 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMD-ABSA: A Multi-Element Multi-Domain Dataset for Aspect-Based Sentiment Analysis
Jun 29, 2023



Aspect-based sentiment analysis is a long-standing research interest in the field of opinion mining, and in recent years, researchers have gradually shifted their focus from simple ABSA subtasks to end-to-end multi-element ABSA tasks. However, the datasets currently used in the research are limited to individual elements of specific tasks, usually focusing on in-domain settings, ignoring implicit aspects and opinions, and with a small data scale. To address these issues, we propose a large-scale Multi-Element Multi-Domain dataset (MEMD) that covers the four elements across five domains, including nearly 20,000 review sentences and 30,000 quadruples annotated with explicit and implicit aspects and opinions for ABSA research. Meanwhile, we evaluate generative and non-generative baselines on multiple ABSA subtasks under the open domain setting, and the results show that open domain ABSA as well as mining implicit aspects and opinions remain ongoing challenges to be addressed. The datasets are publicly released at \url{https://github.com/NUSTM/MEMD-ABSA}.
Challenges for Open-domain Targeted Sentiment Analysis
Apr 15, 2022
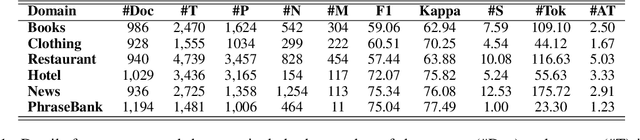
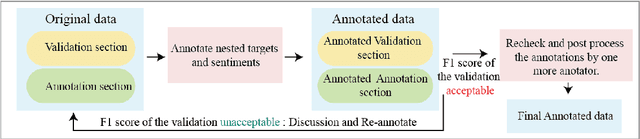
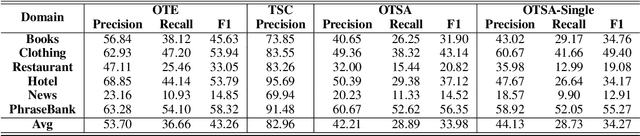
Since previous studies on open-domain targeted sentiment analysis are limited in dataset domain variety and sentence level, we propose a novel dataset consisting of 6,013 human-labeled data to extend the data domains in topics of interest and document level. Furthermore, we offer a nested target annotation schema to extract the complete sentiment information in documents, boosting the practicality and effectiveness of open-domain targeted sentiment analysis. Moreover, we leverage the pre-trained model BART in a sequence-to-sequence generation method for the task. Benchmark results show that there exists large room for improvement of open-domain targeted sentiment analysis. Meanwhile, experiments have shown that challenges remain in the effective use of open-domain data, long documents, the complexity of target structure, and domain variances.