 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Interference Reduction by Selective Fine-Tuning of Neural Networks
Nov 21, 2020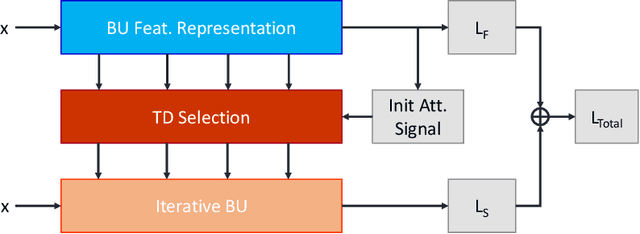
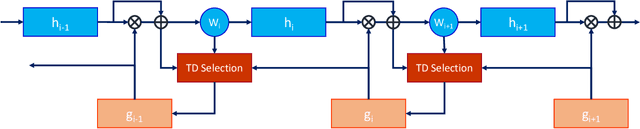

Feature disentanglement of the foreground target objects and the background surrounding context has not been yet fully accomplished. The lack of network interpretability prevents advancing for feature disentanglement and better generalization robustness. We study the role of the context on interfering with a disentangled foreground target object representation in this work. We hypothesize that the representation of the surrounding context is heavily tied with the foreground object due to the dense hierarchical parametrization of convolutional networks with under-constrained learning algorithms. Working on a framework that benefits from the bottom-up and top-down processing paradigms, we investigate a systematic approach to shift learned representations in feedforward networks from the emphasis on the irrelevant context to the foreground objects. The top-down processing provides importance maps as the means of the network internal self-interpretation that will guide the learning algorithm to focus on the relevant foreground regions towards achieving a more robust representations. We define an experimental evaluation setup with the role of context emphasized using the MNIST dataset. The experimental results reveal not only that the label prediction accuracy is improved but also a higher degree of robustness to the background perturbation using various noise generation methods is obtained.
Compact Neural Representation Using Attentive Network Pruning
May 10, 2020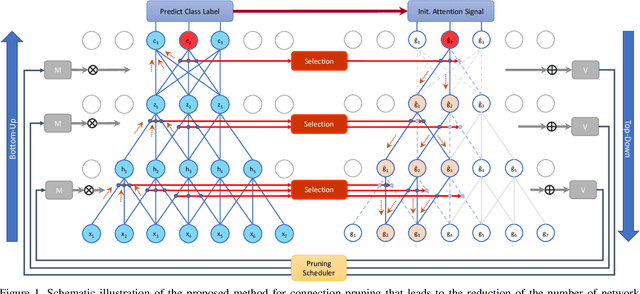



Deep neural networks have evolved to become power demanding and consequently difficult to apply to small-size mobile platforms. Network parameter reduction methods have been introduced to systematically deal with the computational and memory complexity of deep networks. We propose to examine the ability of attentive connection pruning to deal with redundancy reduction in neural networks as a contribution to the reduction of computational demand. In this work, we describe a Top-Down attention mechanism that is added to a Bottom-Up feedforward network to select important connections and subsequently prune redundant ones at all parametric layers. Our method not only introduces a novel hierarchical selection mechanism as the basis of pruning but also remains competitive with previous baseline methods in the experimental evaluation. We conduct experiments using different network architectures on popular benchmark datasets to show high compression ratio is achievable with negligible loss of accuracy.
Selective Segmentation Networks Using Top-Down Attention
Feb 04, 2020


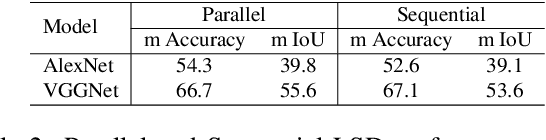
Convolutional neural networks model the transformation of the input sensory data at the bottom of a network hierarchy to the semantic information at the top of the visual hierarchy. Feedforward processing is sufficient for some object recognition tasks. Top-Down selection is potentially required in addition to the Bottom-Up feedforward pass. It can, in part, address the shortcoming of the loss of location information imposed by the hierarchical feature pyramids. We propose a unified 2-pass framework for object segmentation that augments Bottom-Up \convnets with a Top-Down selection network. We utilize the top-down selection gating activities to modulate the bottom-up hidden activities for segmentation predictions. We develop an end-to-end multi-task framework with loss terms satisfying task requirements at the two ends of the network. We evaluate the proposed network on benchmark datasets for semantic segmentation, and show that networks with the Top-Down selection capability outperform the baseline model. Additionally, we shed light on the superior aspects of the new segmentation paradigm and qualitatively and quantitatively support the efficiency of the novel framework over the baseline model that relies purely on parametric skip connections.
STNet: Selective Tuning of Convolutional Networks for Object Localization
Aug 21, 2017



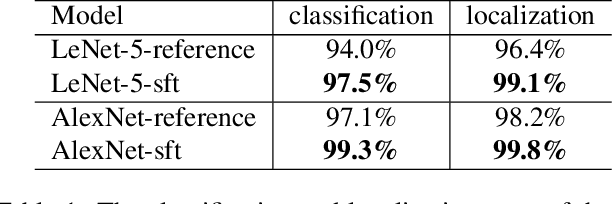
Visual attention modeling has recently gained momentum in developing visual hierarchies provided by Convolutional Neural Networks. Despite recent successes of feedforward processing on the abstraction of concepts form raw images, the inherent nature of feedback processing has remained computationally controversial. Inspired by the computational models of covert visual attention, we propose the Selective Tuning of Convolutional Networks (STNet). It is composed of both streams of Bottom-Up and Top-Down information processing to selectively tune the visual representation of Convolutional networks. We experimentally evaluate the performance of STNet for the weakly-supervised localization task on the ImageNet benchmark dataset. We demonstrate that STNet not only successfully surpasses the state-of-the-art results but also generates attention-driven class hypothesis maps.
Active Control of Camera Parameters for Object Detection Algorithms
May 16, 2017



Camera parameters not only play an important role in determining the visual quality of perceived images, but also affect the performance of vision algorithms, for a vision-guided robot. By quantitatively evaluating four object detection algorithms, with respect to varying ambient illumination, shutter speed and voltage gain, it is observed that the performance of the algorithms is highly dependent on these variables. From this observation, a novel active control of camera parameters method is proposed, to make robot vision more robust under different light conditions. Experimental results demonstrate the effectiveness of our proposed approach, which improves the performance of object detection algorithms, compared with the conventional auto-exposure algorithm.