 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Embedding for Link Prediction: A Comparative Analysis
Mar 06, 2020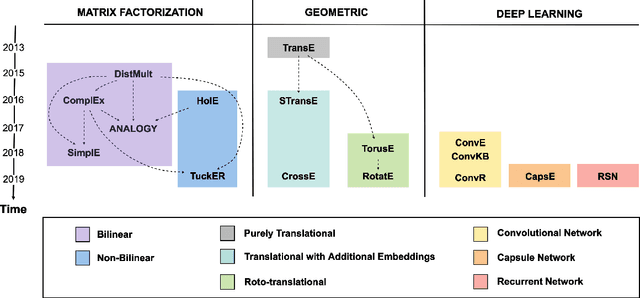
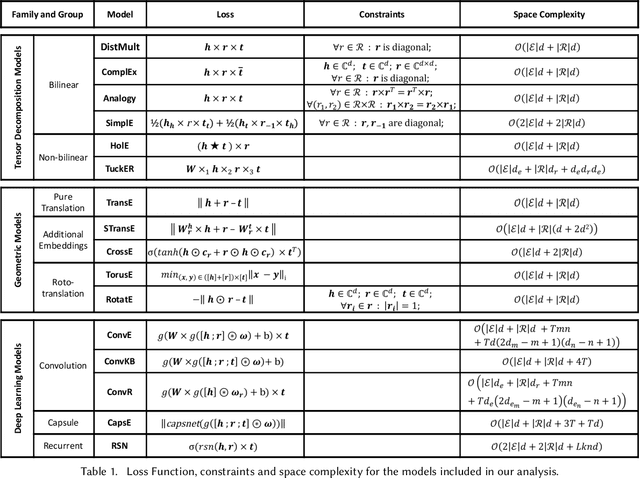
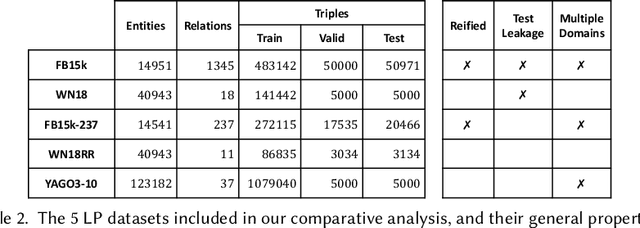
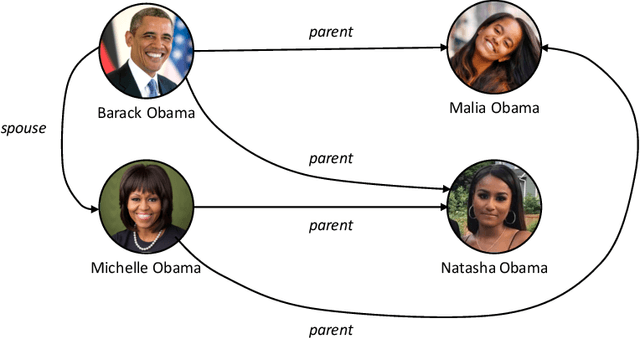
Knowledge Graphs (KGs) have found many applications in industry and academic settings, which in turn, have motivated considerable research efforts towards large-scale information extraction from a variety of sources. Despite such efforts, it is well known that even state-of-the-art KGs suffer from incompleteness. Link Prediction (LP), the task of predicting missing facts among entities already a KG, is a promising and widely studied task aimed at addressing KG incompleteness. Among the recent LP techniques, those based on KG embeddings have achieved very promising performances in some benchmarks. Despite the fast growing literature in the subject, insufficient attention has been paid to the effect of the various design choices in those methods. Moreover, the standard practice in this area is to report accuracy by aggregating over a large number of test facts in which some entities are over-represented; this allows LP methods to exhibit good performance by just attending to structural properties that include such entities, while ignoring the remaining majority of the KG. This analysis provides a comprehensive comparison of embedding-based LP methods, extending the dimensions of analysis beyond what is commonly available in the literature. We experimentally compare effectiveness and efficiency of 16 state-of-the-art methods, consider a rule-based baseline, and report detailed analysis over the most popular benchmarks in the literature.