 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Artificial Intelligence Adoption in NIH-Funded Research
Apr 08, 2026Understanding the landscape of artificial intelligence (AI) and machine learning (ML) adoption across the National Institutes of Health (NIH) portfolio is critical for research funding strategy, institutional planning, and health policy. The advent of large language models (LLMs) has fundamentally transformed research landscape analysis, enabling researchers to perform large-scale semantic extraction from thousands of unstructured research documents. In this paper, we illustrate a human-in-the-loop research methodology for LLMs to automatically classify and summarize research descriptions at scale. Using our methodology, we present a comprehensive analysis of 58,746 NIH-funded biomedical research projects from 2025. We show that: (1) AI constitutes 15.9% of the NIH portfolio with a 13.4% funding premium, concentrated in discovery, prediction, and data integration across disease domains; (2) a critical research-to-deployment gap exists, with 79% of AI projects remaining in research/development stages while only 14.7% engage in clinical deployment or implementation; and (3) health disparities research is severely underrepresented at just 5.7% of AI-funded work despite its importance to NIH's equity mission. These findings establish a framework for evidence-based policy interventions to align the NIH AI portfolio with health equity goals and strategic research priorities.
LOGicalThought: Logic-Based Ontological Grounding of LLMs for High-Assurance Reasoning
Oct 02, 2025High-assurance reasoning, particularly in critical domains such as law and medicine, requires conclusions that are accurate, verifiable, and explicitly grounded in evidence. This reasoning relies on premises codified from rules, statutes, and contracts, inherently involving defeasible or non-monotonic logic due to numerous exceptions, where the introduction of a single fact can invalidate general rules, posing significant challenges. While large language models (LLMs) excel at processing natural language, their capabilities in standard inference tasks do not translate to the rigorous reasoning required over high-assurance text guidelines. Core reasoning challenges within such texts often manifest specific logical structures involving negation, implication, and, most critically, defeasible rules and exceptions. In this paper, we propose a novel neurosymbolically-grounded architecture called LOGicalThought (LogT) that uses an advanced logical language and reasoner in conjunction with an LLM to construct a dual symbolic graph context and logic-based context. These two context representations transform the problem from inference over long-form guidelines into a compact grounded evaluation. Evaluated on four multi-domain benchmarks against four baselines, LogT improves overall performance by 11.84% across all LLMs. Performance improves significantly across all three modes of reasoning: by up to +10.2% on negation, +13.2% on implication, and +5.5% on defeasible reasoning compared to the strongest baseline.
What if Red Can Talk? Dynamic Dialogue Generation Using Large Language Models
Jul 29, 2024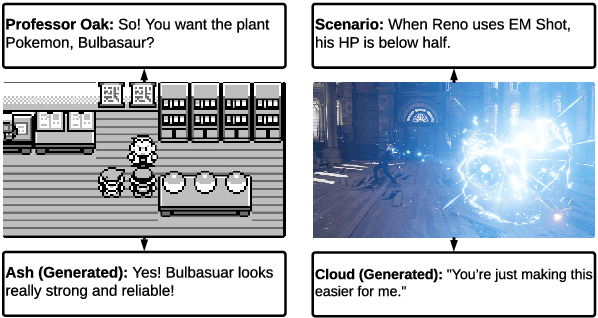
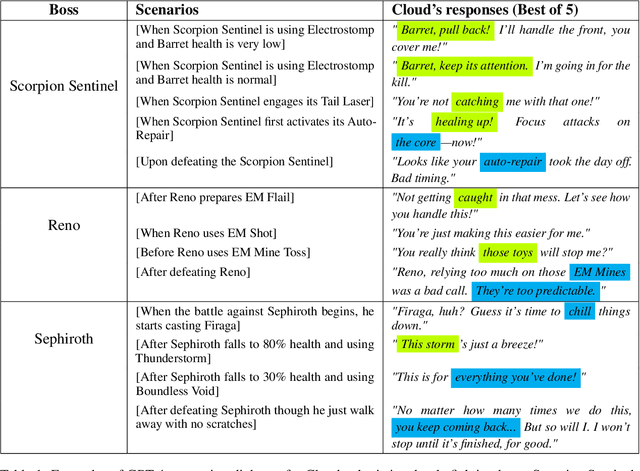
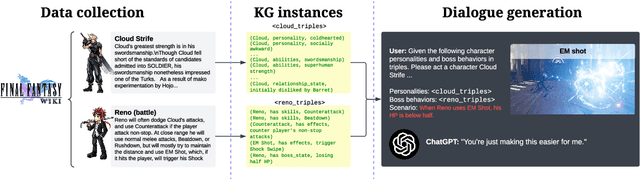
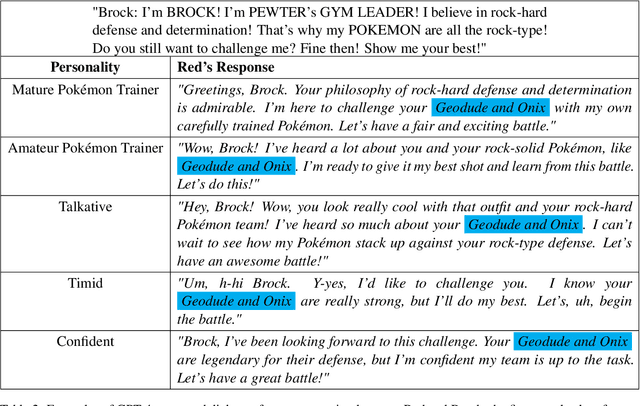
Role-playing games (RPGs) provide players with a rich, interactive world to explore. Dialogue serves as the primary means of communication between developers and players, manifesting in various forms such as guides, NPC interactions, and storytelling. While most games rely on written scripts to define the main story and character personalities, player immersion can be significantly enhanced through casual interactions between characters. With the advent of large language models (LLMs), we introduce a dialogue filler framework that utilizes LLMs enhanced by knowledge graphs to generate dynamic and contextually appropriate character interactions. We test this framework within the environments of Final Fantasy VII Remake and Pokemon, providing qualitative and quantitative evidence that demonstrates GPT-4's capability to act with defined personalities and generate dialogue. However, some flaws remain, such as GPT-4 being overly positive or more subtle personalities, such as maturity, tend to be of lower quality compared to more overt traits like timidity. This study aims to assist developers in crafting more nuanced filler dialogues, thereby enriching player immersion and enhancing the overall RPG experience.
Unsupervised Federated Domain Adaptation for Segmentation of MRI Images
Jan 14, 2024Automatic semantic segmentation of magnetic resonance imaging (MRI) images using deep neural networks greatly assists in evaluating and planning treatments for various clinical applications. However, training these models is conditioned on the availability of abundant annotated data to implement the end-to-end supervised learning procedure. Even if we annotate enough data, MRI images display considerable variability due to factors such as differences in patients, MRI scanners, and imaging protocols. This variability necessitates retraining neural networks for each specific application domain, which, in turn, requires manual annotation by expert radiologists for all new domains. To relax the need for persistent data annotation, we develop a method for unsupervised federated domain adaptation using multiple annotated source domains. Our approach enables the transfer of knowledge from several annotated source domains to adapt a model for effective use in an unannotated target domain. Initially, we ensure that the target domain data shares similar representations with each source domain in a latent embedding space, modeled as the output of a deep encoder, by minimizing the pair-wise distances of the distributions for the target domain and the source domains. We then employ an ensemble approach to leverage the knowledge obtained from all domains. We provide theoretical analysis and perform experiments on the MICCAI 2016 multi-site dataset to demonstrate our method is effective.
HALO: An Ontology for Representing Hallucinations in Generative Models
Dec 08, 2023Recent progress in generative AI, including large language models (LLMs) like ChatGPT, has opened up significant opportunities in fields ranging from natural language processing to knowledge discovery and data mining. However, there is also a growing awareness that the models can be prone to problems such as making information up or `hallucinations', and faulty reasoning on seemingly simple problems. Because of the popularity of models like ChatGPT, both academic scholars and citizen scientists have documented hallucinations of several different types and severity. Despite this body of work, a formal model for describing and representing these hallucinations (with relevant meta-data) at a fine-grained level, is still lacking. In this paper, we address this gap by presenting the Hallucination Ontology or HALO, a formal, extensible ontology written in OWL that currently offers support for six different types of hallucinations known to arise in LLMs, along with support for provenance and experimental metadata. We also collect and publish a dataset containing hallucinations that we inductively gathered across multiple independent Web sources, and show that HALO can be successfully used to model this dataset and answer competency questions.
How does prompt engineering affect ChatGPT performance on unsupervised entity resolution?
Oct 09, 2023



Entity Resolution (ER) is the problem of semi-automatically determining when two entities refer to the same underlying entity, with applications ranging from healthcare to e-commerce. Traditional ER solutions required considerable manual expertise, including feature engineering, as well as identification and curation of training data. In many instances, such techniques are highly dependent on the domain. With recent advent in large language models (LLMs), there is an opportunity to make ER much more seamless and domain-independent. However, it is also well known that LLMs can pose risks, and that the quality of their outputs can depend on so-called prompt engineering. Unfortunately, a systematic experimental study on the effects of different prompting methods for addressing ER, using LLMs like ChatGPT, has been lacking thus far. This paper aims to address this gap by conducting such a study. Although preliminary in nature, our results show that prompting can significantly affect the quality of ER, although it affects some metrics more than others, and can also be dataset dependent.