 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanguMotion: Continuous Driving Motion Forecasting with Pangu Transformers
Mar 17, 2026Motion forecasting is a core task in autonomous driving systems, aiming to accurately predict the future trajectories of surrounding agents to ensure driving safety. Existing methods typically process discrete driving scenes independently, neglecting the temporal continuity and historical context correlations inherent in real-world driving environments. This paper proposes PanguMotion, a motion forecasting framework for continuous driving scenarios that integrates Transformer blocks from the Pangu-1B large language model as feature enhancement modules into autonomous driving motion prediction architectures. We conduct experiments on the Argoverse 2 datasets processed by the RealMotion data reorganization strategy, transforming each independent scene into a continuous sequence to mimic real-world driving scenarios.
UniMotion: A Unified Motion Framework for Simulation, Prediction and Planning
Jan 31, 2026Motion simulation, prediction and planning are foundational tasks in autonomous driving, each essential for modeling and reasoning about dynamic traffic scenarios. While often addressed in isolation due to their differing objectives, such as generating diverse motion states or estimating optimal trajectories, these tasks inherently depend on shared capabilities: understanding multi-agent interactions, modeling motion behaviors, and reasoning over temporal and spatial dynamics. Despite this underlying commonality, existing approaches typically adopt specialized model designs, which hinders cross-task generalization and system scalability. More critically, this separation overlooks the potential mutual benefits among tasks. Motivated by these observations, we propose UniMotion, a unified motion framework that captures shared structures across motion tasks while accommodating their individual requirements. Built on a decoder-only Transformer architecture, UniMotion employs dedicated interaction modes and tailored training strategies to simultaneously support these motion tasks. This unified design not only enables joint optimization and representation sharing but also allows for targeted fine-tuning to specialize in individual tasks when needed. Extensive experiments on the Waymo Open Motion Dataset demonstrate that joint training leads to robust generalization and effective task integration. With further fine-tuning, UniMotion achieves state-of-the-art performance across a range of motion tasks, establishing it as a versatile and scalable solution for autonomous driving.
LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving
Aug 17, 2025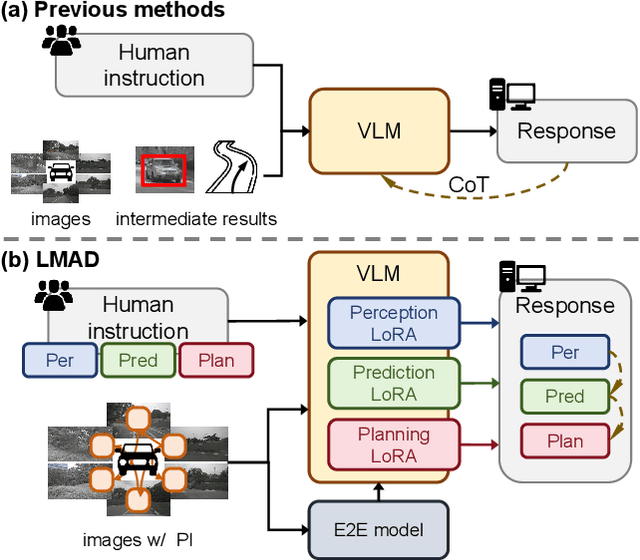
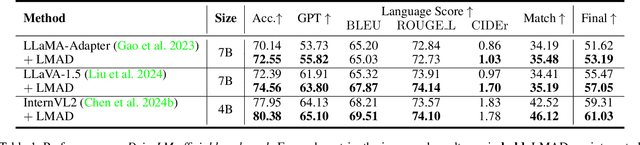
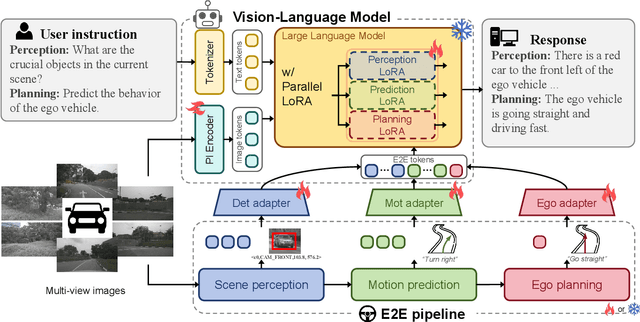
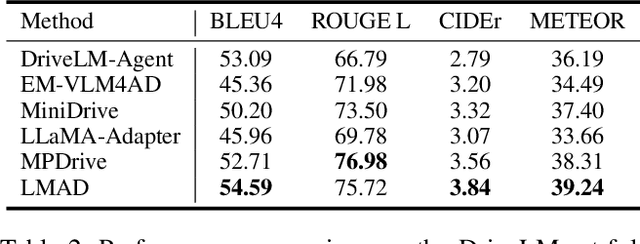
Large vision-language models (VLMs) have shown promising capabilities in scene understanding, enhancing the explainability of driving behaviors and interactivity with users. Existing methods primarily fine-tune VLMs on on-board multi-view images and scene reasoning text, but this approach often lacks the holistic and nuanced scene recognition and powerful spatial awareness required for autonomous driving, especially in complex situations. To address this gap, we propose a novel vision-language framework tailored for autonomous driving, called LMAD. Our framework emulates modern end-to-end driving paradigms by incorporating comprehensive scene understanding and a task-specialized structure with VLMs. In particular, we introduce preliminary scene interaction and specialized expert adapters within the same driving task structure, which better align VLMs with autonomous driving scenarios. Furthermore, our approach is designed to be fully compatible with existing VLMs while seamlessly integrating with planning-oriented driving systems. Extensive experiments on the DriveLM and nuScenes-QA datasets demonstrate that LMAD significantly boosts the performance of existing VLMs on driving reasoning tasks,setting a new standard in explainable autonomous driving.
DeMo++: Motion Decoupling for Autonomous Driving
Jul 23, 2025Motion forecasting and planning are tasked with estimating the trajectories of traffic agents and the ego vehicle, respectively, to ensure the safety and efficiency of autonomous driving systems in dynamically changing environments. State-of-the-art methods typically adopt a one-query-one-trajectory paradigm, where each query corresponds to a unique trajectory for predicting multi-mode trajectories. While this paradigm can produce diverse motion intentions, it often falls short in modeling the intricate spatiotemporal evolution of trajectories, which can lead to collisions or suboptimal outcomes. To overcome this limitation, we propose DeMo++, a framework that decouples motion estimation into two distinct components: holistic motion intentions to capture the diverse potential directions of movement, and fine spatiotemporal states to track the agent's dynamic progress within the scene and enable a self-refinement capability. Further, we introduce a cross-scene trajectory interaction mechanism to explore the relationships between motions in adjacent scenes. This allows DeMo++ to comprehensively model both the diversity of motion intentions and the spatiotemporal evolution of each trajectory. To effectively implement this framework, we developed a hybrid model combining Attention and Mamba. This architecture leverages the strengths of both mechanisms for efficient scene information aggregation and precise trajectory state sequence modeling. Extensive experiments demonstrate that DeMo++ achieves state-of-the-art performance across various benchmarks, including motion forecasting (Argoverse 2 and nuScenes), motion planning (nuPlan), and end-to-end planning (NAVSIM).
RealEngine: Simulating Autonomous Driving in Realistic Context
May 22, 2025Driving simulation plays a crucial role in developing reliable driving agents by providing controlled, evaluative environments. To enable meaningful assessments, a high-quality driving simulator must satisfy several key requirements: multi-modal sensing capabilities (e.g., camera and LiDAR) with realistic scene rendering to minimize observational discrepancies; closed-loop evaluation to support free-form trajectory behaviors; highly diverse traffic scenarios for thorough evaluation; multi-agent cooperation to capture interaction dynamics; and high computational efficiency to ensure affordability and scalability. However, existing simulators and benchmarks fail to comprehensively meet these fundamental criteria. To bridge this gap, this paper introduces RealEngine, a novel driving simulation framework that holistically integrates 3D scene reconstruction and novel view synthesis techniques to achieve realistic and flexible closed-loop simulation in the driving context. By leveraging real-world multi-modal sensor data, RealEngine reconstructs background scenes and foreground traffic participants separately, allowing for highly diverse and realistic traffic scenarios through flexible scene composition. This synergistic fusion of scene reconstruction and view synthesis enables photorealistic rendering across multiple sensor modalities, ensuring both perceptual fidelity and geometric accuracy. Building upon this environment, RealEngine supports three essential driving simulation categories: non-reactive simulation, safety testing, and multi-agent interaction, collectively forming a reliable and comprehensive benchmark for evaluating the real-world performance of driving agents.
Bridging Past and Future: End-to-End Autonomous Driving with Historical Prediction and Planning
Mar 18, 2025

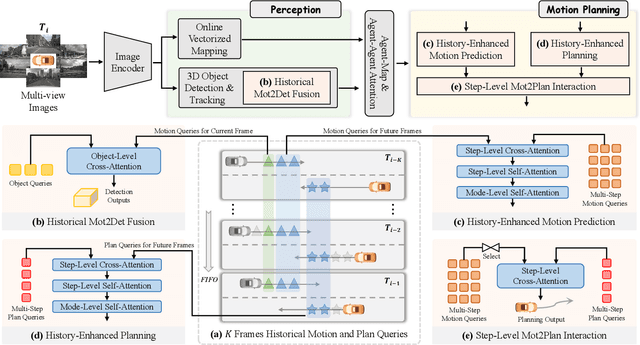

End-to-end autonomous driving unifies tasks in a differentiable framework, enabling planning-oriented optimization and attracting growing attention. Current methods aggregate historical information either through dense historical bird's-eye-view (BEV) features or by querying a sparse memory bank, following paradigms inherited from detection. However, we argue that these paradigms either omit historical information in motion planning or fail to align with its multi-step nature, which requires predicting or planning multiple future time steps. In line with the philosophy of future is a continuation of past, we propose BridgeAD, which reformulates motion and planning queries as multi-step queries to differentiate the queries for each future time step. This design enables the effective use of historical prediction and planning by applying them to the appropriate parts of the end-to-end system based on the time steps, which improves both perception and motion planning. Specifically, historical queries for the current frame are combined with perception, while queries for future frames are integrated with motion planning. In this way, we bridge the gap between past and future by aggregating historical insights at every time step, enhancing the overall coherence and accuracy of the end-to-end autonomous driving pipeline. Extensive experiments on the nuScenes dataset in both open-loop and closed-loop settings demonstrate that BridgeAD achieves state-of-the-art performance.
Towards Lifelong Few-Shot Customization of Text-to-Image Diffusion
Nov 08, 2024



Lifelong few-shot customization for text-to-image diffusion aims to continually generalize existing models for new tasks with minimal data while preserving old knowledge. Current customization diffusion models excel in few-shot tasks but struggle with catastrophic forgetting problems in lifelong generations. In this study, we identify and categorize the catastrophic forgetting problems into two folds: relevant concepts forgetting and previous concepts forgetting. To address these challenges, we first devise a data-free knowledge distillation strategy to tackle relevant concepts forgetting. Unlike existing methods that rely on additional real data or offline replay of original concept data, our approach enables on-the-fly knowledge distillation to retain the previous concepts while learning new ones, without accessing any previous data. Second, we develop an In-Context Generation (ICGen) paradigm that allows the diffusion model to be conditioned upon the input vision context, which facilitates the few-shot generation and mitigates the issue of previous concepts forgetting. Extensive experiments show that the proposed Lifelong Few-Shot Diffusion (LFS-Diffusion) method can produce high-quality and accurate images while maintaining previously learned knowledge.
DeMo: Decoupling Motion Forecasting into Directional Intentions and Dynamic States
Oct 08, 2024



Accurate motion forecasting for traffic agents is crucial for ensuring the safety and efficiency of autonomous driving systems in dynamically changing environments. Mainstream methods adopt a one-query-one-trajectory paradigm, where each query corresponds to a unique trajectory for predicting multi-modal trajectories. While straightforward and effective, the absence of detailed representation of future trajectories may yield suboptimal outcomes, given that the agent states dynamically evolve over time. To address this problem, we introduce DeMo, a framework that decouples multi-modal trajectory queries into two types: mode queries capturing distinct directional intentions and state queries tracking the agent's dynamic states over time. By leveraging this format, we separately optimize the multi-modality and dynamic evolutionary properties of trajectories. Subsequently, the mode and state queries are integrated to obtain a comprehensive and detailed representation of the trajectories. To achieve these operations, we additionally introduce combined Attention and Mamba techniques for global information aggregation and state sequence modeling, leveraging their respective strengths. Extensive experiments on both the Argoverse 2 and nuScenes benchmarks demonstrate that our DeMo achieves state-of-the-art performance in motion forecasting.
Motion Forecasting in Continuous Driving
Oct 08, 2024



Motion forecasting for agents in autonomous driving is highly challenging due to the numerous possibilities for each agent's next action and their complex interactions in space and time. In real applications, motion forecasting takes place repeatedly and continuously as the self-driving car moves. However, existing forecasting methods typically process each driving scene within a certain range independently, totally ignoring the situational and contextual relationships between successive driving scenes. This significantly simplifies the forecasting task, making the solutions suboptimal and inefficient to use in practice. To address this fundamental limitation, we propose a novel motion forecasting framework for continuous driving, named RealMotion. It comprises two integral streams both at the scene level: (1) The scene context stream progressively accumulates historical scene information until the present moment, capturing temporal interactive relationships among scene elements. (2) The agent trajectory stream optimizes current forecasting by sequentially relaying past predictions. Besides, a data reorganization strategy is introduced to narrow the gap between existing benchmarks and real-world applications, consistent with our network. These approaches enable exploiting more broadly the situational and progressive insights of dynamic motion across space and time. Extensive experiments on Argoverse series with different settings demonstrate that our RealMotion achieves state-of-the-art performance, along with the advantage of efficient real-world inference. The source code will be available at https://github.com/fudan-zvg/RealMotion.
DeepInteraction++: Multi-Modality Interaction for Autonomous Driving
Aug 09, 2024



Existing top-performance autonomous driving systems typically rely on the multi-modal fusion strategy for reliable scene understanding. This design is however fundamentally restricted due to overlooking the modality-specific strengths and finally hampering the model performance. To address this limitation, in this work, we introduce a novel modality interaction strategy that allows individual per-modality representations to be learned and maintained throughout, enabling their unique characteristics to be exploited during the whole perception pipeline. To demonstrate the effectiveness of the proposed strategy, we design DeepInteraction++, a multi-modal interaction framework characterized by a multi-modal representational interaction encoder and a multi-modal predictive interaction decoder. Specifically, the encoder is implemented as a dual-stream Transformer with specialized attention operation for information exchange and integration between separate modality-specific representations. Our multi-modal representational learning incorporates both object-centric, precise sampling-based feature alignment and global dense information spreading, essential for the more challenging planning task. The decoder is designed to iteratively refine the predictions by alternately aggregating information from separate representations in a unified modality-agnostic manner, realizing multi-modal predictive interaction. Extensive experiments demonstrate the superior performance of the proposed framework on both 3D object detection and end-to-end autonomous driving tasks. Our code is available at https://github.com/fudan-zvg/DeepInteraction.