 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckup2Action: A Multimodal Clinical Check-up Report Dataset for Patient-Oriented Action Card Generation
May 13, 2026Clinical check-up reports are multimodal documents that combine page layouts, tables, numerical biomarkers, abnormality flags, imaging findings, and domain-specific terminology. Such heterogeneous evidence is difficult for laypersons to interpret and translate into concrete follow-up actions. Although large language models show promise in medical summarisation and triage support, their ability to generate safe, prioritised, and patient-oriented actions from multimodal check-up reports remains under-benchmarked. We present \textbf{Checkup2Action}, a multimodal clinical check-up report dataset and benchmark for structured \textit{Action Card} generation. Each card describes one clinically relevant issue and specifies its priority, recommended department, follow-up time window, patient-facing explanation, and questions for clinicians, while avoiding diagnostic or treatment-prescriptive claims. The dataset contains 2,000 de-identified real-world check-up reports covering demographic information, physical examinations, laboratory tests, cardiovascular assessments, and imaging-related evidence. We formulate checkup-to-action generation as a constrained structured generation task and introduce an evaluation protocol covering issue coverage and precision, priority consistency, department and time recommendation accuracy, action complexity, usefulness, readability, and safety compliance. Experiments with general-purpose and medical large language models reveal clear trade-offs between issue coverage, action correctness, conciseness, and safety alignment. Checkup2Action provides a new multimodal benchmark for evaluating patient-oriented reasoning over clinical check-up reports.
Mind2Drive: Predicting Driver Intentions from EEG in Real-world On-Road Driving
Apr 21, 2026Predicting driver intention from neurophysiological signals offers a promising pathway for enhancing proactive safety in advanced driver assistance systems, yet remains challenging in real-world driving due to EEG signal non-stationarity and the complexity of cognitive-motor preparation. This study proposes and evaluates an EEG-based driver intention prediction framework using a synchronised multi-sensor platform integrated into a real electric vehicle. A real-world on-road dataset was collected across 32 driving sessions, and 12 deep learning architectures were evaluated under consistent experimental conditions. Among the evaluated architectures, TSCeption achieved the highest average accuracy (0.907) and Macro-F1 score (0.901). The proposed framework demonstrates strong temporal stability, maintaining robust decoding performance up to 1000 ms before manoeuvre execution with minimal degradation. Furthermore, additional analyses reveal that minimal EEG preprocessing outperforms artefact-handling pipelines, and prediction performance peaks within a 400-600 ms interval, corresponding to a critical neural preparatory phase preceding driving manoeuvres. Overall, these findings support the feasibility of early and stable EEG-based driver intention decoding under real-world on-road conditions. Code: https://github.com/galosaimi/Mind2Drive.
Motion-Adaptive Multi-Scale Temporal Modelling with Skeleton-Constrained Spatial Graphs for Efficient 3D Human Pose Estimation
Apr 04, 2026Accurate 3D human pose estimation from monocular videos requires effective modelling of complex spatial and temporal dependencies. However, existing methods often face challenges in efficiency and adaptability when modelling spatial and temporal dependencies, particularly under dense attention or fixed modelling schemes. In this work, we propose MASC-Pose, a Motion-Adaptive multi-scale temporal modelling framework with Skeleton-Constrained spatial graphs for efficient 3D human pose estimation. Specifically, it introduces an Adaptive Multi-scale Temporal Modelling (AMTM) module to adaptively capture heterogeneous motion dynamics at different temporal scales, together with a Skeleton-constrained Adaptive GCN (SAGCN) for joint-specific spatial interaction modelling. By jointly enabling adaptive temporal reasoning and efficient spatial aggregation, our method achieves strong accuracy with high computational efficiency. Extensive experiments on Human3.6M and MPI-INF-3DHP datasets demonstrate the effectiveness of our approach.
ART: Adaptive Relational Transformer for Pedestrian Trajectory Prediction with Temporal-Aware Relations
Apr 04, 2026Accurate prediction of real-world pedestrian trajectories is crucial for a wide range of robot-related applications. Recent approaches typically adopt graph-based or transformer-based frameworks to model interactions. Despite their effectiveness, these methods either introduce unnecessary computational overhead or struggle to represent the diverse and time-varying characteristics of human interactions. In this work, we present an Adaptive Relational Transformer (ART), which introduces a Temporal-Aware Relation Graph (TARG) to explicitly capture the evolution of pairwise interactions and an Adaptive Interaction Pruning (AIP) mechanism to reduce redundant computations efficiently. Extensive evaluations on ETH/UCY and NBA benchmarks show that ART delivers state-of-the-art accuracy with high computational efficiency.
VRUD: A Drone Dataset for Complex Vehicle-VRU Interactions within Mixed Traffic
Apr 01, 2026The Operational Design Domain (ODD) of urbanoriented Level 4 (L4) autonomous driving, especially for autonomous robotaxis, confronts formidable challenges in complex urban mixed traffic environments. These challenges stem mainly from the high density of Vulnerable Road Users (VRUs) and their highly uncertain and unpredictable interaction behaviors. However, existing open-source datasets predominantly focus on structured scenarios such as highways or regulated intersections, leaving a critical gap in data representing chaotic, unstructured urban environments. To address this, this paper proposes an efficient, high-precision method for constructing drone-based datasets and establishes the Vehicle-Vulnerable Road User Interaction Dataset (VRUD), as illustrated in Figure 1. Distinct from prior works, VRUD is collected from typical "Urban Villages" in Shenzhen, characterized by loose traffic supervision and extreme occlusion. The dataset comprises 4 hours of 4K/30Hz recording, containing 11,479 VRU trajectories and 1,939 vehicle trajectories. A key characteristic of VRUD is its composition: VRUs account for about 87% of all traffic participants, significantly exceeding the proportions in existing benchmarks. Furthermore, unlike datasets that only provide raw trajectories, we extracted 4,002 multi-agent interaction scenarios based on a novel Vector Time to Collision (VTTC) threshold, supported by standard OpenDRIVE HD maps. This study provides valuable, rare edge-case resources for enhancing the safety performance of ADS in complex, unstructured urban environments. To facilitate further research, we have made the VRUD dataset open-source at: https://zzi4.github.io/VRUD/.
EEG-Driven Intention Decoding: Offline Deep Learning Benchmarking on a Robotic Rover
Feb 23, 2026Brain-computer interfaces (BCIs) provide a hands-free control modality for mobile robotics, yet decoding user intent during real-world navigation remains challenging. This work presents a brain-robot control framework for offline decoding of driving commands during robotic rover operation. A 4WD Rover Pro platform was remotely operated by 12 participants who navigated a predefined route using a joystick, executing the commands forward, reverse, left, right, and stop. Electroencephalogram (EEG) signals were recorded with a 16-channel OpenBCI cap and aligned with motor actions at Delta = 0 ms and future prediction horizons (Delta > 0 ms). After preprocessing, several deep learning models were benchmarked, including convolutional neural networks, recurrent neural networks, and Transformer architectures. ShallowConvNet achieved the highest performance for both action prediction and intent prediction. By combining real-world robotic control with multi-horizon EEG intention decoding, this study introduces a reproducible benchmark and reveals key design insights for predictive deep learning-based BCI systems.
KD360-VoxelBEV: LiDAR and 360-degree Camera Cross Modality Knowledge Distillation for Bird's-Eye-View Segmentation
Dec 17, 2025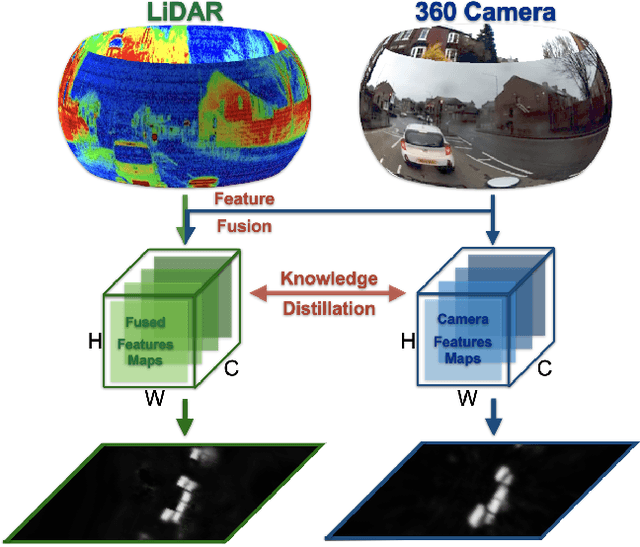
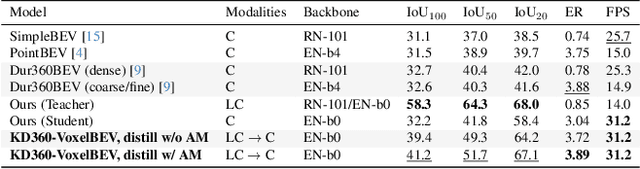


We present the first cross-modality distillation framework specifically tailored for single-panoramic-camera Bird's-Eye-View (BEV) segmentation. Our approach leverages a novel LiDAR image representation fused from range, intensity and ambient channels, together with a voxel-aligned view transformer that preserves spatial fidelity while enabling efficient BEV processing. During training, a high-capacity LiDAR and camera fusion Teacher network extracts both rich spatial and semantic features for cross-modality knowledge distillation into a lightweight Student network that relies solely on a single 360-degree panoramic camera image. Extensive experiments on the Dur360BEV dataset demonstrate that our teacher model significantly outperforms existing camera-based BEV segmentation methods, achieving a 25.6\% IoU improvement. Meanwhile, the distilled Student network attains competitive performance with an 8.5\% IoU gain and state-of-the-art inference speed of 31.2 FPS. Moreover, evaluations on KITTI-360 (two fisheye cameras) confirm that our distillation framework generalises to diverse camera setups, underscoring its feasibility and robustness. This approach reduces sensor complexity and deployment costs while providing a practical solution for efficient, low-cost BEV segmentation in real-world autonomous driving.
BcQLM: Efficient Vision-Language Understanding with Distilled Q-Gated Cross-Modal Fusion
Sep 10, 2025As multimodal large language models (MLLMs) advance, their large-scale architectures pose challenges for deployment in resource-constrained environments. In the age of large models, where energy efficiency, computational scalability and environmental sustainability are paramount, the development of lightweight and high-performance models is critical for real-world applications. As such, we propose a lightweight MLLM framework for end-to-end visual question answering. Our proposed approach centres on BreezeCLIP, a compact yet powerful vision-language encoder optimised for efficient multimodal understanding. With only 1.2 billion parameters overall, our model significantly reduces computational cost while achieving performance comparable to standard-size MLLMs. Experiments conducted on multiple datasets further validate its effectiveness in balancing accuracy and efficiency. The modular and extensible design enables generalisation to broader multimodal tasks. The proposed lightweight vision-language framework is denoted as BcQLM (BreezeCLIP-enhanced Q-Gated Multimodal Language Model). It offers a promising path toward deployable MLLMs under practical hardware constraints. The source code is available at https://github.com/thico0224/BcQLM.
FineCausal: A Causal-Based Framework for Interpretable Fine-Grained Action Quality Assessment
Mar 31, 2025Action quality assessment (AQA) is critical for evaluating athletic performance, informing training strategies, and ensuring safety in competitive sports. However, existing deep learning approaches often operate as black boxes and are vulnerable to spurious correlations, limiting both their reliability and interpretability. In this paper, we introduce FineCausal, a novel causal-based framework that achieves state-of-the-art performance on the FineDiving-HM dataset. Our approach leverages a Graph Attention Network-based causal intervention module to disentangle human-centric foreground cues from background confounders, and incorporates a temporal causal attention module to capture fine-grained temporal dependencies across action stages. This dual-module strategy enables FineCausal to generate detailed spatio-temporal representations that not only achieve state-of-the-art scoring performance but also provide transparent, interpretable feedback on which features drive the assessment. Despite its strong performance, FineCausal requires extensive expert knowledge to define causal structures and depends on high-quality annotations, challenges that we discuss and address as future research directions. Code is available at https://github.com/Harrison21/FineCausal.
Deep Learning-Enhanced Visual Monitoring in Hazardous Underwater Environments with a Swarm of Micro-Robots
Mar 04, 2025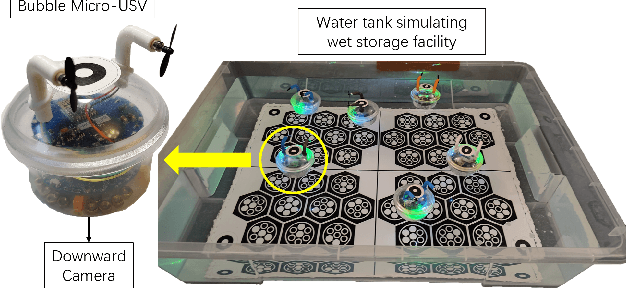
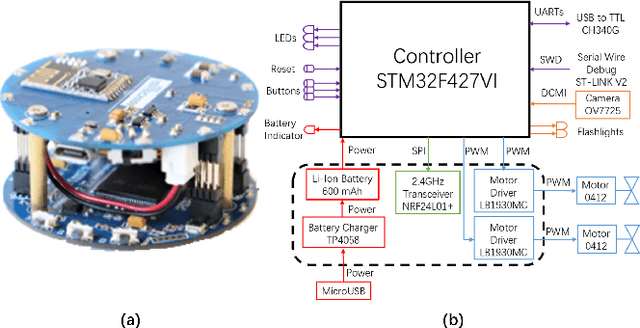
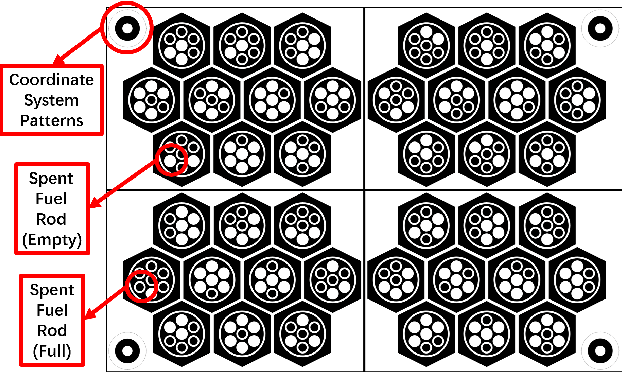
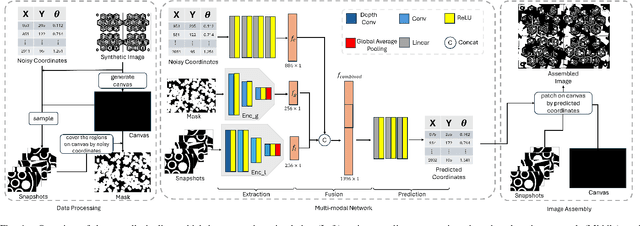
Long-term monitoring and exploration of extreme environments, such as underwater storage facilities, is costly, labor-intensive, and hazardous. Automating this process with low-cost, collaborative robots can greatly improve efficiency. These robots capture images from different positions, which must be processed simultaneously to create a spatio-temporal model of the facility. In this paper, we propose a novel approach that integrates data simulation, a multi-modal deep learning network for coordinate prediction, and image reassembly to address the challenges posed by environmental disturbances causing drift and rotation in the robots' positions and orientations. Our approach enhances the precision of alignment in noisy environments by integrating visual information from snapshots, global positional context from masks, and noisy coordinates. We validate our method through extensive experiments using synthetic data that simulate real-world robotic operations in underwater settings. The results demonstrate very high coordinate prediction accuracy and plausible image assembly, indicating the real-world applicability of our approach. The assembled images provide clear and coherent views of the underwater environment for effective monitoring and inspection, showcasing the potential for broader use in extreme settings, further contributing to improved safety, efficiency, and cost reduction in hazardous field monitoring. Code is available on https://github.com/ChrisChen1023/Micro-Robot-Swarm.