 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond Guess: Detecting Uncertainty Through Abstention and Answer Stability in Small Language Models
May 25, 2026Large language models often generate confident but incorrect answers rather than abstaining when uncertain. This problem is particularly acute for small language models (SLMs), where computational constraints and autonomous operation amplify the need for reliable uncertainty detection. We propose _Second Guess_, a lightweight, parameter-free prompting technique for abstention in multiple-choice question answering (MCQA) that is well-suited for SLMs. Our key empirical insight is that models which truly know an answer will select it consistently, while uncertain models exhibit unstable behavior when an ``I don't know'' option is added. Evaluated on four open models (2B-8B parameters) and four benchmarks, Second Guess achieves the highest composite risk improvement of 10.81\%. Notably, it maintains an 8\% composite risk improvement on fine-tuned models where entropy-based methods degrade, and improves most for lower-performing models. All code and results required to reproduce this work is available in https://github.com/Mystic-Slice/second-guess
A Compound AI Agent for Conversational Grant Discovery
May 04, 2026Research funding discovery remains fundamentally fragmented: researchers navigate disparate agency portals (e.g., in the United States, NSF, NIH, DARPA, Grants.gov, and many others) with heterogeneous interfaces, search capabilities, and data schemas. We present a compound AI system that unifies this landscape through two tightly coupled components: (1) an aggregation layer that autonomously collects, normalizes, and indexes almost 12,000 federal and nonprofit opportunities from fragmented sources via LLM-equipped browser agents, maintaining a biweekly-updated unified database; and (2) an agentic ReAct-based query processing layer that interprets research context (including from PDF documents) and employs hybrid search combining a structured index with selective web search to retrieve relevant opportunities - while avoiding LLM hallucination. The conversational interface supports iterative refinement through multi-turn interactions, allowing researchers to progressively apply constraints without reformulating their core research description. Results stream in real time with full transparency of intermediate reasoning, enabling appropriate calibration of user trust. Currently used by almost 3,000+ users, our approach demonstrates the feasibility of compound AI in reducing grant discovery time from 30--45 minutes (manual, fragmented portal searches) to under 10 minutes (unified, conversational search).
An Analysis of Artificial Intelligence Adoption in NIH-Funded Research
Apr 08, 2026Understanding the landscape of artificial intelligence (AI) and machine learning (ML) adoption across the National Institutes of Health (NIH) portfolio is critical for research funding strategy, institutional planning, and health policy. The advent of large language models (LLMs) has fundamentally transformed research landscape analysis, enabling researchers to perform large-scale semantic extraction from thousands of unstructured research documents. In this paper, we illustrate a human-in-the-loop research methodology for LLMs to automatically classify and summarize research descriptions at scale. Using our methodology, we present a comprehensive analysis of 58,746 NIH-funded biomedical research projects from 2025. We show that: (1) AI constitutes 15.9% of the NIH portfolio with a 13.4% funding premium, concentrated in discovery, prediction, and data integration across disease domains; (2) a critical research-to-deployment gap exists, with 79% of AI projects remaining in research/development stages while only 14.7% engage in clinical deployment or implementation; and (3) health disparities research is severely underrepresented at just 5.7% of AI-funded work despite its importance to NIH's equity mission. These findings establish a framework for evidence-based policy interventions to align the NIH AI portfolio with health equity goals and strategic research priorities.
Beyond the Star Rating: A Scalable Framework for Aspect-Based Sentiment Analysis Using LLMs and Text Classification
Feb 24, 2026Customer-provided reviews have become an important source of information for business owners and other customers alike. However, effectively analyzing millions of unstructured reviews remains challenging. While large language models (LLMs) show promise for natural language understanding, their application to large-scale review analysis has been limited by computational costs and scalability concerns. This study proposes a hybrid approach that uses LLMs for aspect identification while employing classic machine-learning methods for sentiment classification at scale. Using ChatGPT to analyze sampled restaurant reviews, we identified key aspects of dining experiences and developed sentiment classifiers using human-labeled reviews, which we subsequently applied to 4.7 million reviews collected over 17 years from a major online platform. Regression analysis reveals that our machine-labeled aspects significantly explain variance in overall restaurant ratings across different aspects of dining experiences, cuisines, and geographical regions. Our findings demonstrate that combining LLMs with traditional machine learning approaches can effectively automate aspect-based sentiment analysis of large-scale customer feedback, suggesting a practical framework for both researchers and practitioners in the hospitality industry and potentially, other service sectors.
Structural shifts in institutional participation and collaboration within the AI arXiv preprint research ecosystem
Feb 03, 2026The emergence of large language models (LLMs) represents a significant technological shift within the scientific ecosystem, particularly within the field of artificial intelligence (AI). This paper examines structural changes in the AI research landscape using a dataset of arXiv preprints (cs.AI) from 2021 through 2025. Given the rapid pace of AI development, the preprint ecosystem has become a critical barometer for real-time scientific shifts, often preceding formal peer-reviewed publication by months or years. By employing a multi-stage data collection and enrichment pipeline in conjunction with LLM-based institution classification, we analyze the evolution of publication volumes, author team sizes, and academic--industry collaboration patterns. Our results reveal an unprecedented surge in publication output following the introduction of ChatGPT, with academic institutions continuing to provide the largest volume of research. However, we observe that academic--industry collaboration is still suppressed, as measured by a Normalized Collaboration Index (NCI) that remains significantly below the random-mixing baseline across all major subfields. These findings highlight a continuing institutional divide and suggest that the capital-intensive nature of generative AI research may be reshaping the boundaries of scientific collaboration.
LOGicalThought: Logic-Based Ontological Grounding of LLMs for High-Assurance Reasoning
Oct 02, 2025High-assurance reasoning, particularly in critical domains such as law and medicine, requires conclusions that are accurate, verifiable, and explicitly grounded in evidence. This reasoning relies on premises codified from rules, statutes, and contracts, inherently involving defeasible or non-monotonic logic due to numerous exceptions, where the introduction of a single fact can invalidate general rules, posing significant challenges. While large language models (LLMs) excel at processing natural language, their capabilities in standard inference tasks do not translate to the rigorous reasoning required over high-assurance text guidelines. Core reasoning challenges within such texts often manifest specific logical structures involving negation, implication, and, most critically, defeasible rules and exceptions. In this paper, we propose a novel neurosymbolically-grounded architecture called LOGicalThought (LogT) that uses an advanced logical language and reasoner in conjunction with an LLM to construct a dual symbolic graph context and logic-based context. These two context representations transform the problem from inference over long-form guidelines into a compact grounded evaluation. Evaluated on four multi-domain benchmarks against four baselines, LogT improves overall performance by 11.84% across all LLMs. Performance improves significantly across all three modes of reasoning: by up to +10.2% on negation, +13.2% on implication, and +5.5% on defeasible reasoning compared to the strongest baseline.
Code-Driven Planning in Grid Worlds with Large Language Models
May 15, 2025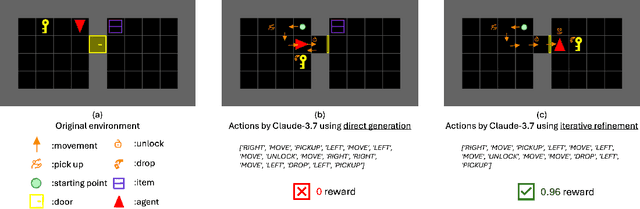
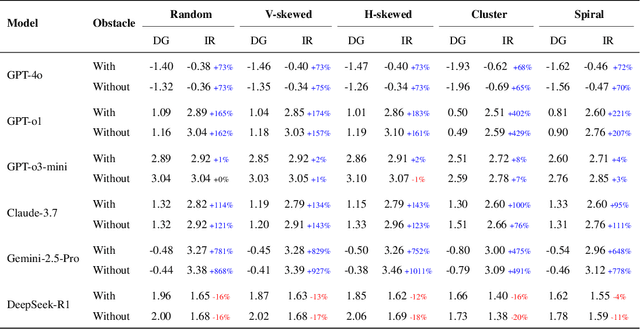
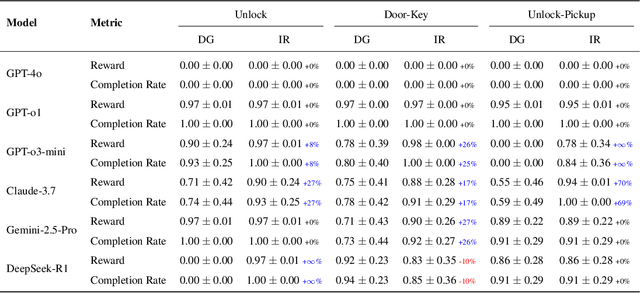
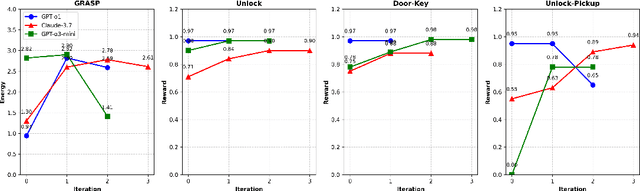
We propose an iterative programmatic planning (IPP) framework for solving grid-based tasks by synthesizing interpretable agent policies expressed in code using large language models (LLMs). Instead of relying on traditional search or reinforcement learning, our approach uses code generation as policy synthesis, where the LLM outputs executable programs that map environment states to action sequences. Our proposed architecture incorporates several prompting strategies, including direct code generation, pseudocode-conditioned refinement, and curriculum-based prompting, but also includes an iterative refinement mechanism that updates code based on task performance feedback. We evaluate our approach using six leading LLMs and two challenging grid-based benchmarks (GRASP and MiniGrid). Our IPP framework demonstrates improvements over direct code generation ranging from 10\% to as much as 10x across five of the six models and establishes a new state-of-the-art result for GRASP. IPP is found to significantly outperform direct elicitation of a solution from GPT-o3-mini (by 63\% on MiniGrid to 116\% on GRASP), demonstrating the viability of the overall approach. Computational costs of all code generation approaches are similar. While code generation has a higher initial prompting cost compared to direct solution elicitation (\$0.08 per task vs. \$0.002 per instance for GPT-o3-mini), the code can be reused for any number of instances, making the amortized cost significantly lower (by 400x on GPT-o3-mini across the complete GRASP benchmark).
Navigating Semantic Relations: Challenges for Language Models in Abstract Common-Sense Reasoning
Feb 19, 2025


Large language models (LLMs) have achieved remarkable performance in generating human-like text and solving reasoning tasks of moderate complexity, such as question-answering and mathematical problem-solving. However, their capabilities in tasks requiring deeper cognitive skills, such as common-sense understanding and abstract reasoning, remain under-explored. In this paper, we systematically evaluate abstract common-sense reasoning in LLMs using the ConceptNet knowledge graph. We propose two prompting approaches: instruct prompting, where models predict plausible semantic relationships based on provided definitions, and few-shot prompting, where models identify relations using examples as guidance. Our experiments with the gpt-4o-mini model show that in instruct prompting, consistent performance is obtained when ranking multiple relations but with substantial decline when the model is restricted to predicting only one relation. In few-shot prompting, the model's accuracy improves significantly when selecting from five relations rather than the full set, although with notable bias toward certain relations. These results suggest significant gaps still, even in commercially used LLMs' abstract common-sense reasoning abilities, compared to human-level understanding. However, the findings also highlight the promise of careful prompt engineering, based on selective retrieval, for obtaining better performance.
Humanlike Cognitive Patterns as Emergent Phenomena in Large Language Models
Dec 20, 2024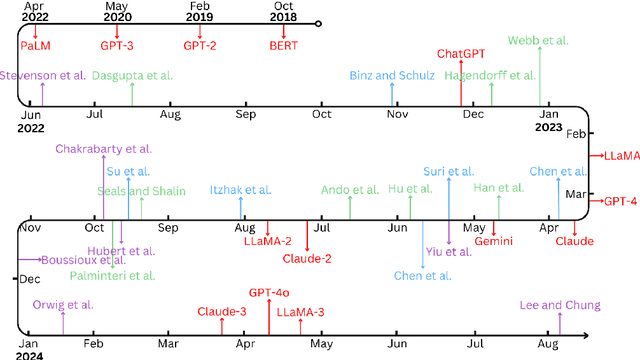
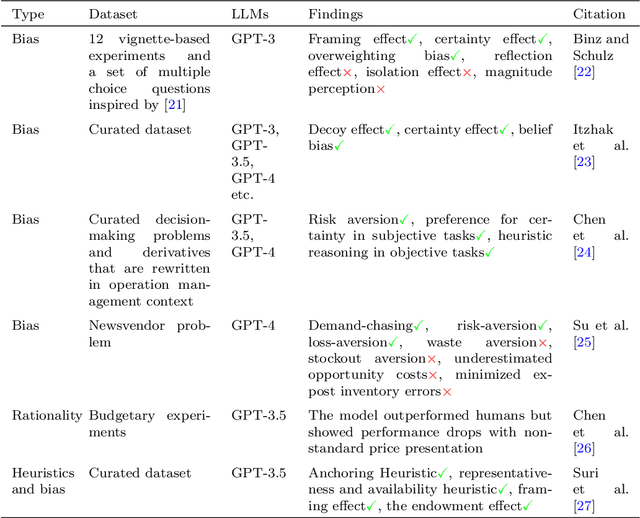
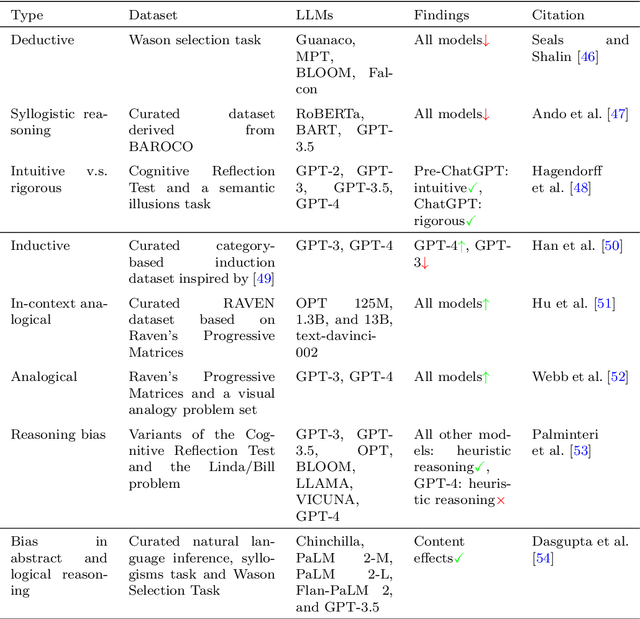
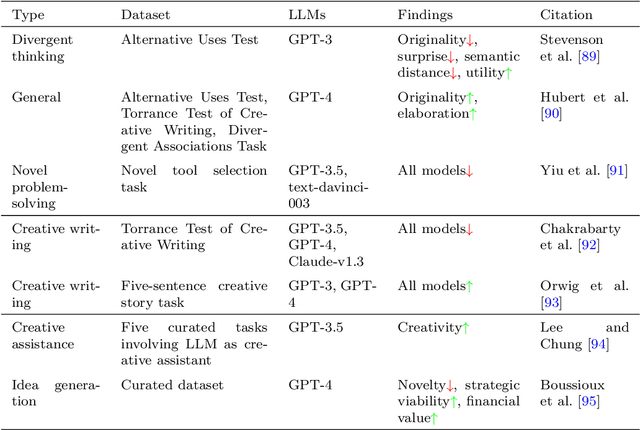
Research on emergent patterns in Large Language Models (LLMs) has gained significant traction in both psychology and artificial intelligence, motivating the need for a comprehensive review that offers a synthesis of this complex landscape. In this article, we systematically review LLMs' capabilities across three important cognitive domains: decision-making biases, reasoning, and creativity. We use empirical studies drawing on established psychological tests and compare LLMs' performance to human benchmarks. On decision-making, our synthesis reveals that while LLMs demonstrate several human-like biases, some biases observed in humans are absent, indicating cognitive patterns that only partially align with human decision-making. On reasoning, advanced LLMs like GPT-4 exhibit deliberative reasoning akin to human System-2 thinking, while smaller models fall short of human-level performance. A distinct dichotomy emerges in creativity: while LLMs excel in language-based creative tasks, such as storytelling, they struggle with divergent thinking tasks that require real-world context. Nonetheless, studies suggest that LLMs hold considerable potential as collaborators, augmenting creativity in human-machine problem-solving settings. Discussing key limitations, we also offer guidance for future research in areas such as memory, attention, and open-source model development.
SelECT-SQL: Self-correcting ensemble Chain-of-Thought for Text-to-SQL
Sep 16, 2024



In recent years,Text-to-SQL, the problem of automatically converting questions posed in natural language to formal SQL queries, has emerged as an important problem at the intersection of natural language processing and data management research. Large language models (LLMs) have delivered impressive performance when used in an off-the-shelf performance, but still fall significantly short of expected expert-level performance. Errors are especially probable when a nuanced understanding is needed of database schemas, questions, and SQL clauses to do proper Text-to-SQL conversion. We introduce SelECT-SQL, a novel in-context learning solution that uses an algorithmic combination of chain-of-thought (CoT) prompting, self-correction, and ensemble methods to yield a new state-of-the-art result on challenging Text-to-SQL benchmarks. Specifically, when configured using GPT-3.5-Turbo as the base LLM, SelECT-SQL achieves 84.2% execution accuracy on the Spider leaderboard's development set, exceeding both the best results of other baseline GPT-3.5-Turbo-based solutions (81.1%), and the peak performance (83.5%) of the GPT-4 result reported on the leaderboard.