 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual-RAG: Benchmarking Text-to-Image Retrieval Augmented Generation for Visual Knowledge Intensive Queries
Feb 23, 2025



Retrieval-Augmented Generation (RAG) is a popular approach for enhancing Large Language Models (LLMs) by addressing their limitations in verifying facts and answering knowledge-intensive questions. As the research in LLM extends their capability to handle input modality other than text, e.g. image, several multimodal RAG benchmarks are proposed. Nonetheless, they mainly use textual knowledge bases as the primary source of evidences for augmentation. There still lack benchmarks designed to evaluate images as augmentation in RAG systems and how they leverage visual knowledge. We propose Visual-RAG, a novel Question Answering benchmark that emphasizes visual knowledge intensive questions. Unlike prior works relying on text-based evidence, Visual-RAG necessitates text-to-image retrieval and integration of relevant clue images to extract visual knowledge as evidence. With Visual-RAG, we evaluate 5 open-sourced and 3 proprietary Multimodal LLMs (MLLMs), revealing that images can serve as good evidence in RAG; however, even the SoTA models struggle with effectively extracting and utilizing visual knowledge
Towards Explainable Multimodal Depression Recognition for Clinical Interviews
Jan 27, 2025



Recently, multimodal depression recognition for clinical interviews (MDRC) has recently attracted considerable attention. Existing MDRC studies mainly focus on improving task performance and have achieved significant development. However, for clinical applications, model transparency is critical, and previous works ignore the interpretability of decision-making processes. To address this issue, we propose an Explainable Multimodal Depression Recognition for Clinical Interviews (EMDRC) task, which aims to provide evidence for depression recognition by summarizing symptoms and uncovering underlying causes. Given an interviewer-participant interaction scenario, the goal of EMDRC is to structured summarize participant's symptoms based on the eight-item Patient Health Questionnaire depression scale (PHQ-8), and predict their depression severity. To tackle the EMDRC task, we construct a new dataset based on an existing MDRC dataset. Moreover, we utilize the PHQ-8 and propose a PHQ-aware multimodal multi-task learning framework, which captures the utterance-level symptom-related semantic information to help generate dialogue-level summary. Experiment results on our annotated dataset demonstrate the superiority of our proposed methods over baseline systems on the EMDRC task.
Large Language Model-Enhanced Symbolic Reasoning for Knowledge Base Completion
Jan 02, 2025



Integrating large language models (LLMs) with rule-based reasoning offers a powerful solution for improving the flexibility and reliability of Knowledge Base Completion (KBC). Traditional rule-based KBC methods offer verifiable reasoning yet lack flexibility, while LLMs provide strong semantic understanding yet suffer from hallucinations. With the aim of combining LLMs' understanding capability with the logical and rigor of rule-based approaches, we propose a novel framework consisting of a Subgraph Extractor, an LLM Proposer, and a Rule Reasoner. The Subgraph Extractor first samples subgraphs from the KB. Then, the LLM uses these subgraphs to propose diverse and meaningful rules that are helpful for inferring missing facts. To effectively avoid hallucination in LLMs' generations, these proposed rules are further refined by a Rule Reasoner to pinpoint the most significant rules in the KB for Knowledge Base Completion. Our approach offers several key benefits: the utilization of LLMs to enhance the richness and diversity of the proposed rules and the integration with rule-based reasoning to improve reliability. Our method also demonstrates strong performance across diverse KB datasets, highlighting the robustness and generalizability of the proposed framework.
Paint Outside the Box: Synthesizing and Selecting Training Data for Visual Grounding
Dec 01, 2024Visual grounding aims to localize the image regions based on a textual query. Given the difficulty of large-scale data curation, we investigate how to effectively learn visual grounding under data-scarce settings in this paper. To address data scarcity, we propose a novel framework, POBF (Paint Outside the Box, then Filter). POBF synthesizes images by inpainting outside the box, tackling a label misalignment issue encountered in previous works. Furthermore, POBF leverages an innovative filtering scheme to identify the most effective training data. This scheme combines a hardness score and an overfitting score, balanced by a penalty term. Experimental results show that POBF achieves superior performance across four datasets, delivering an average improvement of 5.83% and outperforming leading baselines by 2.29% to 3.85% in accuracy. Additionally, we validate the robustness and generalizability of POBF across various generative models, data ratios, and model architectures.
Multilingual Synopses of Movie Narratives: A Dataset for Story Understanding
Jun 18, 2024



Story video-text alignment, a core task in computational story understanding, aims to align video clips with corresponding sentences in their descriptions. However, progress on the task has been held back by the scarcity of manually annotated video-text correspondence and the heavy concentration on English narrations of Hollywood movies. To address these issues, in this paper, we construct a large-scale multilingual video story dataset named Multilingual Synopses of Movie Narratives (M-SYMON), containing 13,166 movie summary videos from 7 languages, as well as manual annotation of fine-grained video-text correspondences for 101.5 hours of video. Training on the human annotated data from SyMoN outperforms the SOTA methods by 15.7 and 16.2 percentage points on Clip Accuracy and Sentence IoU scores, respectively, demonstrating the effectiveness of the annotations. As benchmarks for future research, we create 6 baseline approaches with different multilingual training strategies, compare their performance in both intra-lingual and cross-lingual setups, exemplifying the challenges of multilingual video-text alignment.
Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation
Jun 11, 2024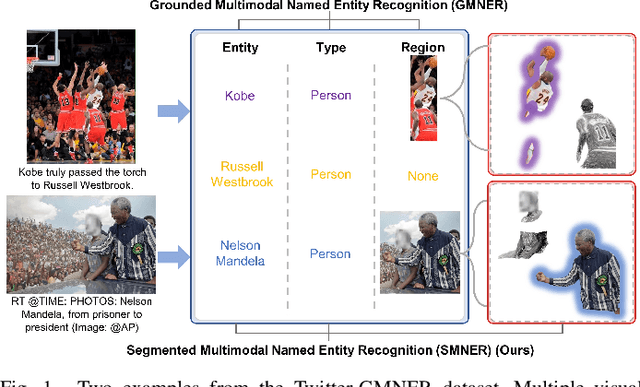
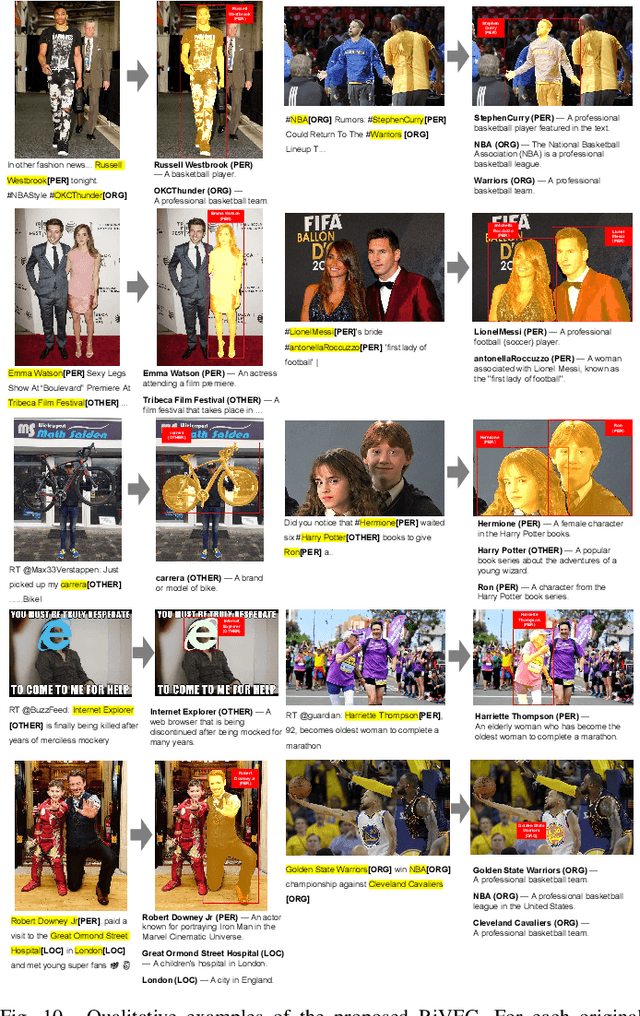
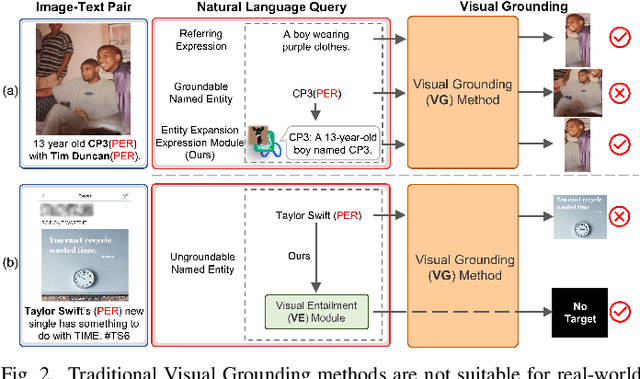
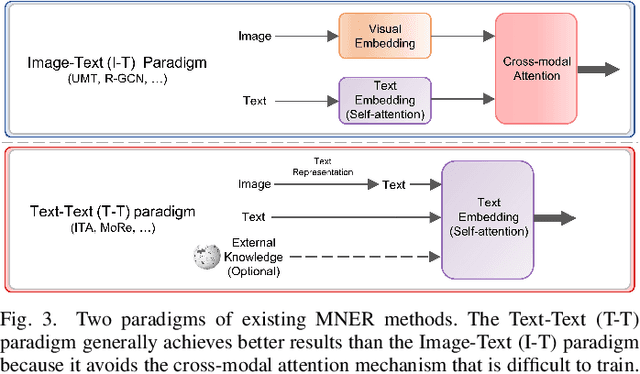
Grounded Multimodal Named Entity Recognition (GMNER) task aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging attributes: 1) The tenuous correlation between images and text on social media contributes to a notable proportion of named entities being ungroundable. 2) There exists a distinction between coarse-grained noun phrases used in similar tasks (e.g., phrase localization) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as connecting bridges. This reformulation brings two benefits: 1) It enables us to optimize the MNER module for optimal MNER performance and eliminates the need to pre-extract region features using object detection methods, thus naturally addressing the two major limitations of existing GMNER methods. 2) The introduction of Entity Expansion Expression module and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). This endows the proposed framework with unlimited data and model scalability. Furthermore, to address the potential ambiguity stemming from the coarse-grained bounding box output in GMNER, we further construct the new Segmented Multimodal Named Entity Recognition (SMNER) task and corresponding Twitter-SMNER dataset aimed at generating fine-grained segmentation masks, and experimentally demonstrate the feasibility and effectiveness of using box prompt-based Segment Anything Model (SAM) to empower any GMNER model with the ability to accomplish the SMNER task. Extensive experiments demonstrate that RiVEG significantly outperforms SoTA methods on four datasets across the MNER, GMNER, and SMNER tasks.
SemEval-2024 Task 3: Multimodal Emotion Cause Analysis in Conversations
May 19, 2024The ability to understand emotions is an essential component of human-like artificial intelligence, as emotions greatly influence human cognition, decision making, and social interactions. In addition to emotion recognition in conversations, the task of identifying the potential causes behind an individual's emotional state in conversations, is of great importance in many application scenarios. We organize SemEval-2024 Task 3, named Multimodal Emotion Cause Analysis in Conversations, which aims at extracting all pairs of emotions and their corresponding causes from conversations. Under different modality settings, it consists of two subtasks: Textual Emotion-Cause Pair Extraction in Conversations (TECPE) and Multimodal Emotion-Cause Pair Extraction in Conversations (MECPE). The shared task has attracted 143 registrations and 216 successful submissions. In this paper, we introduce the task, dataset and evaluation settings, summarize the systems of the top teams, and discuss the findings of the participants.
* 12 pages, 3 figures, 4 Tables
In-Context Learning for Knowledge Base Question Answering for Unmanned Systems based on Large Language Models
Nov 06, 2023Knowledge Base Question Answering (KBQA) aims to answer factoid questions based on knowledge bases. However, generating the most appropriate knowledge base query code based on Natural Language Questions (NLQ) poses a significant challenge in KBQA. In this work, we focus on the CCKS2023 Competition of Question Answering with Knowledge Graph Inference for Unmanned Systems. Inspired by the recent success of large language models (LLMs) like ChatGPT and GPT-3 in many QA tasks, we propose a ChatGPT-based Cypher Query Language (CQL) generation framework to generate the most appropriate CQL based on the given NLQ. Our generative framework contains six parts: an auxiliary model predicting the syntax-related information of CQL based on the given NLQ, a proper noun matcher extracting proper nouns from the given NLQ, a demonstration example selector retrieving similar examples of the input sample, a prompt constructor designing the input template of ChatGPT, a ChatGPT-based generation model generating the CQL, and an ensemble model to obtain the final answers from diversified outputs. With our ChatGPT-based CQL generation framework, we achieved the second place in the CCKS 2023 Question Answering with Knowledge Graph Inference for Unmanned Systems competition, achieving an F1-score of 0.92676.
MEMD-ABSA: A Multi-Element Multi-Domain Dataset for Aspect-Based Sentiment Analysis
Jun 29, 2023



Aspect-based sentiment analysis is a long-standing research interest in the field of opinion mining, and in recent years, researchers have gradually shifted their focus from simple ABSA subtasks to end-to-end multi-element ABSA tasks. However, the datasets currently used in the research are limited to individual elements of specific tasks, usually focusing on in-domain settings, ignoring implicit aspects and opinions, and with a small data scale. To address these issues, we propose a large-scale Multi-Element Multi-Domain dataset (MEMD) that covers the four elements across five domains, including nearly 20,000 review sentences and 30,000 quadruples annotated with explicit and implicit aspects and opinions for ABSA research. Meanwhile, we evaluate generative and non-generative baselines on multiple ABSA subtasks under the open domain setting, and the results show that open domain ABSA as well as mining implicit aspects and opinions remain ongoing challenges to be addressed. The datasets are publicly released at \url{https://github.com/NUSTM/MEMD-ABSA}.
UnifiedABSA: A Unified ABSA Framework Based on Multi-task Instruction Tuning
Nov 20, 2022



Aspect-Based Sentiment Analysis (ABSA) aims to provide fine-grained aspect-level sentiment information. There are many ABSA tasks, and the current dominant paradigm is to train task-specific models for each task. However, application scenarios of ABSA tasks are often diverse. This solution usually requires a large amount of labeled data from each task to perform excellently. These dedicated models are separately trained and separately predicted, ignoring the relationship between tasks. To tackle these issues, we present UnifiedABSA, a general-purpose ABSA framework based on multi-task instruction tuning, which can uniformly model various tasks and capture the inter-task dependency with multi-task learning. Extensive experiments on two benchmark datasets show that UnifiedABSA can significantly outperform dedicated models on 11 ABSA tasks and show its superiority in terms of data efficiency.