 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Star Rating: A Scalable Framework for Aspect-Based Sentiment Analysis Using LLMs and Text Classification
Feb 24, 2026Customer-provided reviews have become an important source of information for business owners and other customers alike. However, effectively analyzing millions of unstructured reviews remains challenging. While large language models (LLMs) show promise for natural language understanding, their application to large-scale review analysis has been limited by computational costs and scalability concerns. This study proposes a hybrid approach that uses LLMs for aspect identification while employing classic machine-learning methods for sentiment classification at scale. Using ChatGPT to analyze sampled restaurant reviews, we identified key aspects of dining experiences and developed sentiment classifiers using human-labeled reviews, which we subsequently applied to 4.7 million reviews collected over 17 years from a major online platform. Regression analysis reveals that our machine-labeled aspects significantly explain variance in overall restaurant ratings across different aspects of dining experiences, cuisines, and geographical regions. Our findings demonstrate that combining LLMs with traditional machine learning approaches can effectively automate aspect-based sentiment analysis of large-scale customer feedback, suggesting a practical framework for both researchers and practitioners in the hospitality industry and potentially, other service sectors.
TermGPT: Multi-Level Contrastive Fine-Tuning for Terminology Adaptation in Legal and Financial Domain
Nov 13, 2025Large language models (LLMs) have demonstrated impressive performance in text generation tasks; however, their embedding spaces often suffer from the isotropy problem, resulting in poor discrimination of domain-specific terminology, particularly in legal and financial contexts. This weakness in terminology-level representation can severely hinder downstream tasks such as legal judgment prediction or financial risk analysis, where subtle semantic distinctions are critical. To address this problem, we propose TermGPT, a multi-level contrastive fine-tuning framework designed for terminology adaptation. We first construct a sentence graph to capture semantic and structural relations, and generate semantically consistent yet discriminative positive and negative samples based on contextual and topological cues. We then devise a multi-level contrastive learning approach at both the sentence and token levels, enhancing global contextual understanding and fine-grained terminology discrimination. To support robust evaluation, we construct the first financial terminology dataset derived from official regulatory documents. Experiments show that TermGPT outperforms existing baselines in term discrimination tasks within the finance and legal domains.
SynBench: A Benchmark for Differentially Private Text Generation
Sep 18, 2025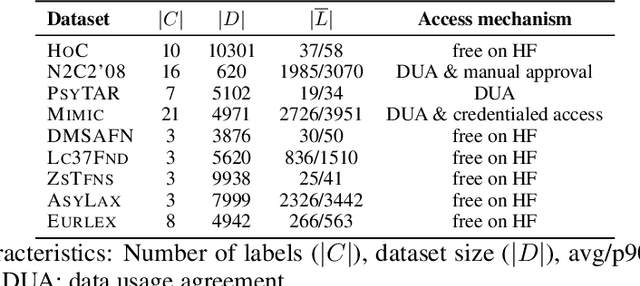
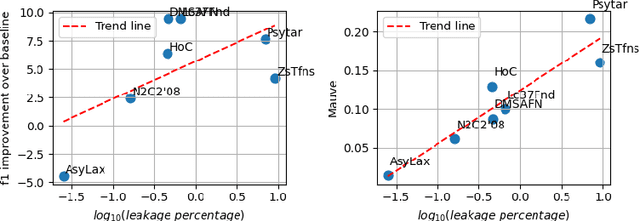
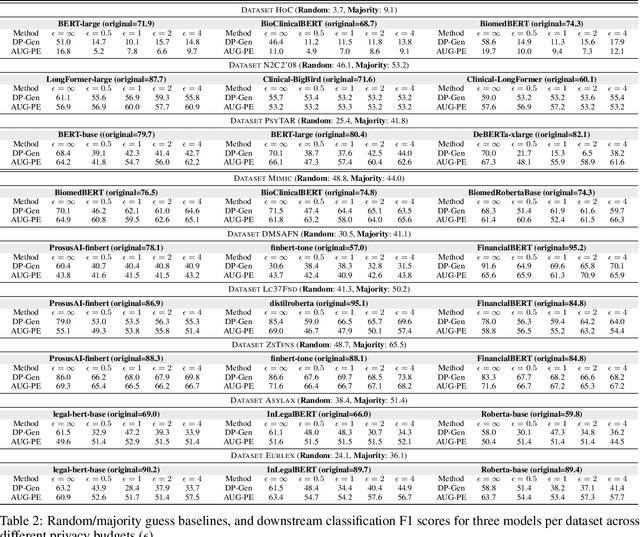
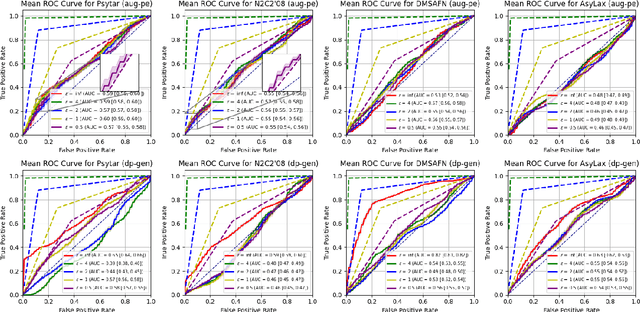
Data-driven decision support in high-stakes domains like healthcare and finance faces significant barriers to data sharing due to regulatory, institutional, and privacy concerns. While recent generative AI models, such as large language models, have shown impressive performance in open-domain tasks, their adoption in sensitive environments remains limited by unpredictable behaviors and insufficient privacy-preserving datasets for benchmarking. Existing anonymization methods are often inadequate, especially for unstructured text, as redaction and masking can still allow re-identification. Differential Privacy (DP) offers a principled alternative, enabling the generation of synthetic data with formal privacy assurances. In this work, we address these challenges through three key contributions. First, we introduce a comprehensive evaluation framework with standardized utility and fidelity metrics, encompassing nine curated datasets that capture domain-specific complexities such as technical jargon, long-context dependencies, and specialized document structures. Second, we conduct a large-scale empirical study benchmarking state-of-the-art DP text generation methods and LLMs of varying sizes and different fine-tuning strategies, revealing that high-quality domain-specific synthetic data generation under DP constraints remains an unsolved challenge, with performance degrading as domain complexity increases. Third, we develop a membership inference attack (MIA) methodology tailored for synthetic text, providing first empirical evidence that the use of public datasets - potentially present in pre-training corpora - can invalidate claimed privacy guarantees. Our findings underscore the urgent need for rigorous privacy auditing and highlight persistent gaps between open-domain and specialist evaluations, informing responsible deployment of generative AI in privacy-sensitive, high-stakes settings.
Navigating Semantic Relations: Challenges for Language Models in Abstract Common-Sense Reasoning
Feb 19, 2025


Large language models (LLMs) have achieved remarkable performance in generating human-like text and solving reasoning tasks of moderate complexity, such as question-answering and mathematical problem-solving. However, their capabilities in tasks requiring deeper cognitive skills, such as common-sense understanding and abstract reasoning, remain under-explored. In this paper, we systematically evaluate abstract common-sense reasoning in LLMs using the ConceptNet knowledge graph. We propose two prompting approaches: instruct prompting, where models predict plausible semantic relationships based on provided definitions, and few-shot prompting, where models identify relations using examples as guidance. Our experiments with the gpt-4o-mini model show that in instruct prompting, consistent performance is obtained when ranking multiple relations but with substantial decline when the model is restricted to predicting only one relation. In few-shot prompting, the model's accuracy improves significantly when selecting from five relations rather than the full set, although with notable bias toward certain relations. These results suggest significant gaps still, even in commercially used LLMs' abstract common-sense reasoning abilities, compared to human-level understanding. However, the findings also highlight the promise of careful prompt engineering, based on selective retrieval, for obtaining better performance.
Multilingual Synopses of Movie Narratives: A Dataset for Story Understanding
Jun 18, 2024



Story video-text alignment, a core task in computational story understanding, aims to align video clips with corresponding sentences in their descriptions. However, progress on the task has been held back by the scarcity of manually annotated video-text correspondence and the heavy concentration on English narrations of Hollywood movies. To address these issues, in this paper, we construct a large-scale multilingual video story dataset named Multilingual Synopses of Movie Narratives (M-SYMON), containing 13,166 movie summary videos from 7 languages, as well as manual annotation of fine-grained video-text correspondences for 101.5 hours of video. Training on the human annotated data from SyMoN outperforms the SOTA methods by 15.7 and 16.2 percentage points on Clip Accuracy and Sentence IoU scores, respectively, demonstrating the effectiveness of the annotations. As benchmarks for future research, we create 6 baseline approaches with different multilingual training strategies, compare their performance in both intra-lingual and cross-lingual setups, exemplifying the challenges of multilingual video-text alignment.
Event Causality Is Key to Computational Story Understanding
Nov 16, 2023Psychological research suggests the central role of event causality in human story understanding. Further, event causality has been heavily utilized in symbolic story generation. However, few machine learning systems for story understanding employ event causality, partially due to the lack of reliable methods for identifying open-world causal event relations. Leveraging recent progress in large language models (LLMs), we present the first method for event causality identification that leads to material improvements in computational story understanding. We design specific prompts for extracting event causal relations from GPT. Against human-annotated event causal relations in the GLUCOSE dataset, our technique performs on par with supervised models, while being easily generalizable to stories of different types and lengths. The extracted causal relations lead to 5.7\% improvements on story quality evaluation and 8.7\% on story video-text alignment. Our findings indicate enormous untapped potential for event causality in computational story understanding.
Training Multimedia Event Extraction With Generated Images and Captions
Jun 15, 2023



Contemporary news reporting increasingly features multimedia content, motivating research on multimedia event extraction. However, the task lacks annotated multimodal training data and artificially generated training data suffer from the distribution shift from the real-world data. In this paper, we propose Cross-modality Augmented Multimedia Event Learning (CAMEL), which successfully utilizes artificially generated multimodal training data and achieves state-of-the-art performance. Conditioned on unimodal training data, we generate multimodal training data using off-the-shelf image generators like Stable Diffusion and image captioners like BLIP. In order to learn robust features that are effective across domains, we devise an iterative and gradual annealing training strategy. Substantial experiments show that CAMEL surpasses state-of-the-art (SOTA) baselines on the M2E2 benchmark. On multimedia events in particular, we outperform the prior SOTA by 4.2\% F1 on event mention identification and by 9.8\% F1 on argument identification, which demonstrates that CAMEL learns synergistic representations from the two modalities.
Synopses of Movie Narratives: a Video-Language Dataset for Story Understanding
Mar 11, 2022

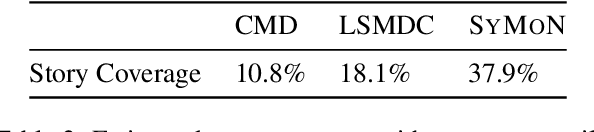
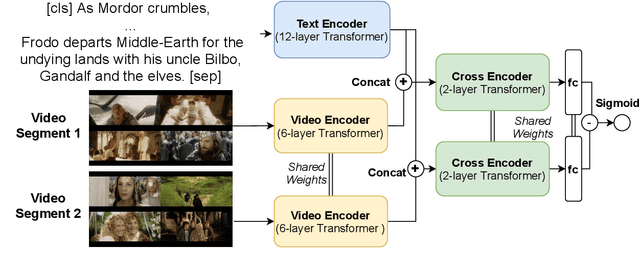
Despite recent advances of AI, story understanding remains an open and under-investigated problem. We collect, preprocess, and publicly release a video-language story dataset, Synopses of Movie Narratives(SyMoN), containing 5,193 video summaries of popular movies and TV series. SyMoN captures naturalistic storytelling videos for human audience made by human creators, and has higher story coverage and more frequent mental-state references than similar video-language story datasets. Differing from most existing video-text datasets, SyMoN features large semantic gaps between the visual and the textual modalities due to the prevalence of reporting bias and mental state descriptions. We establish benchmarks on video-text retrieval and zero-shot alignment on movie summary videos. With SyMoN, we hope to lay the groundwork for progress in multimodal story understanding.
Multi-fold Correlation Attention Network for Predicting Traffic Speeds with Heterogeneous Frequency
Apr 19, 2021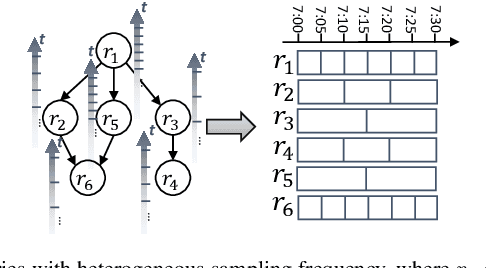
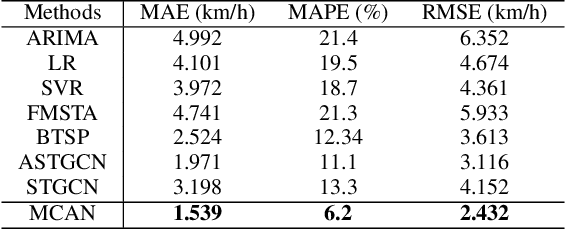
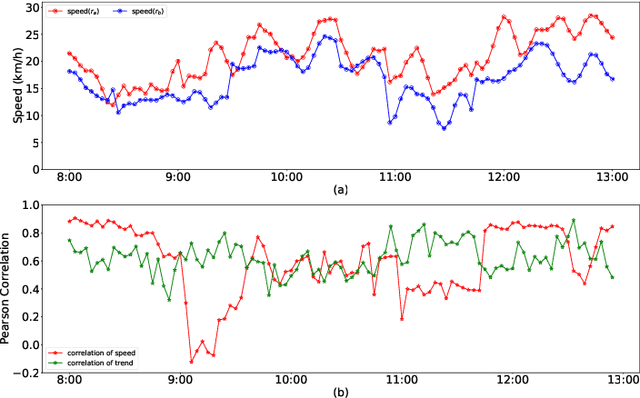
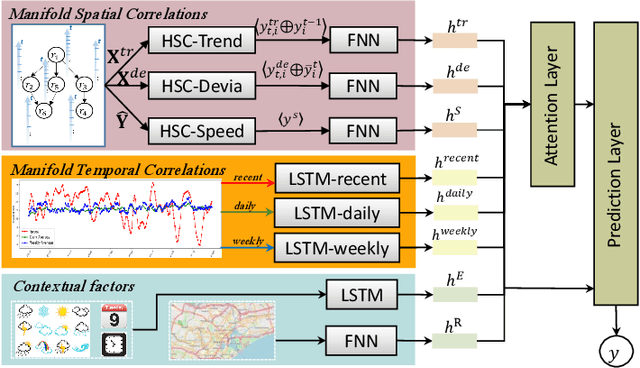
Substantial efforts have been devoted to the investigation of spatiotemporal correlations for improving traffic speed prediction accuracy. However, existing works typically model the correlations based solely on the observed traffic state (e.g. traffic speed) without due consideration that different correlation measurements of the traffic data could exhibit a diverse set of patterns under different traffic situations. In addition, the existing works assume that all road segments can employ the same sampling frequency of traffic states, which is impractical. In this paper, we propose new measurements to model the spatial correlations among traffic data and show that the resulting correlation patterns vary significantly under various traffic situations. We propose a Heterogeneous Spatial Correlation (HSC) model to capture the spatial correlation based on a specific measurement, where the traffic data of varying road segments can be heterogeneous (i.e. obtained with different sampling frequency). We propose a Multi-fold Correlation Attention Network (MCAN), which relies on the HSC model to explore multi-fold spatial correlations and leverage LSTM networks to capture multi-fold temporal correlations to provide discriminating features in order to achieve accurate traffic prediction. The learned multi-fold spatiotemporal correlations together with contextual factors are fused with attention mechanism to make the final predictions. Experiments on real-world datasets demonstrate that the proposed MCAN model outperforms the state-of-the-art baselines.