 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEM-Net: Efficient Pixel Modelling for image inpainting with Spatially Enhanced SSM
Nov 10, 2024



Image inpainting aims to repair a partially damaged image based on the information from known regions of the images. \revise{Achieving semantically plausible inpainting results is particularly challenging because it requires the reconstructed regions to exhibit similar patterns to the semanticly consistent regions}. This requires a model with a strong capacity to capture long-range dependencies. Existing models struggle in this regard due to the slow growth of receptive field for Convolutional Neural Networks (CNNs) based methods and patch-level interactions in Transformer-based methods, which are ineffective for capturing long-range dependencies. Motivated by this, we propose SEM-Net, a novel visual State Space model (SSM) vision network, modelling corrupted images at the pixel level while capturing long-range dependencies (LRDs) in state space, achieving a linear computational complexity. To address the inherent lack of spatial awareness in SSM, we introduce the Snake Mamba Block (SMB) and Spatially-Enhanced Feedforward Network. These innovations enable SEM-Net to outperform state-of-the-art inpainting methods on two distinct datasets, showing significant improvements in capturing LRDs and enhancement in spatial consistency. Additionally, SEM-Net achieves state-of-the-art performance on motion deblurring, demonstrating its generalizability. Our source code will be released in https://github.com/ChrisChen1023/SEM-Net.
MxT: Mamba x Transformer for Image Inpainting
Jul 26, 2024Image inpainting, or image completion, is a crucial task in computer vision that aims to restore missing or damaged regions of images with semantically coherent content. This technique requires a precise balance of local texture replication and global contextual understanding to ensure the restored image integrates seamlessly with its surroundings. Traditional methods using Convolutional Neural Networks (CNNs) are effective at capturing local patterns but often struggle with broader contextual relationships due to the limited receptive fields. Recent advancements have incorporated transformers, leveraging their ability to understand global interactions. However, these methods face computational inefficiencies and struggle to maintain fine-grained details. To overcome these challenges, we introduce MxT composed of the proposed Hybrid Module (HM), which combines Mamba with the transformer in a synergistic manner. Mamba is adept at efficiently processing long sequences with linear computational costs, making it an ideal complement to the transformer for handling long-scale data interactions. Our HM facilitates dual-level interaction learning at both pixel and patch levels, greatly enhancing the model to reconstruct images with high quality and contextual accuracy. We evaluate MxT on the widely-used CelebA-HQ and Places2-standard datasets, where it consistently outperformed existing state-of-the-art methods.
OAT: Object-Level Attention Transformer for Gaze Scanpath Prediction
Jul 18, 2024Visual search is important in our daily life. The efficient allocation of visual attention is critical to effectively complete visual search tasks. Prior research has predominantly modelled the spatial allocation of visual attention in images at the pixel level, e.g. using a saliency map. However, emerging evidence shows that visual attention is guided by objects rather than pixel intensities. This paper introduces the Object-level Attention Transformer (OAT), which predicts human scanpaths as they search for a target object within a cluttered scene of distractors. OAT uses an encoder-decoder architecture. The encoder captures information about the position and appearance of the objects within an image and about the target. The decoder predicts the gaze scanpath as a sequence of object fixations, by integrating output features from both the encoder and decoder. We also propose a new positional encoding that better reflects spatial relationships between objects. We evaluated OAT on the Amazon book cover dataset and a new dataset for visual search that we collected. OAT's predicted gaze scanpaths align more closely with human gaze patterns, compared to predictions by algorithms based on spatial attention on both established metrics and a novel behavioural-based metric. Our results demonstrate the generalization ability of OAT, as it accurately predicts human scanpaths for unseen layouts and target objects.
Pose-based Tremor Type and Level Analysis for Parkinson's Disease from Video
Dec 21, 2023Purpose:Current methods for diagnosis of PD rely on clinical examination. The accuracy of diagnosis ranges between 73% and 84%, and is influenced by the experience of the clinical assessor. Hence, an automatic, effective and interpretable supporting system for PD symptom identification would support clinicians in making more robust PD diagnostic decisions. Methods: We propose to analyze Parkinson's tremor (PT) to support the analysis of PD, since PT is one of the most typical symptoms of PD with broad generalizability. To realize the idea, we present SPA-PTA, a deep learning-based PT classification and severity estimation system that takes consumer-grade videos of front-facing humans as input. The core of the system is a novel attention module with a lightweight pyramidal channel-squeezing-fusion architecture that effectively extracts relevant PT information and filters noise. It enhances modeling performance while improving system interpretability. Results:We validate our system via individual-based leave-one-out cross-validation on two tasks: the PT classification task and the tremor severity rating estimation task. Our system presents a 91.3% accuracy and 80.0% F1-score in classifying PT with non-PT class, while providing a 76.4% accuracy and 76.7% F1-score in more complex multiclass tremor rating classification task. Conclusion: Our system offers a cost-effective PT classification and tremor severity estimation results as warning signs of PD for undiagnosed patients with PT symptoms. In addition, it provides a potential solution for supporting PD diagnosis in regions with limited clinical resources.
Correlation-Distance Graph Learning for Treatment Response Prediction from rs-fMRI
Nov 17, 2023



Resting-state fMRI (rs-fMRI) functional connectivity (FC) analysis provides valuable insights into the relationships between different brain regions and their potential implications for neurological or psychiatric disorders. However, specific design efforts to predict treatment response from rs-fMRI remain limited due to difficulties in understanding the current brain state and the underlying mechanisms driving the observed patterns, which limited the clinical application of rs-fMRI. To overcome that, we propose a graph learning framework that captures comprehensive features by integrating both correlation and distance-based similarity measures under a contrastive loss. This approach results in a more expressive framework that captures brain dynamic features at different scales and enables more accurate prediction of treatment response. Our experiments on the chronic pain and depersonalization disorder datasets demonstrate that our proposed method outperforms current methods in different scenarios. To the best of our knowledge, we are the first to explore the integration of distance-based and correlation-based neural similarity into graph learning for treatment response prediction.
Unifying Human Motion Synthesis and Style Transfer with Denoising Diffusion Probabilistic Models
Dec 16, 2022Generating realistic motions for digital humans is a core but challenging part of computer animations and games, as human motions are both diverse in content and rich in styles. While the latest deep learning approaches have made significant advancements in this domain, they mostly consider motion synthesis and style manipulation as two separate problems. This is mainly due to the challenge of learning both motion contents that account for the inter-class behaviour and styles that account for the intra-class behaviour effectively in a common representation. To tackle this challenge, we propose a denoising diffusion probabilistic model solution for styled motion synthesis. As diffusion models have a high capacity brought by the injection of stochasticity, we can represent both inter-class motion content and intra-class style behaviour in the same latent. This results in an integrated, end-to-end trained pipeline that facilitates the generation of optimal motion and exploration of content-style coupled latent space. To achieve high-quality results, we design a multi-task architecture of diffusion model that strategically generates aspects of human motions for local guidance. We also design adversarial and physical regulations for global guidance. We demonstrate superior performance with quantitative and qualitative results and validate the effectiveness of our multi-task architecture.
Denoising Diffusion Probabilistic Models for Styled Walking Synthesis
Sep 29, 2022

Generating realistic motions for digital humans is time-consuming for many graphics applications. Data-driven motion synthesis approaches have seen solid progress in recent years through deep generative models. These results offer high-quality motions but typically suffer in motion style diversity. For the first time, we propose a framework using the denoising diffusion probabilistic model (DDPM) to synthesize styled human motions, integrating two tasks into one pipeline with increased style diversity compared with traditional motion synthesis methods. Experimental results show that our system can generate high-quality and diverse walking motions.
CP-AGCN: Pytorch-based Attention Informed Graph Convolutional Network for Identifying Infants at Risk of Cerebral Palsy
Sep 06, 2022
Early prediction is clinically considered one of the essential parts of cerebral palsy (CP) treatment. We propose to implement a low-cost and interpretable classification system for supporting CP prediction based on General Movement Assessment (GMA). We design a Pytorch-based attention-informed graph convolutional network to early identify infants at risk of CP from skeletal data extracted from RGB videos. We also design a frequency-binning module for learning the CP movements in the frequency domain while filtering noise. Our system only requires consumer-grade RGB videos for training to support interactive-time CP prediction by providing an interpretable CP classification result.
Pose-based Tremor Classification for Parkinson's Disease Diagnosis from Video
Jul 14, 2022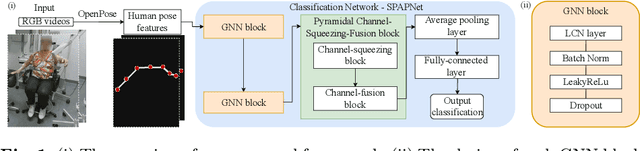
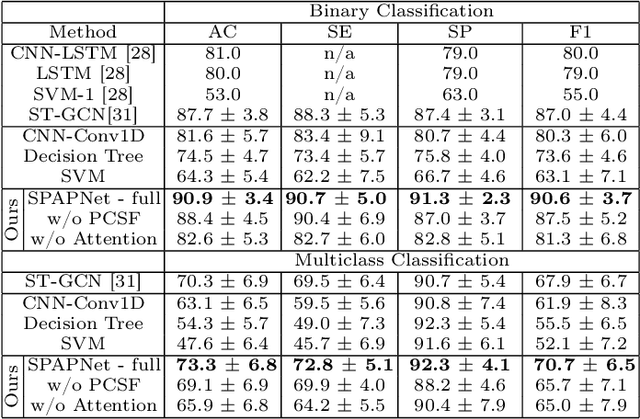
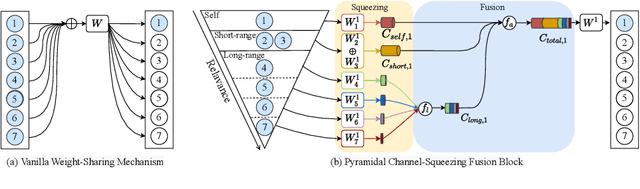
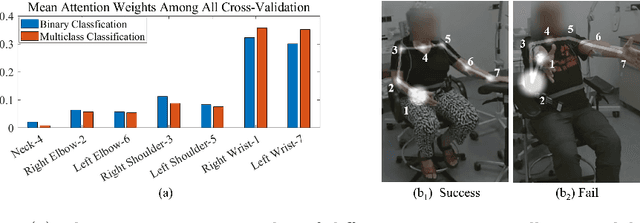
Parkinson's disease (PD) is a progressive neurodegenerative disorder that results in a variety of motor dysfunction symptoms, including tremors, bradykinesia, rigidity and postural instability. The diagnosis of PD mainly relies on clinical experience rather than a definite medical test, and the diagnostic accuracy is only about 73-84% since it is challenged by the subjective opinions or experiences of different medical experts. Therefore, an efficient and interpretable automatic PD diagnosis system is valuable for supporting clinicians with more robust diagnostic decision-making. To this end, we propose to classify Parkinson's tremor since it is one of the most predominant symptoms of PD with strong generalizability. Different from other computer-aided time and resource-consuming Parkinson's Tremor (PT) classification systems that rely on wearable sensors, we propose SPAPNet, which only requires consumer-grade non-intrusive video recording of camera-facing human movements as input to provide undiagnosed patients with low-cost PT classification results as a PD warning sign. For the first time, we propose to use a novel attention module with a lightweight pyramidal channel-squeezing-fusion architecture to extract relevant PT information and filter the noise efficiently. This design aids in improving both classification performance and system interpretability. Experimental results show that our system outperforms state-of-the-arts by achieving a balanced accuracy of 90.9% and an F1-score of 90.6% in classifying PT with the non-PT class.
Cerebral Palsy Prediction with Frequency Attention Informed Graph Convolutional Networks
Apr 23, 2022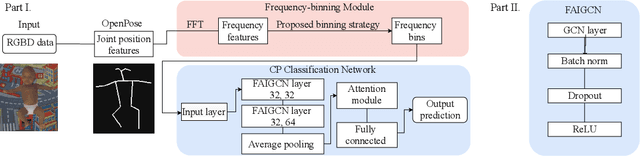
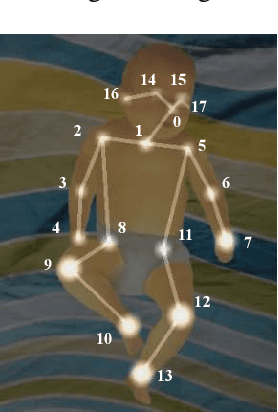
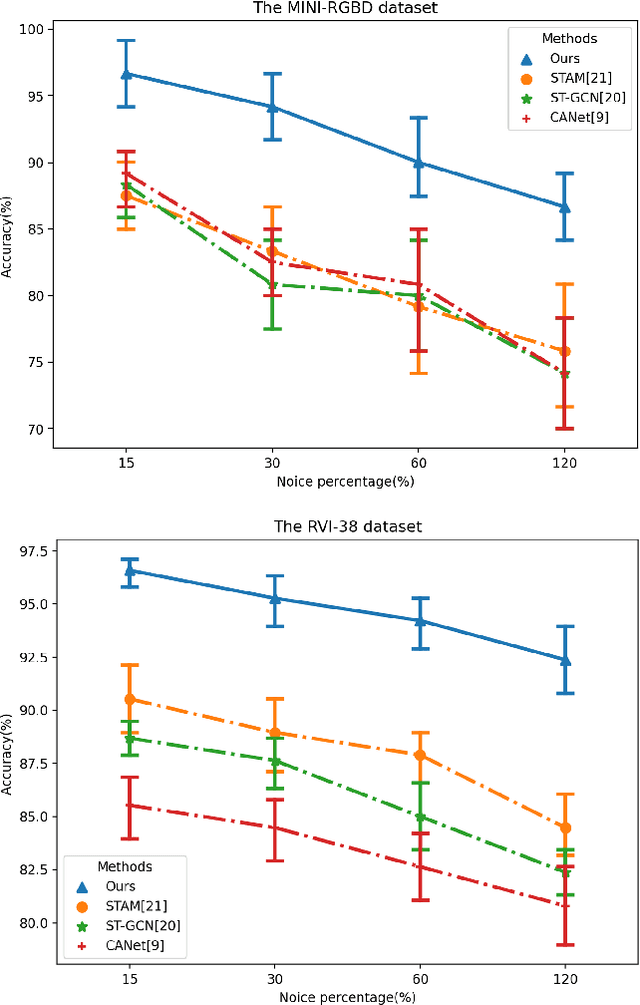
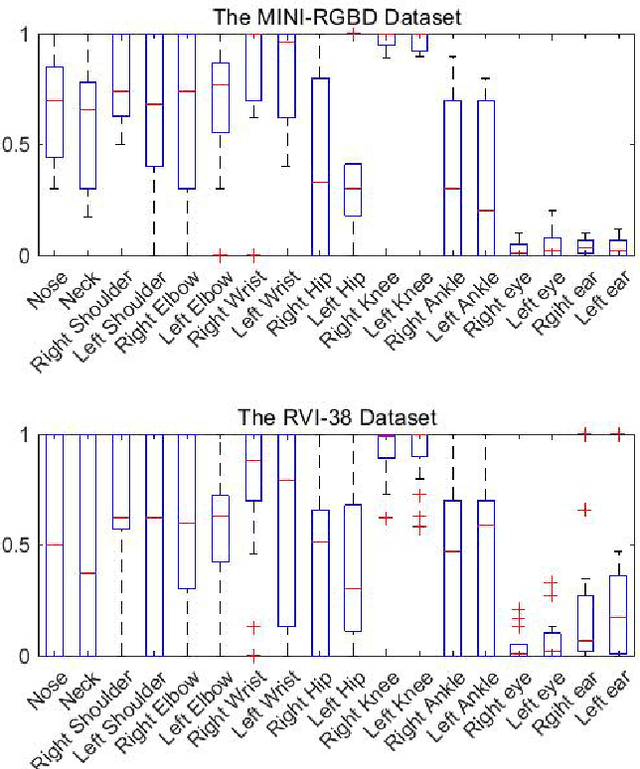
Early diagnosis and intervention are clinically considered the paramount part of treating cerebral palsy (CP), so it is essential to design an efficient and interpretable automatic prediction system for CP. We highlight a significant difference between CP infants' frequency of human movement and that of the healthy group, which improves prediction performance. However, the existing deep learning-based methods did not use the frequency information of infants' movement for CP prediction. This paper proposes a frequency attention informed graph convolutional network and validates it on two consumer-grade RGB video datasets, namely MINI-RGBD and RVI-38 datasets. Our proposed frequency attention module aids in improving both classification performance and system interpretability. In addition, we design a frequency-binning method that retains the critical frequency of the human joint position data while filtering the noise. Our prediction performance achieves state-of-the-art research on both datasets. Our work demonstrates the effectiveness of frequency information in supporting the prediction of CP non-intrusively and provides a way for supporting the early diagnosis of CP in the resource-limited regions where the clinical resources are not abundant.