 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultikernel activation functions: formulation and a case study
Jan 29, 2019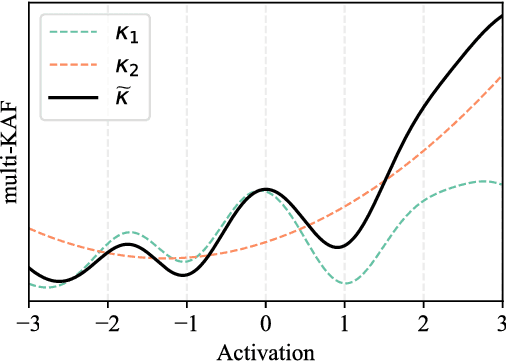


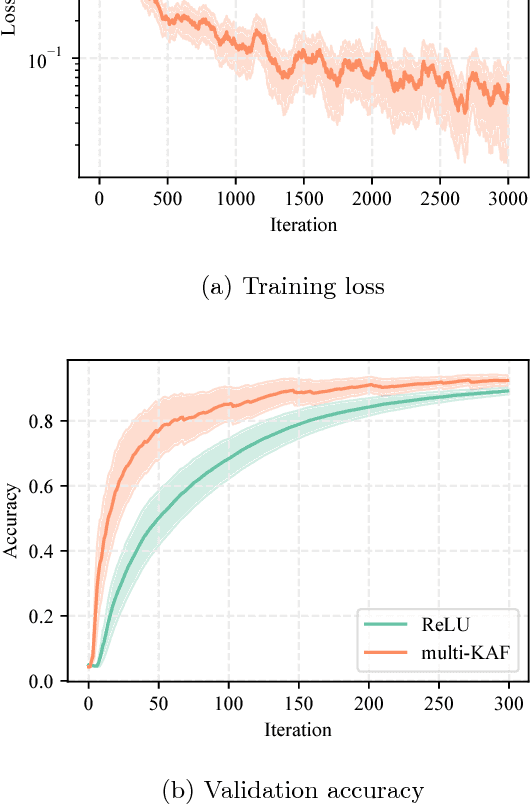
The design of activation functions is a growing research area in the field of neural networks. In particular, instead of using fixed point-wise functions (e.g., the rectified linear unit), several authors have proposed ways of learning these functions directly from the data in a non-parametric fashion. In this paper we focus on the kernel activation function (KAF), a recently proposed framework wherein each function is modeled as a one-dimensional kernel model, whose weights are adapted through standard backpropagation-based optimization. One drawback of KAFs is the need to select a single kernel function and its eventual hyper-parameters. To partially overcome this problem, we motivate an extension of the KAF model, in which multiple kernels are linearly combined at every neuron, inspired by the literature on multiple kernel learning. We provide an application of the resulting multi-KAF on a realistic use case, specifically handwritten Latin OCR, on a large dataset collected in the context of the `In Codice Ratio' project. Results show that multi-KAFs can improve the accuracy of the convolutional networks previously developed for the task, with faster convergence, even with a smaller number of overall parameters.
Towards Knowledge Discovery from the Vatican Secret Archives. In Codice Ratio -- Episode 1: Machine Transcription of the Manuscripts
Sep 12, 2018
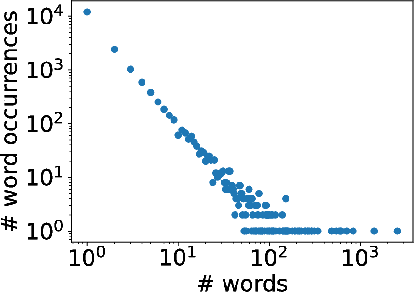

In Codice Ratio is a research project to study tools and techniques for analyzing the contents of historical documents conserved in the Vatican Secret Archives (VSA). In this paper, we present our efforts to develop a system to support the transcription of medieval manuscripts. The goal is to provide paleographers with a tool to reduce their efforts in transcribing large volumes, as those stored in the VSA, producing good transcriptions for significant portions of the manuscripts. We propose an original approach based on character segmentation. Our solution is able to deal with the dirty segmentation that inevitably occurs in handwritten documents. We use a convolutional neural network to recognize characters and language models to compose word transcriptions. Our approach requires minimal training efforts, making the transcription process more scalable as the production of training sets requires a few pages and can be easily crowdsourced. We have conducted experiments on manuscripts from the Vatican Registers, an unreleased corpus containing the correspondence of the popes. With training data produced by 120 high school students, our system has been able to produce good transcriptions that can be used by paleographers as a solid basis to speedup the transcription process at a large scale.