 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Driven Planning in Grid Worlds with Large Language Models
May 15, 2025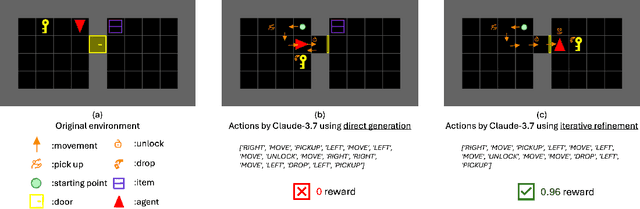
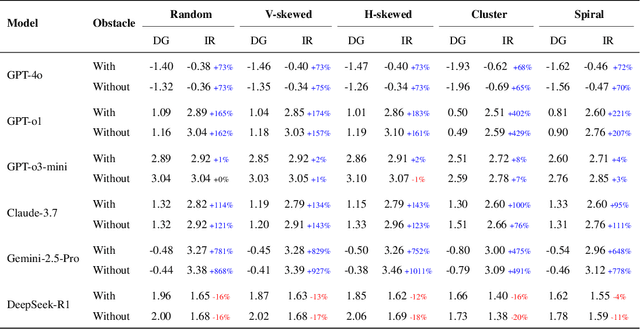
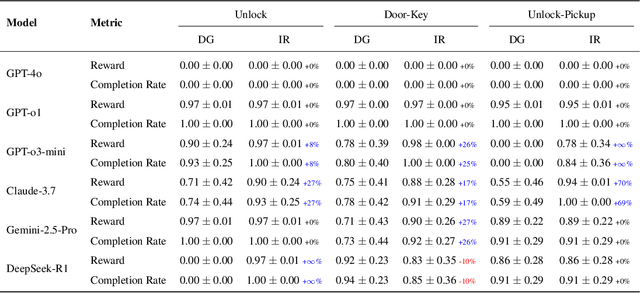
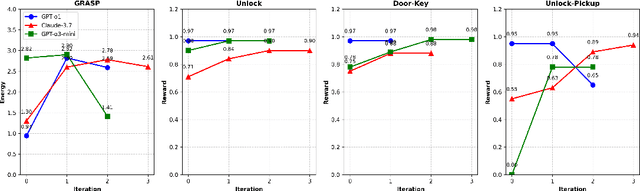
We propose an iterative programmatic planning (IPP) framework for solving grid-based tasks by synthesizing interpretable agent policies expressed in code using large language models (LLMs). Instead of relying on traditional search or reinforcement learning, our approach uses code generation as policy synthesis, where the LLM outputs executable programs that map environment states to action sequences. Our proposed architecture incorporates several prompting strategies, including direct code generation, pseudocode-conditioned refinement, and curriculum-based prompting, but also includes an iterative refinement mechanism that updates code based on task performance feedback. We evaluate our approach using six leading LLMs and two challenging grid-based benchmarks (GRASP and MiniGrid). Our IPP framework demonstrates improvements over direct code generation ranging from 10\% to as much as 10x across five of the six models and establishes a new state-of-the-art result for GRASP. IPP is found to significantly outperform direct elicitation of a solution from GPT-o3-mini (by 63\% on MiniGrid to 116\% on GRASP), demonstrating the viability of the overall approach. Computational costs of all code generation approaches are similar. While code generation has a higher initial prompting cost compared to direct solution elicitation (\$0.08 per task vs. \$0.002 per instance for GPT-o3-mini), the code can be reused for any number of instances, making the amortized cost significantly lower (by 400x on GPT-o3-mini across the complete GRASP benchmark).
Humanlike Cognitive Patterns as Emergent Phenomena in Large Language Models
Dec 20, 2024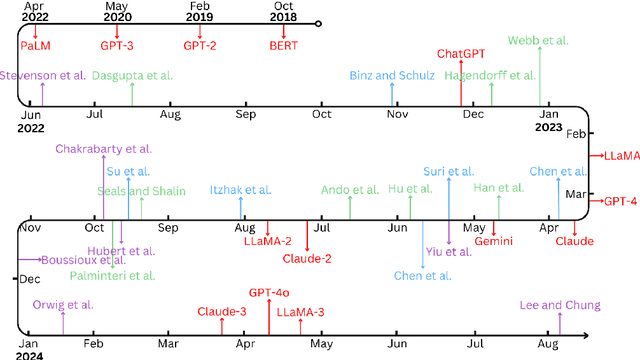
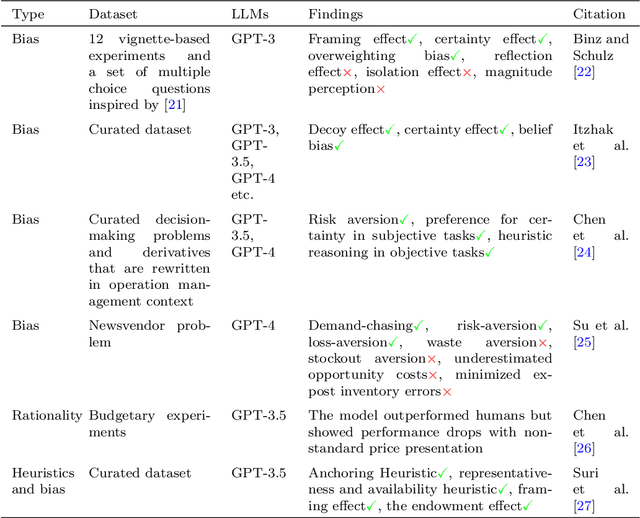
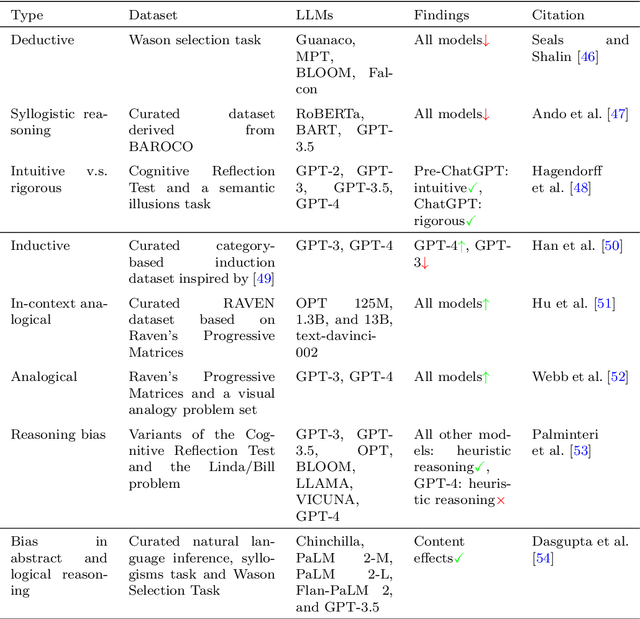
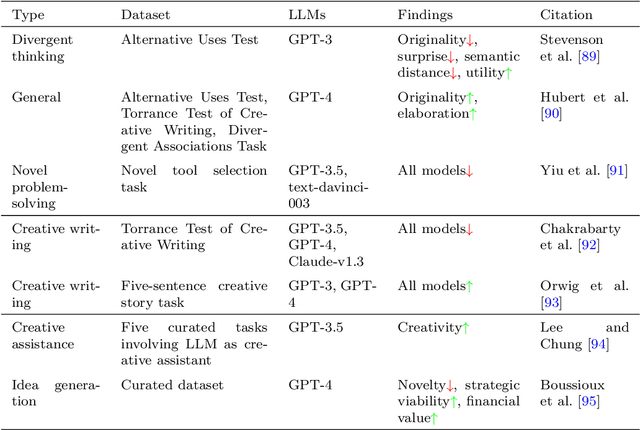
Research on emergent patterns in Large Language Models (LLMs) has gained significant traction in both psychology and artificial intelligence, motivating the need for a comprehensive review that offers a synthesis of this complex landscape. In this article, we systematically review LLMs' capabilities across three important cognitive domains: decision-making biases, reasoning, and creativity. We use empirical studies drawing on established psychological tests and compare LLMs' performance to human benchmarks. On decision-making, our synthesis reveals that while LLMs demonstrate several human-like biases, some biases observed in humans are absent, indicating cognitive patterns that only partially align with human decision-making. On reasoning, advanced LLMs like GPT-4 exhibit deliberative reasoning akin to human System-2 thinking, while smaller models fall short of human-level performance. A distinct dichotomy emerges in creativity: while LLMs excel in language-based creative tasks, such as storytelling, they struggle with divergent thinking tasks that require real-world context. Nonetheless, studies suggest that LLMs hold considerable potential as collaborators, augmenting creativity in human-machine problem-solving settings. Discussing key limitations, we also offer guidance for future research in areas such as memory, attention, and open-source model development.
GRASP: A Grid-Based Benchmark for Evaluating Commonsense Spatial Reasoning
Jul 02, 2024



Spatial reasoning, an important faculty of human cognition with many practical applications, is one of the core commonsense skills that is not purely language-based and, for satisfying (as opposed to optimal) solutions, requires some minimum degree of planning. Existing benchmarks of Commonsense Spatial Reasoning (CSR) tend to evaluate how Large Language Models (LLMs) interpret text-based spatial descriptions rather than directly evaluate a plan produced by the LLM in response to a spatial reasoning scenario. In this paper, we construct a large-scale benchmark called $\textbf{GRASP}$, which consists of 16,000 grid-based environments where the agent is tasked with an energy collection problem. These environments include 100 grid instances instantiated using each of the 160 different grid settings, involving five different energy distributions, two modes of agent starting position, and two distinct obstacle configurations, as well as three kinds of agent constraints. Using GRASP, we compare classic baseline approaches, such as random walk and greedy search methods, with advanced LLMs like GPT-3.5-Turbo and GPT-4o. The experimental results indicate that even these advanced LLMs struggle to consistently achieve satisfactory solutions.
Is persona enough for personality? Using ChatGPT to reconstruct an agent's latent personality from simple descriptions
Jun 18, 2024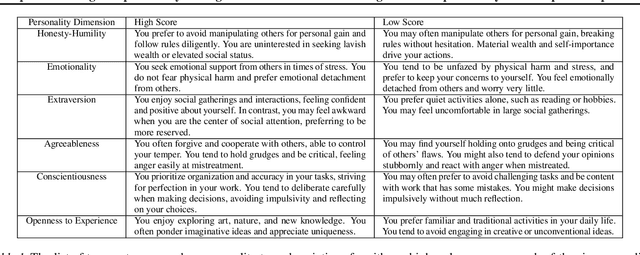
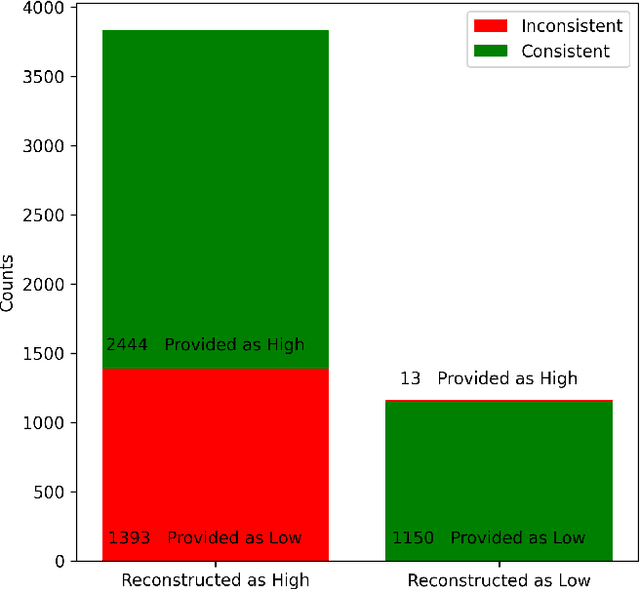
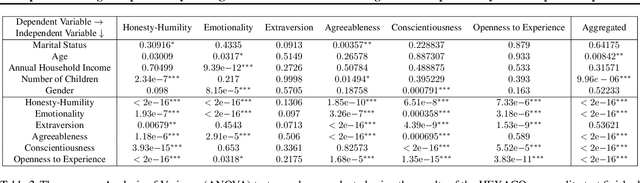
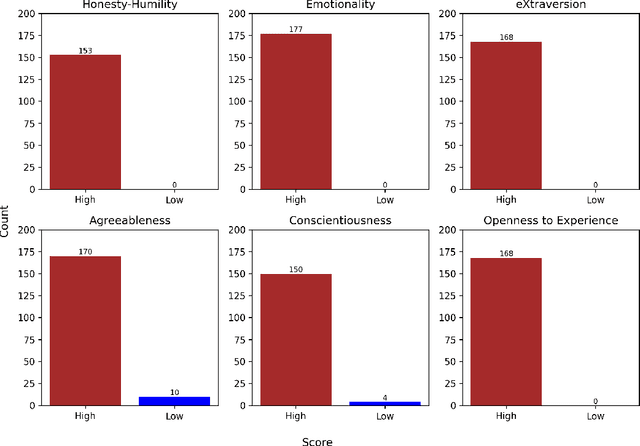
Personality, a fundamental aspect of human cognition, contains a range of traits that influence behaviors, thoughts, and emotions. This paper explores the capabilities of large language models (LLMs) in reconstructing these complex cognitive attributes based only on simple descriptions containing socio-demographic and personality type information. Utilizing the HEXACO personality framework, our study examines the consistency of LLMs in recovering and predicting underlying (latent) personality dimensions from simple descriptions. Our experiments reveal a significant degree of consistency in personality reconstruction, although some inconsistencies and biases, such as a tendency to default to positive traits in the absence of explicit information, are also observed. Additionally, socio-demographic factors like age and number of children were found to influence the reconstructed personality dimensions. These findings have implications for building sophisticated agent-based simulacra using LLMs and highlight the need for further research on robust personality generation in LLMs.
An Evaluation of Estimative Uncertainty in Large Language Models
May 24, 2024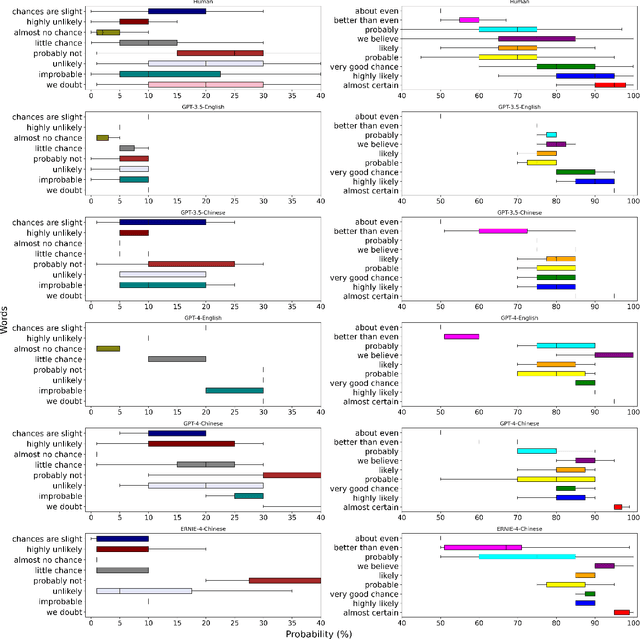

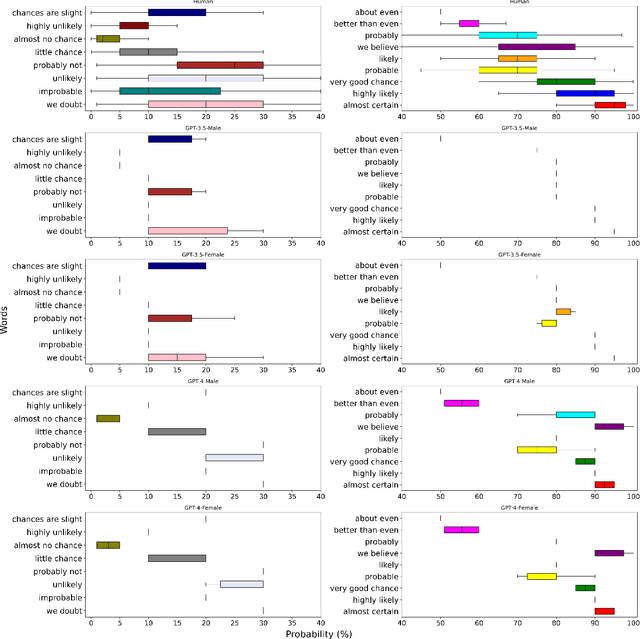

Words of estimative probability (WEPs), such as ''maybe'' or ''probably not'' are ubiquitous in natural language for communicating estimative uncertainty, compared with direct statements involving numerical probability. Human estimative uncertainty, and its calibration with numerical estimates, has long been an area of study -- including by intelligence agencies like the CIA. This study compares estimative uncertainty in commonly used large language models (LLMs) like GPT-4 and ERNIE-4 to that of humans, and to each other. Here we show that LLMs like GPT-3.5 and GPT-4 align with human estimates for some, but not all, WEPs presented in English. Divergence is also observed when the LLM is presented with gendered roles and Chinese contexts. Further study shows that an advanced LLM like GPT-4 can consistently map between statistical and estimative uncertainty, but a significant performance gap remains. The results contribute to a growing body of research on human-LLM alignment.
A Pilot Evaluation of ChatGPT and DALL-E 2 on Decision Making and Spatial Reasoning
Feb 15, 2023We conduct a pilot study selectively evaluating the cognitive abilities (decision making and spatial reasoning) of two recently released generative transformer models, ChatGPT and DALL-E 2. Input prompts were constructed following neutral a priori guidelines, rather than adversarial intent. Post hoc qualitative analysis of the outputs shows that DALL-E 2 is able to generate at least one correct image for each spatial reasoning prompt, but most images generated are incorrect (even though the model seems to have a clear understanding of the objects mentioned in the prompt). Similarly, in evaluating ChatGPT on the rationality axioms developed under the classical Von Neumann-Morgenstern utility theorem, we find that, although it demonstrates some level of rational decision-making, many of its decisions violate at least one of the axioms even under reasonable constructions of preferences, bets, and decision-making prompts. ChatGPT's outputs on such problems generally tended to be unpredictable: even as it made irrational decisions (or employed an incorrect reasoning process) for some simpler decision-making problems, it was able to draw correct conclusions for more complex bet structures. We briefly comment on the nuances and challenges involved in scaling up such a 'cognitive' evaluation or conducting it with a closed set of answer keys ('ground truth'), given that these models are inherently generative and open-ended in responding to prompts.
Can Language Representation Models Think in Bets?
Oct 14, 2022
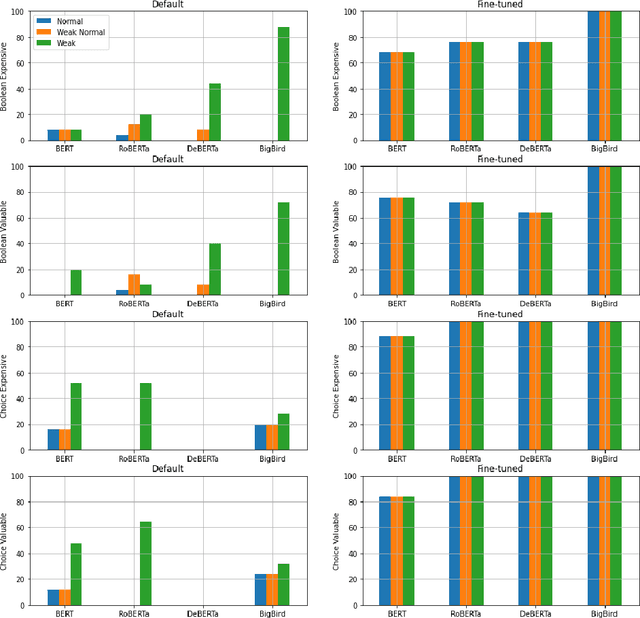
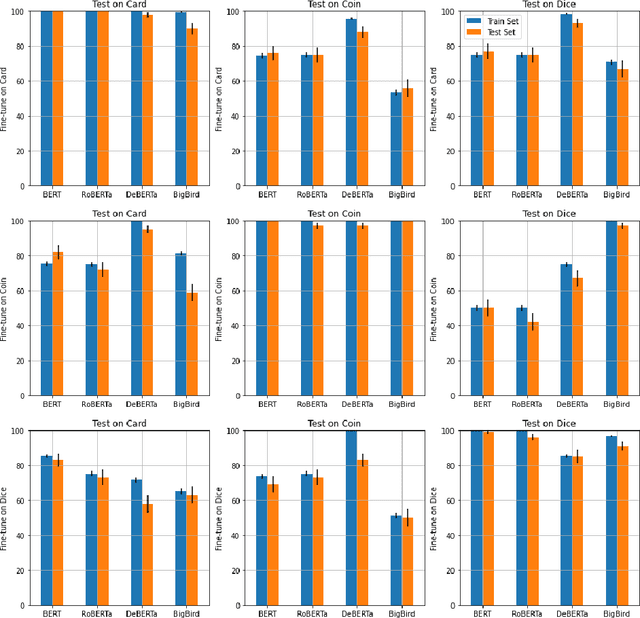
In recent years, transformer-based language representation models (LRMs) have achieved state-of-the-art results on difficult natural language understanding problems, such as question answering and text summarization. As these models are integrated into real-world applications, evaluating their ability to make rational decisions is an important research agenda, with practical ramifications. This article investigates LRMs' rational decision-making ability through a carefully designed set of decision-making benchmarks and experiments. Inspired by classic work in cognitive science, we model the decision-making problem as a bet. We then investigate an LRM's ability to choose outcomes that have optimal, or at minimum, positive expected gain. Through a robust body of experiments on four established LRMs, we show that a model is only able to `think in bets' if it is first fine-tuned on bet questions with an identical structure. Modifying the bet question's structure, while still retaining its fundamental characteristics, decreases an LRM's performance by more than 25\%, on average, although absolute performance remains well above random. LRMs are also found to be more rational when selecting outcomes with non-negative expected gain, rather than optimal or strictly positive expected gain. Our results suggest that LRMs could potentially be applied to tasks that rely on cognitive decision-making skills, but that more research is necessary before they can robustly make rational decisions.