 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleGNN: Towards Scalable Graph Neural Networks via Adaptive High-order Neighboring Feature Fusion
Apr 22, 2025Graph Neural Networks (GNNs) have demonstrated strong performance across various graph-based tasks by effectively capturing relational information between nodes. These models rely on iterative message passing to propagate node features, enabling nodes to aggregate information from their neighbors. Recent research has significantly improved the message-passing mechanism, enhancing GNN scalability on large-scale graphs. However, GNNs still face two main challenges: over-smoothing, where excessive message passing results in indistinguishable node representations, especially in deep networks incorporating high-order neighbors; and scalability issues, as traditional architectures suffer from high model complexity and increased inference time due to redundant information aggregation. This paper proposes a novel framework for large-scale graphs named ScaleGNN that simultaneously addresses both challenges by adaptively fusing multi-level graph features. We first construct neighbor matrices for each order, learning their relative information through trainable weights through an adaptive high-order feature fusion module. This allows the model to selectively emphasize informative high-order neighbors while reducing unnecessary computational costs. Additionally, we introduce a High-order redundant feature masking mechanism based on a Local Contribution Score (LCS), which enables the model to retain only the most relevant neighbors at each order, preventing redundant information propagation. Furthermore, low-order enhanced feature aggregation adaptively integrates low-order and high-order features based on task relevance, ensuring effective capture of both local and global structural information without excessive complexity. Extensive experiments on real-world datasets demonstrate that our approach consistently outperforms state-of-the-art GNN models in both accuracy and computational efficiency.
Efficient Discovery of Motif Transition Process for Large-Scale Temporal Graphs
Apr 22, 2025Understanding the dynamic transition of motifs in temporal graphs is essential for revealing how graph structures evolve over time, identifying critical patterns, and predicting future behaviors, yet existing methods often focus on predefined motifs, limiting their ability to comprehensively capture transitions and interrelationships. We propose a parallel motif transition process discovery algorithm, PTMT, a novel parallel method for discovering motif transition processes in large-scale temporal graphs. PTMT integrates a tree-based framework with the temporal zone partitioning (TZP) strategy, which partitions temporal graphs by time and structure while preserving lossless motif transitions and enabling massive parallelism. PTMT comprises three phases: growth zone parallel expansion, overlap-aware result aggregation, and deterministic encoding of motif transitions, ensuring accurate tracking of dynamic transitions and interactions. Results on 10 real-world datasets demonstrate that PTMT achieves speedups ranging from 12.0$\times$ to 50.3$\times$ compared to the SOTA method.
Scalable Trajectory-User Linking with Dual-Stream Representation Networks
Mar 19, 2025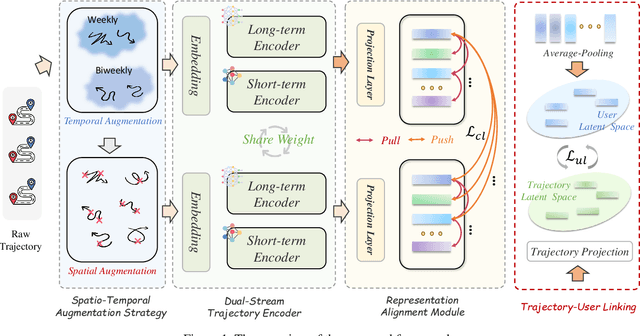
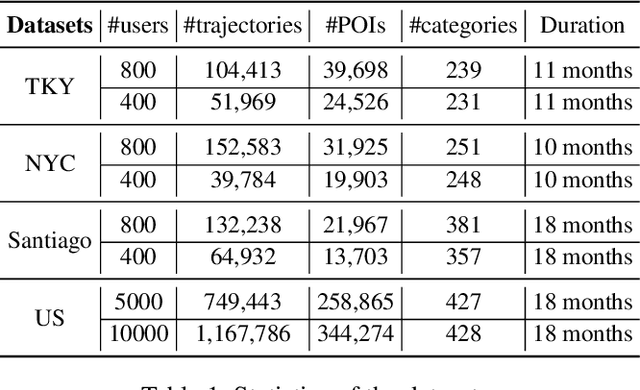
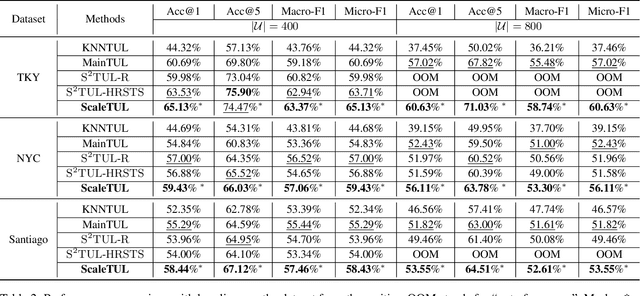
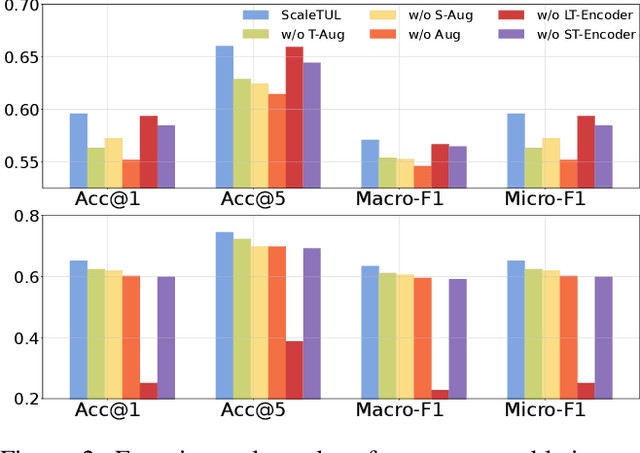
Trajectory-user linking (TUL) aims to match anonymous trajectories to the most likely users who generated them, offering benefits for a wide range of real-world spatio-temporal applications. However, existing TUL methods are limited by high model complexity and poor learning of the effective representations of trajectories, rendering them ineffective in handling large-scale user trajectory data. In this work, we propose a novel $\underline{Scal}$abl$\underline{e}$ Trajectory-User Linking with dual-stream representation networks for large-scale $\underline{TUL}$ problem, named ScaleTUL. Specifically, ScaleTUL generates two views using temporal and spatial augmentations to exploit supervised contrastive learning framework to effectively capture the irregularities of trajectories. In each view, a dual-stream trajectory encoder, consisting of a long-term encoder and a short-term encoder, is designed to learn unified trajectory representations that fuse different temporal-spatial dependencies. Then, a TUL layer is used to associate the trajectories with the corresponding users in the representation space using a two-stage training model. Experimental results on check-in mobility datasets from three real-world cities and the nationwide U.S. demonstrate the superiority of ScaleTUL over state-of-the-art baselines for large-scale TUL tasks.
TPAoI: Ensuring Fresh Service Status at the Network Edge in Compute-First Networking
Dec 24, 2024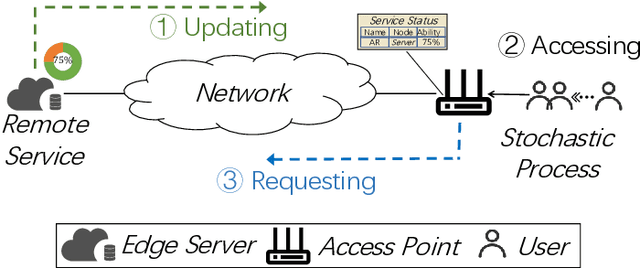
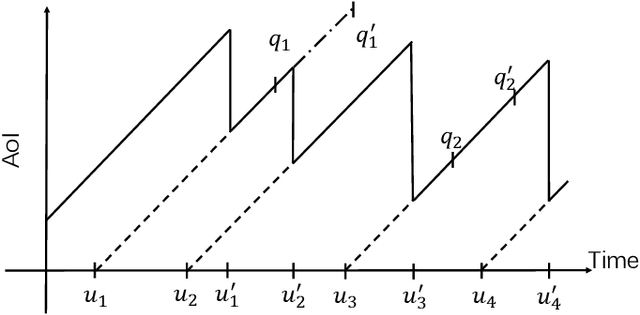
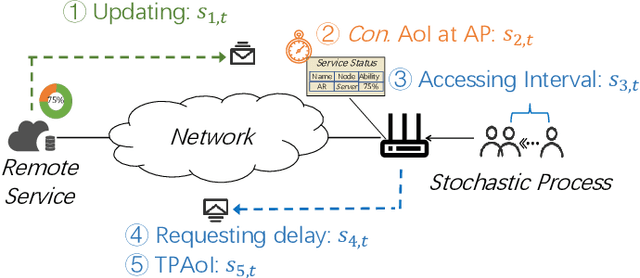
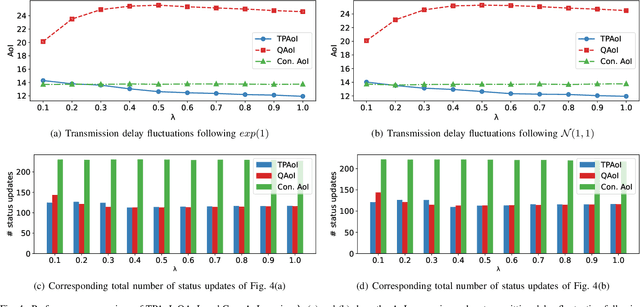
In compute-first networking, maintaining fresh and accurate status information at the network edge is crucial for effective access to remote services. This process typically involves three phases: Status updating, user accessing, and user requesting. However, current studies on status effectiveness, such as Age of Information at Query (QAoI), do not comprehensively cover all these phases. Therefore, this paper introduces a novel metric, TPAoI, aimed at optimizing update decisions by measuring the freshness of service status. The stochastic nature of edge environments, characterized by unpredictable communication delays in updating, requesting, and user access times, poses a significant challenge when modeling. To address this, we model the problem as a Markov Decision Process (MDP) and employ a Dueling Double Deep Q-Network (D3QN) algorithm for optimization. Extensive experiments demonstrate that the proposed TPAoI metric effectively minimizes AoI, ensuring timely and reliable service updates in dynamic edge environments. Results indicate that TPAoI reduces AoI by an average of 47\% compared to QAoI metrics and decreases update frequency by an average of 48\% relative to conventional AoI metrics, showing significant improvement.
AutoSculpt: A Pattern-based Model Auto-pruning Framework Using Reinforcement Learning and Graph Learning
Dec 24, 2024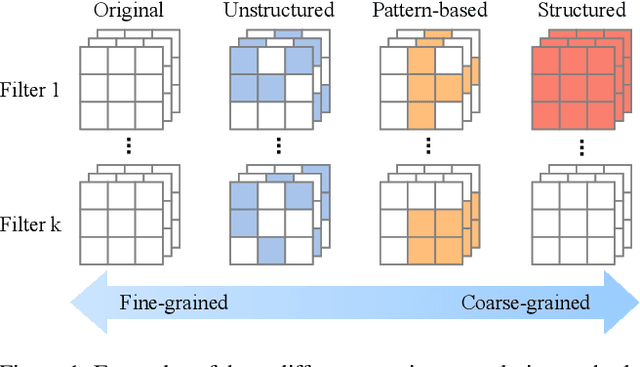
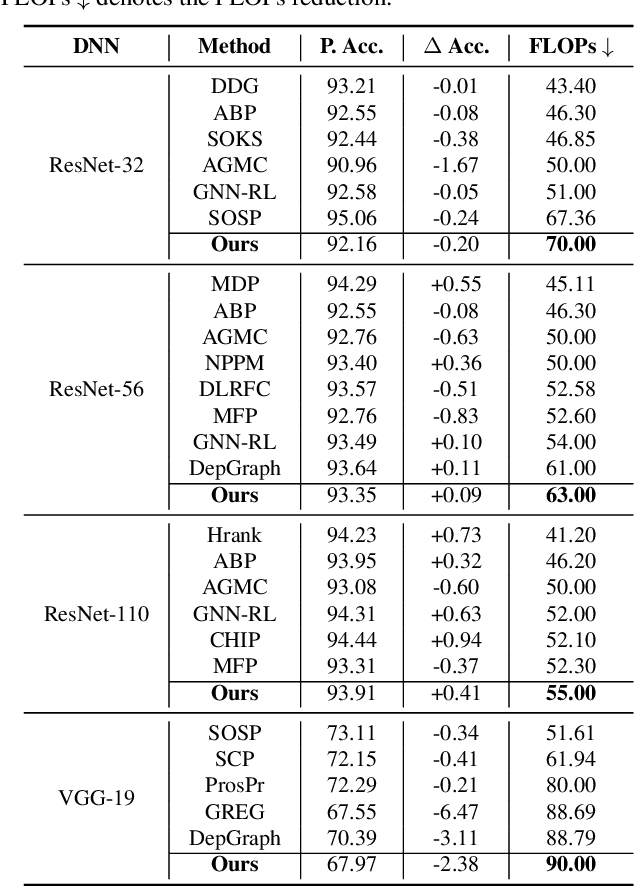
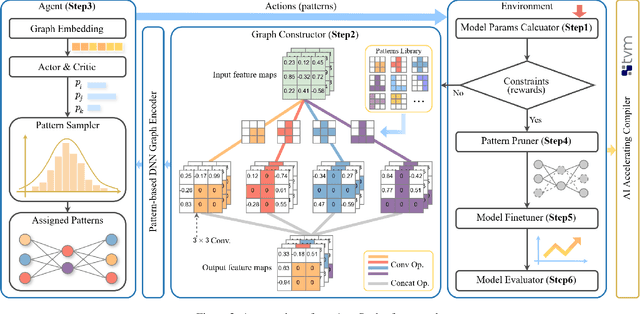
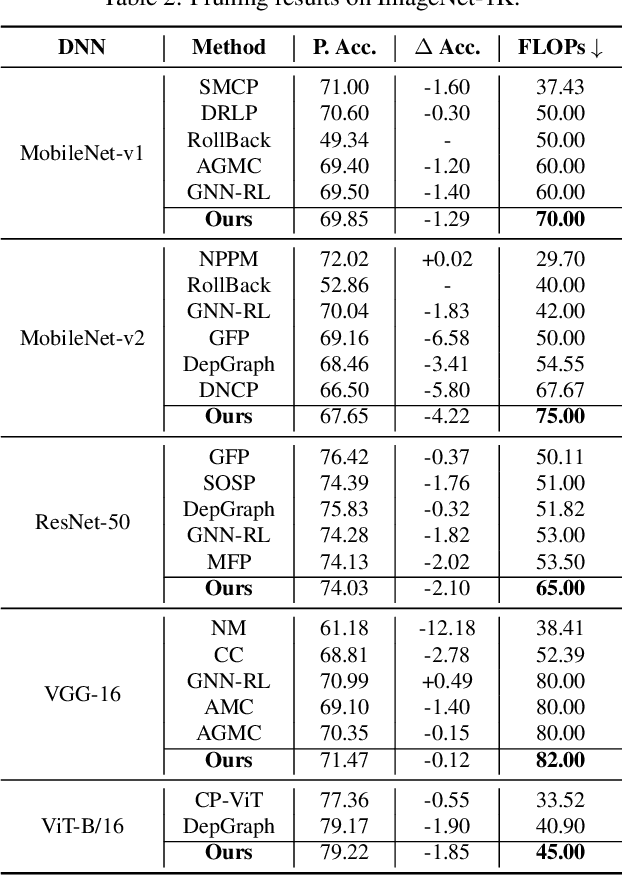
As deep neural networks (DNNs) are increasingly deployed on edge devices, optimizing models for constrained computational resources is critical. Existing auto-pruning methods face challenges due to the diversity of DNN models, various operators (e.g., filters), and the difficulty in balancing pruning granularity with model accuracy. To address these limitations, we introduce AutoSculpt, a pattern-based automated pruning framework designed to enhance efficiency and accuracy by leveraging graph learning and deep reinforcement learning (DRL). AutoSculpt automatically identifies and prunes regular patterns within DNN architectures that can be recognized by existing inference engines, enabling runtime acceleration. Three key steps in AutoSculpt include: (1) Constructing DNNs as graphs to encode their topology and parameter dependencies, (2) embedding computationally efficient pruning patterns, and (3) utilizing DRL to iteratively refine auto-pruning strategies until the optimal balance between compression and accuracy is achieved. Experimental results demonstrate the effectiveness of AutoSculpt across various architectures, including ResNet, MobileNet, VGG, and Vision Transformer, achieving pruning rates of up to 90% and nearly 18% improvement in FLOPs reduction, outperforming all baselines. The codes can be available at https://anonymous.4open.science/r/AutoSculpt-DDA0
UMGAD: Unsupervised Multiplex Graph Anomaly Detection
Nov 19, 2024



Graph anomaly detection (GAD) is a critical task in graph machine learning, with the primary objective of identifying anomalous nodes that deviate significantly from the majority. This task is widely applied in various real-world scenarios, including fraud detection and social network analysis. However, existing GAD methods still face two major challenges: (1) They are often limited to detecting anomalies in single-type interaction graphs and struggle with multiple interaction types in multiplex heterogeneous graphs; (2) In unsupervised scenarios, selecting appropriate anomaly score thresholds remains a significant challenge for accurate anomaly detection. To address the above challenges, we propose a novel Unsupervised Multiplex Graph Anomaly Detection method, named UMGAD. We first learn multi-relational correlations among nodes in multiplex heterogeneous graphs and capture anomaly information during node attribute and structure reconstruction through graph-masked autoencoder (GMAE). Then, to further weaken the influence of noise and redundant information on abnormal information extraction, we generate attribute-level and subgraph-level augmented-view graphs respectively, and perform attribute and structure reconstruction through GMAE. Finally, We learn to optimize node attributes and structural features through contrastive learning between original-view and augmented-view graphs to improve the model's ability to capture anomalies. Meanwhile, we also propose a new anomaly score threshold selection strategy, which allows the model to be independent of the ground truth in real unsupervised scenarios. Extensive experiments on four datasets show that our \model significantly outperforms state-of-the-art methods, achieving average improvements of 13.48% in AUC and 11.68% in Macro-F1 across all datasets.