 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Trajectory-User Linking with Dual-Stream Representation Networks
Mar 19, 2025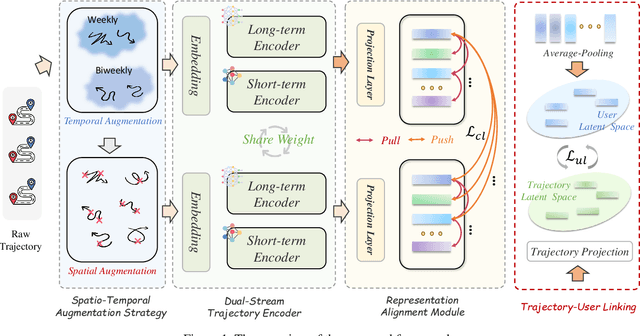
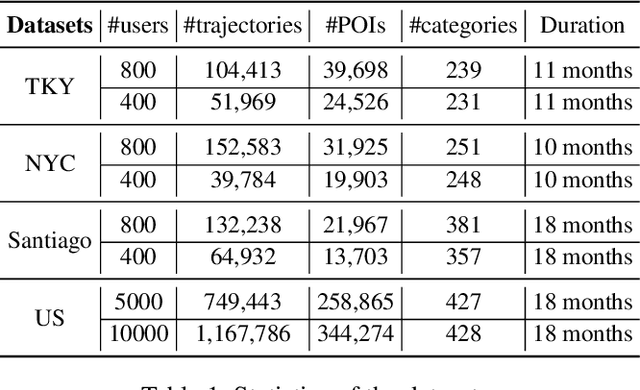
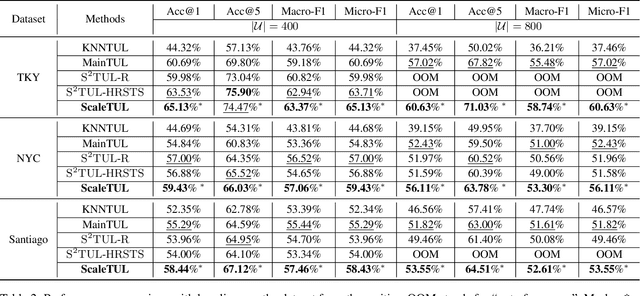
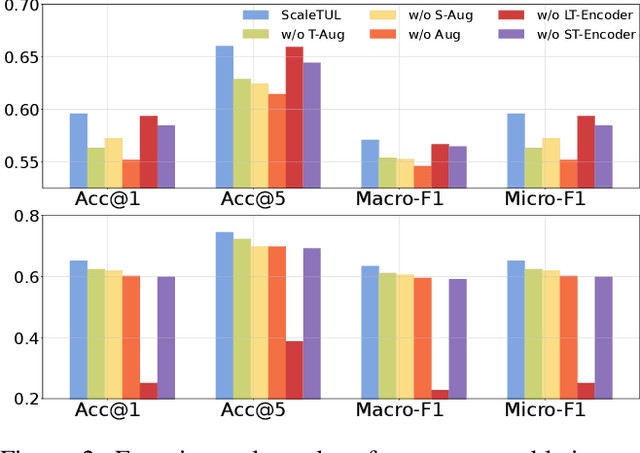
Trajectory-user linking (TUL) aims to match anonymous trajectories to the most likely users who generated them, offering benefits for a wide range of real-world spatio-temporal applications. However, existing TUL methods are limited by high model complexity and poor learning of the effective representations of trajectories, rendering them ineffective in handling large-scale user trajectory data. In this work, we propose a novel $\underline{Scal}$abl$\underline{e}$ Trajectory-User Linking with dual-stream representation networks for large-scale $\underline{TUL}$ problem, named ScaleTUL. Specifically, ScaleTUL generates two views using temporal and spatial augmentations to exploit supervised contrastive learning framework to effectively capture the irregularities of trajectories. In each view, a dual-stream trajectory encoder, consisting of a long-term encoder and a short-term encoder, is designed to learn unified trajectory representations that fuse different temporal-spatial dependencies. Then, a TUL layer is used to associate the trajectories with the corresponding users in the representation space using a two-stage training model. Experimental results on check-in mobility datasets from three real-world cities and the nationwide U.S. demonstrate the superiority of ScaleTUL over state-of-the-art baselines for large-scale TUL tasks.
Spatiotemporal-aware Trend-Seasonality Decomposition Network for Traffic Flow Forecasting
Feb 17, 2025Traffic prediction is critical for optimizing travel scheduling and enhancing public safety, yet the complex spatial and temporal dynamics within traffic data present significant challenges for accurate forecasting. In this paper, we introduce a novel model, the Spatiotemporal-aware Trend-Seasonality Decomposition Network (STDN). This model begins by constructing a dynamic graph structure to represent traffic flow and incorporates novel spatio-temporal embeddings to jointly capture global traffic dynamics. The representations learned are further refined by a specially designed trend-seasonality decomposition module, which disentangles the trend-cyclical component and seasonal component for each traffic node at different times within the graph. These components are subsequently processed through an encoder-decoder network to generate the final predictions. Extensive experiments conducted on real-world traffic datasets demonstrate that STDN achieves superior performance with remarkable computation cost. Furthermore, we have released a new traffic dataset named JiNan, which features unique inner-city dynamics, thereby enriching the scenario comprehensiveness in traffic prediction evaluation.
Multi-fold Correlation Attention Network for Predicting Traffic Speeds with Heterogeneous Frequency
Apr 19, 2021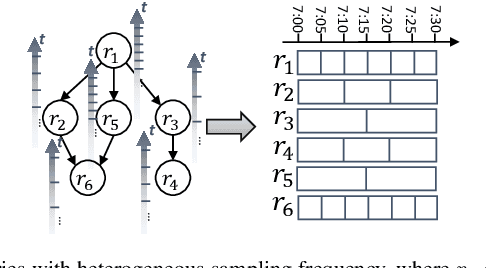
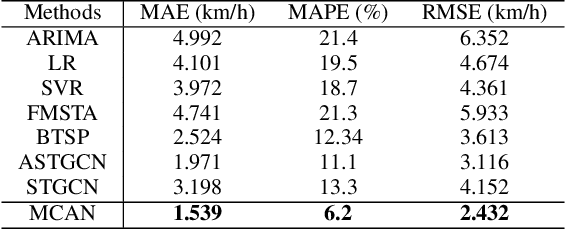
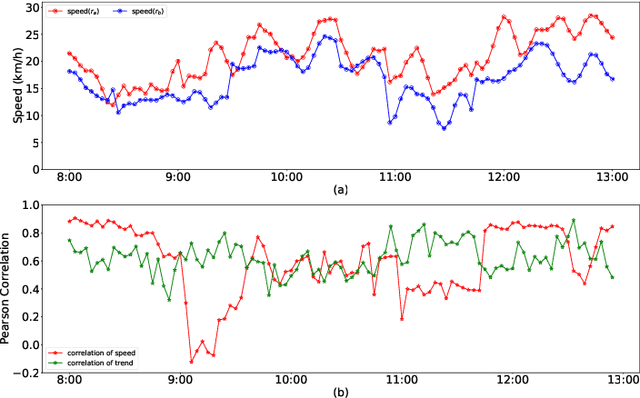
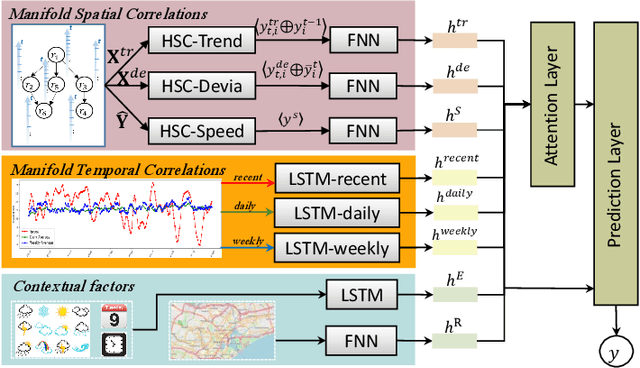
Substantial efforts have been devoted to the investigation of spatiotemporal correlations for improving traffic speed prediction accuracy. However, existing works typically model the correlations based solely on the observed traffic state (e.g. traffic speed) without due consideration that different correlation measurements of the traffic data could exhibit a diverse set of patterns under different traffic situations. In addition, the existing works assume that all road segments can employ the same sampling frequency of traffic states, which is impractical. In this paper, we propose new measurements to model the spatial correlations among traffic data and show that the resulting correlation patterns vary significantly under various traffic situations. We propose a Heterogeneous Spatial Correlation (HSC) model to capture the spatial correlation based on a specific measurement, where the traffic data of varying road segments can be heterogeneous (i.e. obtained with different sampling frequency). We propose a Multi-fold Correlation Attention Network (MCAN), which relies on the HSC model to explore multi-fold spatial correlations and leverage LSTM networks to capture multi-fold temporal correlations to provide discriminating features in order to achieve accurate traffic prediction. The learned multi-fold spatiotemporal correlations together with contextual factors are fused with attention mechanism to make the final predictions. Experiments on real-world datasets demonstrate that the proposed MCAN model outperforms the state-of-the-art baselines.