 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynBench: A Benchmark for Differentially Private Text Generation
Sep 18, 2025
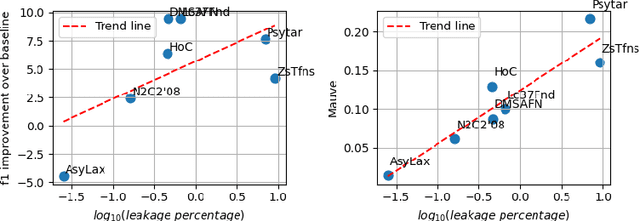
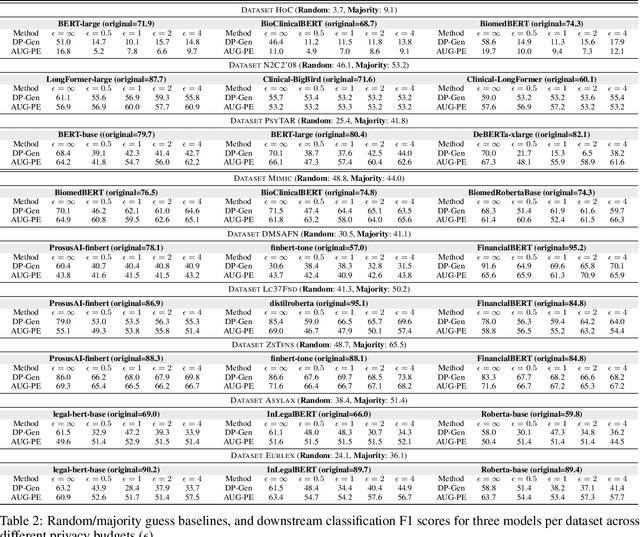
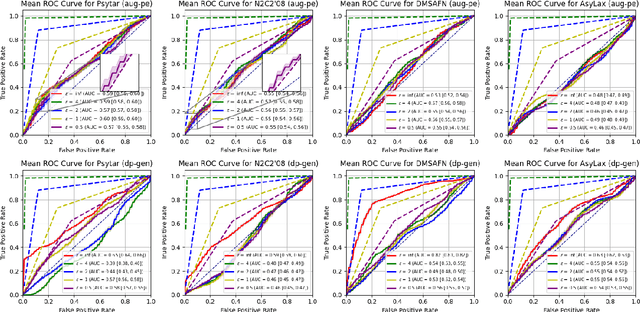
Data-driven decision support in high-stakes domains like healthcare and finance faces significant barriers to data sharing due to regulatory, institutional, and privacy concerns. While recent generative AI models, such as large language models, have shown impressive performance in open-domain tasks, their adoption in sensitive environments remains limited by unpredictable behaviors and insufficient privacy-preserving datasets for benchmarking. Existing anonymization methods are often inadequate, especially for unstructured text, as redaction and masking can still allow re-identification. Differential Privacy (DP) offers a principled alternative, enabling the generation of synthetic data with formal privacy assurances. In this work, we address these challenges through three key contributions. First, we introduce a comprehensive evaluation framework with standardized utility and fidelity metrics, encompassing nine curated datasets that capture domain-specific complexities such as technical jargon, long-context dependencies, and specialized document structures. Second, we conduct a large-scale empirical study benchmarking state-of-the-art DP text generation methods and LLMs of varying sizes and different fine-tuning strategies, revealing that high-quality domain-specific synthetic data generation under DP constraints remains an unsolved challenge, with performance degrading as domain complexity increases. Third, we develop a membership inference attack (MIA) methodology tailored for synthetic text, providing first empirical evidence that the use of public datasets - potentially present in pre-training corpora - can invalidate claimed privacy guarantees. Our findings underscore the urgent need for rigorous privacy auditing and highlight persistent gaps between open-domain and specialist evaluations, informing responsible deployment of generative AI in privacy-sensitive, high-stakes settings.
Pay Attention to Real World Perturbations! Natural Robustness Evaluation in Machine Reading Comprehension
Feb 23, 2025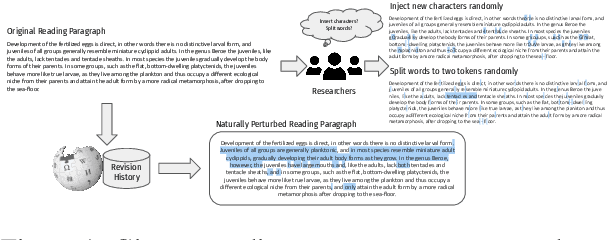
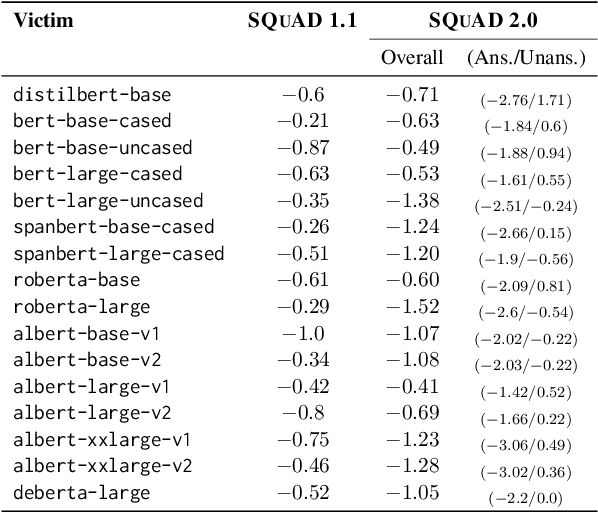
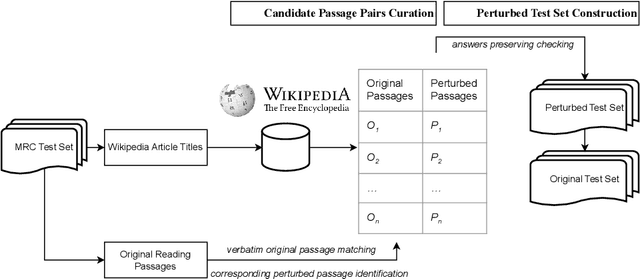
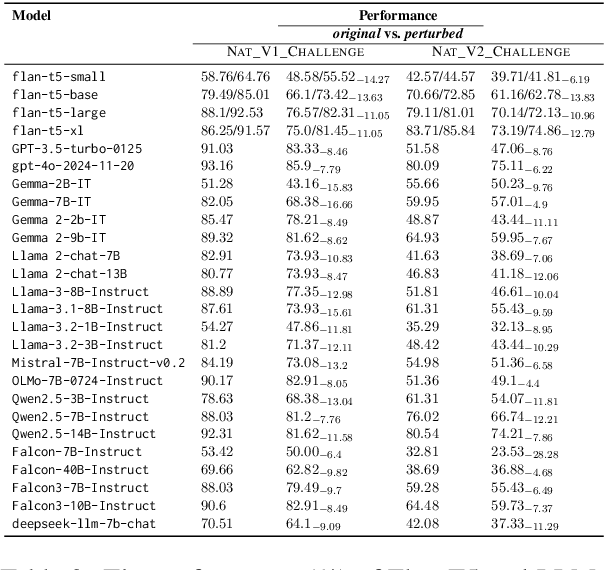
As neural language models achieve human-comparable performance on Machine Reading Comprehension (MRC) and see widespread adoption, ensuring their robustness in real-world scenarios has become increasingly important. Current robustness evaluation research, though, primarily develops synthetic perturbation methods, leaving unclear how well they reflect real life scenarios. Considering this, we present a framework to automatically examine MRC models on naturally occurring textual perturbations, by replacing paragraph in MRC benchmarks with their counterparts based on available Wikipedia edit history. Such perturbation type is natural as its design does not stem from an arteficial generative process, inherently distinct from the previously investigated synthetic approaches. In a large-scale study encompassing SQUAD datasets and various model architectures we observe that natural perturbations result in performance degradation in pre-trained encoder language models. More worryingly, these state-of-the-art Flan-T5 and Large Language Models (LLMs) inherit these errors. Further experiments demonstrate that our findings generalise to natural perturbations found in other more challenging MRC benchmarks. In an effort to mitigate these errors, we show that it is possible to improve the robustness to natural perturbations by training on naturally or synthetically perturbed examples, though a noticeable gap still remains compared to performance on unperturbed data.
SR-LLM: Rethinking the Structured Representation in Large Language Model
Feb 20, 2025



Structured representations, exemplified by Abstract Meaning Representation (AMR), have long been pivotal in computational linguistics. However, their role remains ambiguous in the Large Language Models (LLMs) era. Initial attempts to integrate structured representation into LLMs via a zero-shot setting yielded inferior performance. We hypothesize that such a decline stems from the structure information being passed into LLMs in a code format unfamiliar to LLMs' training corpora. Consequently, we propose SR-LLM, an innovative framework with two settings to explore a superior way of integrating structured representation with LLMs from training-free and training-dependent perspectives. The former integrates structural information through natural language descriptions in LLM prompts, whereas its counterpart augments the model's inference capability through fine-tuning on linguistically described structured representations. Performance improvements were observed in widely downstream datasets, with particularly notable gains of 3.17% and 12.38% in PAWS. To the best of our knowledge, this work represents the pioneering demonstration that leveraging structural representations can substantially enhance LLMs' inference capability. We hope that our work sheds light and encourages future research to enhance the reasoning and interoperability of LLMs by structure data.
A Possible Reason for why Data-Driven Beats Theory-Driven Computer Vision
Sep 06, 2019


Why do some continue to wonder about the success and dominance of deep learning methods in computer vision and AI? Is it not enough that these methods provide practical solutions to many problems? Well no, it is not enough, at least for those who feel there should be a science that underpins all of this and that we should have a clear understanding of how this success was achieved. Here, this paper proposes that the dominance we are witnessing would not have been possible by the methods of deep learning alone: the tacit change has been the evolution of empirical practice in computer vision and AI over the past decades. We demonstrate this by examining the distribution of sensor settings in vision datasets and performance of both classic and deep learning algorithms under various camera settings. This reveals a strong mismatch between optimal performance ranges of classical theory-driven algorithms and sensor setting distributions in the common vision datasets, while data-driven models were trained for those datasets. The head-to-head comparisons between data-driven and theory-driven models were therefore unknowingly biased against the theory-driven models.
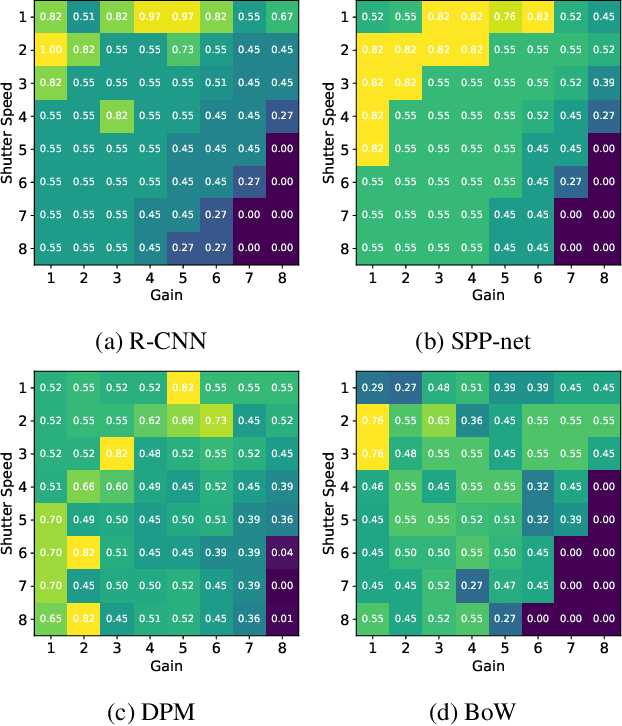
Active Control of Camera Parameters for Object Detection Algorithms
May 16, 2017



Camera parameters not only play an important role in determining the visual quality of perceived images, but also affect the performance of vision algorithms, for a vision-guided robot. By quantitatively evaluating four object detection algorithms, with respect to varying ambient illumination, shutter speed and voltage gain, it is observed that the performance of the algorithms is highly dependent on these variables. From this observation, a novel active control of camera parameters method is proposed, to make robot vision more robust under different light conditions. Experimental results demonstrate the effectiveness of our proposed approach, which improves the performance of object detection algorithms, compared with the conventional auto-exposure algorithm.