 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSR-LLM: Rethinking the Structured Representation in Large Language Model
Feb 20, 2025



Structured representations, exemplified by Abstract Meaning Representation (AMR), have long been pivotal in computational linguistics. However, their role remains ambiguous in the Large Language Models (LLMs) era. Initial attempts to integrate structured representation into LLMs via a zero-shot setting yielded inferior performance. We hypothesize that such a decline stems from the structure information being passed into LLMs in a code format unfamiliar to LLMs' training corpora. Consequently, we propose SR-LLM, an innovative framework with two settings to explore a superior way of integrating structured representation with LLMs from training-free and training-dependent perspectives. The former integrates structural information through natural language descriptions in LLM prompts, whereas its counterpart augments the model's inference capability through fine-tuning on linguistically described structured representations. Performance improvements were observed in widely downstream datasets, with particularly notable gains of 3.17% and 12.38% in PAWS. To the best of our knowledge, this work represents the pioneering demonstration that leveraging structural representations can substantially enhance LLMs' inference capability. We hope that our work sheds light and encourages future research to enhance the reasoning and interoperability of LLMs by structure data.
Learning to Cluster Faces via Transformer
Apr 23, 2021
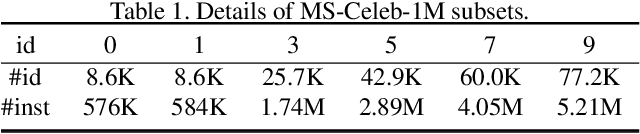
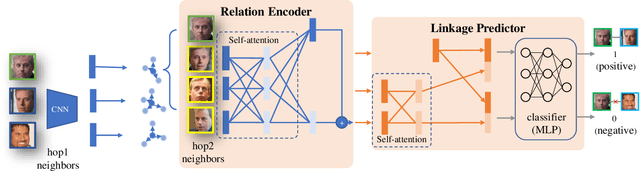
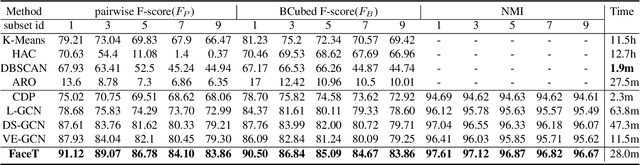
Face clustering is a useful tool for applications like automatic face annotation and retrieval. The main challenge is that it is difficult to cluster images from the same identity with different face poses, occlusions, and image quality. Traditional clustering methods usually ignore the relationship between individual images and their neighbors which may contain useful context information. In this paper, we repurpose the well-known Transformer and introduce a Face Transformer for supervised face clustering. In Face Transformer, we decompose the face clustering into two steps: relation encoding and linkage predicting. Specifically, given a face image, a \textbf{relation encoder} module aggregates local context information from its neighbors and a \textbf{linkage predictor} module judges whether a pair of images belong to the same cluster or not. In the local linkage graph view, Face Transformer can generate more robust node and edge representations compared to existing methods. Experiments on both MS-Celeb-1M and DeepFashion show that our method achieves state-of-the-art performance, e.g., 91.12\% in pairwise F-score on MS-Celeb-1M.