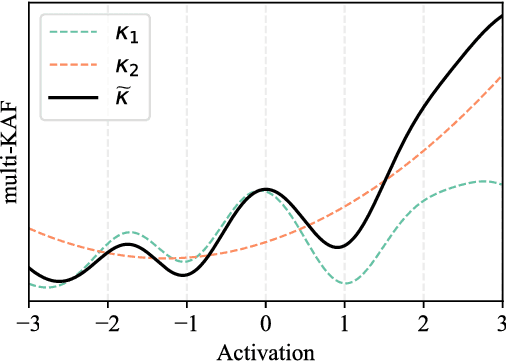


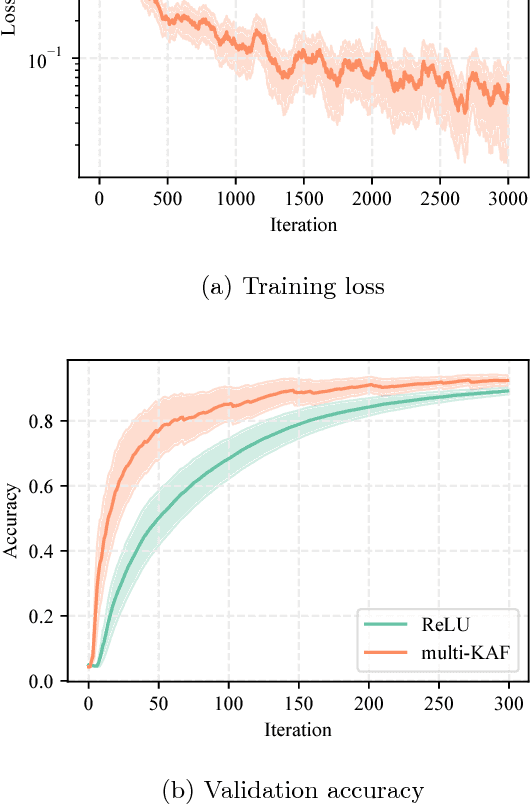
The design of activation functions is a growing research area in the field of neural networks. In particular, instead of using fixed point-wise functions (e.g., the rectified linear unit), several authors have proposed ways of learning these functions directly from the data in a non-parametric fashion. In this paper we focus on the kernel activation function (KAF), a recently proposed framework wherein each function is modeled as a one-dimensional kernel model, whose weights are adapted through standard backpropagation-based optimization. One drawback of KAFs is the need to select a single kernel function and its eventual hyper-parameters. To partially overcome this problem, we motivate an extension of the KAF model, in which multiple kernels are linearly combined at every neuron, inspired by the literature on multiple kernel learning. We provide an application of the resulting multi-KAF on a realistic use case, specifically handwritten Latin OCR, on a large dataset collected in the context of the `In Codice Ratio' project. Results show that multi-KAFs can improve the accuracy of the convolutional networks previously developed for the task, with faster convergence, even with a smaller number of overall parameters.
Towards Knowledge Discovery from the Vatican Secret Archives. In Codice Ratio -- Episode 1: Machine Transcription of the Manuscripts
Sep 12, 2018
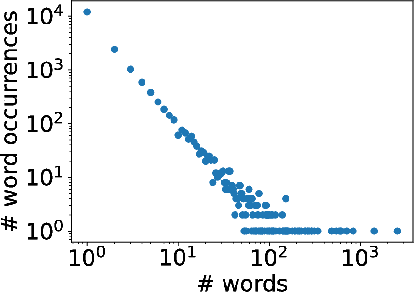
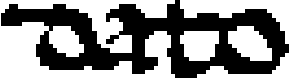

In Codice Ratio is a research project to study tools and techniques for analyzing the contents of historical documents conserved in the Vatican Secret Archives (VSA). In this paper, we present our efforts to develop a system to support the transcription of medieval manuscripts. The goal is to provide paleographers with a tool to reduce their efforts in transcribing large volumes, as those stored in the VSA, producing good transcriptions for significant portions of the manuscripts. We propose an original approach based on character segmentation. Our solution is able to deal with the dirty segmentation that inevitably occurs in handwritten documents. We use a convolutional neural network to recognize characters and language models to compose word transcriptions. Our approach requires minimal training efforts, making the transcription process more scalable as the production of training sets requires a few pages and can be easily crowdsourced. We have conducted experiments on manuscripts from the Vatican Registers, an unreleased corpus containing the correspondence of the popes. With training data produced by 120 high school students, our system has been able to produce good transcriptions that can be used by paleographers as a solid basis to speedup the transcription process at a large scale.