 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Estimative Uncertainty in Large Language Models
Paper and Code
May 24, 2024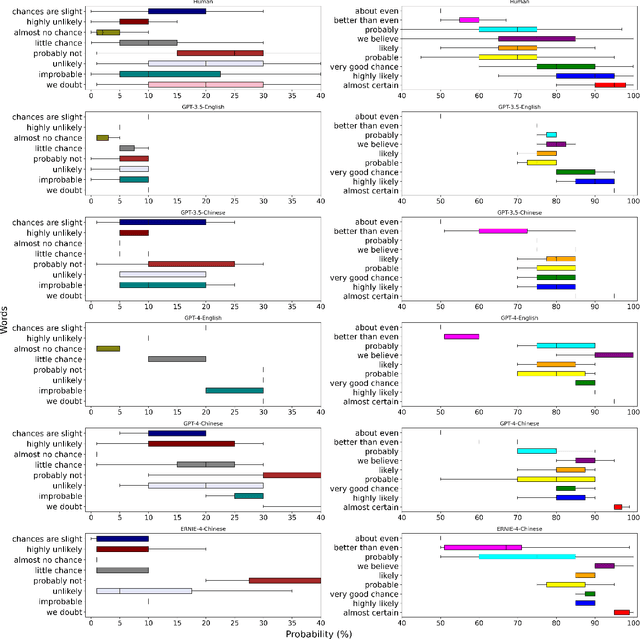

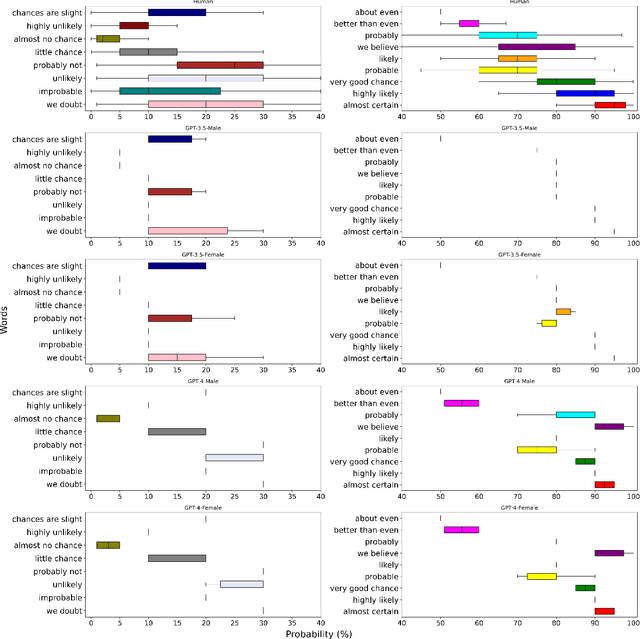

Words of estimative probability (WEPs), such as ''maybe'' or ''probably not'' are ubiquitous in natural language for communicating estimative uncertainty, compared with direct statements involving numerical probability. Human estimative uncertainty, and its calibration with numerical estimates, has long been an area of study -- including by intelligence agencies like the CIA. This study compares estimative uncertainty in commonly used large language models (LLMs) like GPT-4 and ERNIE-4 to that of humans, and to each other. Here we show that LLMs like GPT-3.5 and GPT-4 align with human estimates for some, but not all, WEPs presented in English. Divergence is also observed when the LLM is presented with gendered roles and Chinese contexts. Further study shows that an advanced LLM like GPT-4 can consistently map between statistical and estimative uncertainty, but a significant performance gap remains. The results contribute to a growing body of research on human-LLM alignment.