 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnserini Gets Dense Retrieval: Integration of Lucene's HNSW Indexes
Paper and Code
Apr 24, 2023
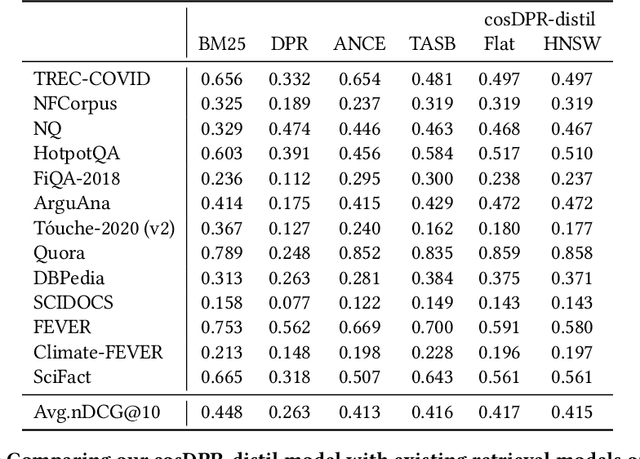

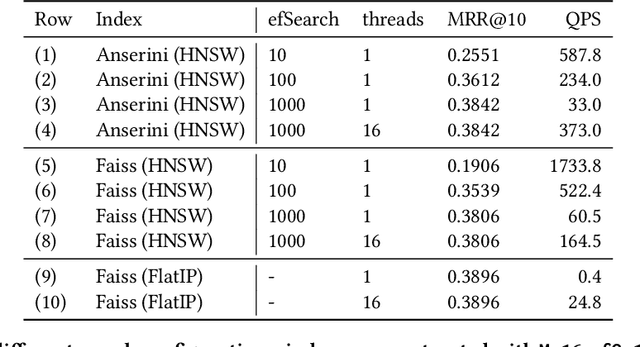
Anserini is a Lucene-based toolkit for reproducible information retrieval research in Java that has been gaining traction in the community. It provides retrieval capabilities for both "traditional" bag-of-words retrieval models such as BM25 as well as retrieval using learned sparse representations such as SPLADE. With Pyserini, which provides a Python interface to Anserini, users gain access to both sparse and dense retrieval models, as Pyserini implements bindings to the Faiss vector search library alongside Lucene inverted indexes in a uniform, consistent interface. Nevertheless, hybrid fusion techniques that integrate sparse and dense retrieval models need to stitch together results from two completely different "software stacks", which creates unnecessary complexities and inefficiencies. However, the introduction of HNSW indexes for dense vector search in Lucene promises the integration of both dense and sparse retrieval within a single software framework. We explore exactly this integration in the context of Anserini. Experiments on the MS MARCO passage and BEIR datasets show that our Anserini HNSW integration supports (reasonably) effective and (reasonably) efficient approximate nearest neighbor search for dense retrieval models, using only Lucene.