 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning
Jul 22, 2025



Scientific reasoning is critical for developing AI scientists and supporting human researchers in advancing the frontiers of natural science discovery. However, the open-source community has primarily focused on mathematics and coding while neglecting the scientific domain, largely due to the absence of open, large-scale, high-quality, verifiable scientific reasoning datasets. To bridge this gap, we first present TextbookReasoning, an open dataset featuring truthful reference answers extracted from 12k university-level scientific textbooks, comprising 650k reasoning questions spanning 7 scientific disciplines. We further introduce MegaScience, a large-scale mixture of high-quality open-source datasets totaling 1.25 million instances, developed through systematic ablation studies that evaluate various data selection methodologies to identify the optimal subset for each publicly available scientific dataset. Meanwhile, we build a comprehensive evaluation system covering diverse subjects and question types across 15 benchmarks, incorporating comprehensive answer extraction strategies to ensure accurate evaluation metrics. Our experiments demonstrate that our datasets achieve superior performance and training efficiency with more concise response lengths compared to existing open-source scientific datasets. Furthermore, we train Llama3.1, Qwen2.5, and Qwen3 series base models on MegaScience, which significantly outperform the corresponding official instruct models in average performance. In addition, MegaScience exhibits greater effectiveness for larger and stronger models, suggesting a scaling benefit for scientific tuning. We release our data curation pipeline, evaluation system, datasets, and seven trained models to the community to advance scientific reasoning research.
MegaMath: Pushing the Limits of Open Math Corpora
Apr 03, 2025



Mathematical reasoning is a cornerstone of human intelligence and a key benchmark for advanced capabilities in large language models (LLMs). However, the research community still lacks an open, large-scale, high-quality corpus tailored to the demands of math-centric LLM pre-training. We present MegaMath, an open dataset curated from diverse, math-focused sources through following practices: (1) Revisiting web data: We re-extracted mathematical documents from Common Crawl with math-oriented HTML optimizations, fasttext-based filtering and deduplication, all for acquiring higher-quality data on the Internet. (2) Recalling Math-related code data: We identified high quality math-related code from large code training corpus, Stack-V2, further enhancing data diversity. (3) Exploring Synthetic data: We synthesized QA-style text, math-related code, and interleaved text-code blocks from web data or code data. By integrating these strategies and validating their effectiveness through extensive ablations, MegaMath delivers 371B tokens with the largest quantity and top quality among existing open math pre-training datasets.
Towards Explainable Multimodal Depression Recognition for Clinical Interviews
Jan 27, 2025



Recently, multimodal depression recognition for clinical interviews (MDRC) has recently attracted considerable attention. Existing MDRC studies mainly focus on improving task performance and have achieved significant development. However, for clinical applications, model transparency is critical, and previous works ignore the interpretability of decision-making processes. To address this issue, we propose an Explainable Multimodal Depression Recognition for Clinical Interviews (EMDRC) task, which aims to provide evidence for depression recognition by summarizing symptoms and uncovering underlying causes. Given an interviewer-participant interaction scenario, the goal of EMDRC is to structured summarize participant's symptoms based on the eight-item Patient Health Questionnaire depression scale (PHQ-8), and predict their depression severity. To tackle the EMDRC task, we construct a new dataset based on an existing MDRC dataset. Moreover, we utilize the PHQ-8 and propose a PHQ-aware multimodal multi-task learning framework, which captures the utterance-level symptom-related semantic information to help generate dialogue-level summary. Experiment results on our annotated dataset demonstrate the superiority of our proposed methods over baseline systems on the EMDRC task.
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
Sep 25, 2024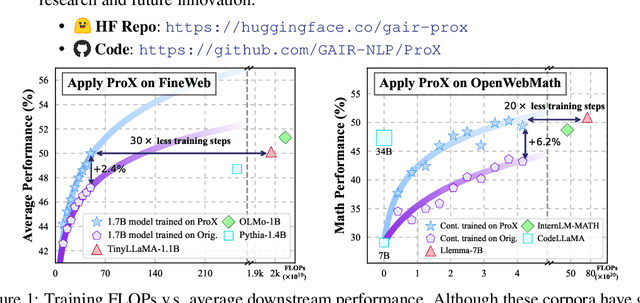

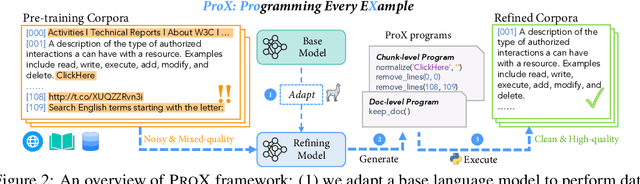
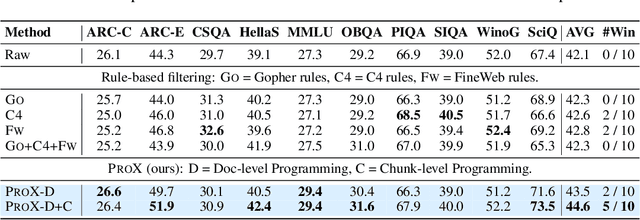
Large language model pre-training has traditionally relied on human experts to craft heuristics for improving the corpora quality, resulting in numerous rules developed to date. However, these rules lack the flexibility to address the unique characteristics of individual example effectively. Meanwhile, applying tailored rules to every example is impractical for human experts. In this paper, we demonstrate that even small language models, with as few as 0.3B parameters, can exhibit substantial data refining capabilities comparable to those of human experts. We introduce Programming Every Example (ProX), a novel framework that treats data refinement as a programming task, enabling models to refine corpora by generating and executing fine-grained operations, such as string normalization, for each individual example at scale. Experimental results show that models pre-trained on ProX-curated data outperform either original data or data filtered by other selection methods by more than 2% across various downstream benchmarks. Its effectiveness spans various model sizes and pre-training corpora, including C4, RedPajama-V2, and FineWeb. Furthermore, ProX exhibits significant potential in domain-specific continual pre-training: without domain specific design, models trained on OpenWebMath refined by ProX outperform human-crafted rule-based methods, improving average accuracy by 7.6% over Mistral-7B, with 14.6% for Llama-2-7B and 20.3% for CodeLlama-7B, all within 10B tokens to be comparable to models like Llemma-7B trained on 200B tokens. Further analysis highlights that ProX significantly saves training FLOPs, offering a promising path for efficient LLM pre-training.We are open-sourcing ProX with >100B corpus, models, and sharing all training and implementation details for reproducible research and future innovation. Code: https://github.com/GAIR-NLP/ProX
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024
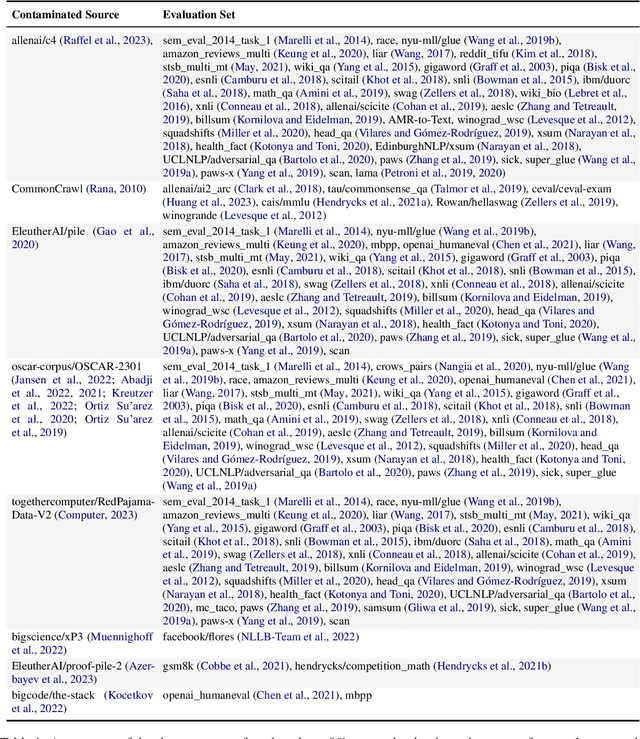
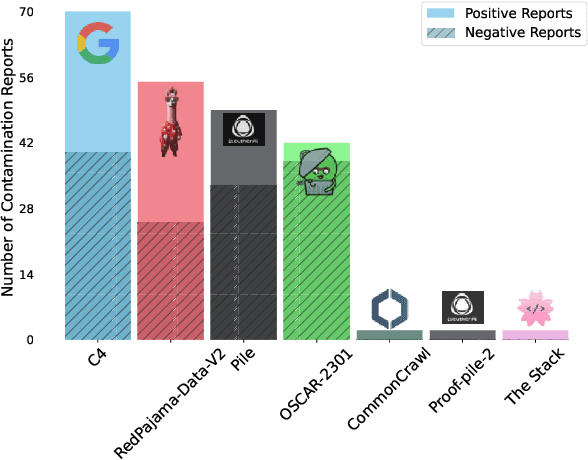
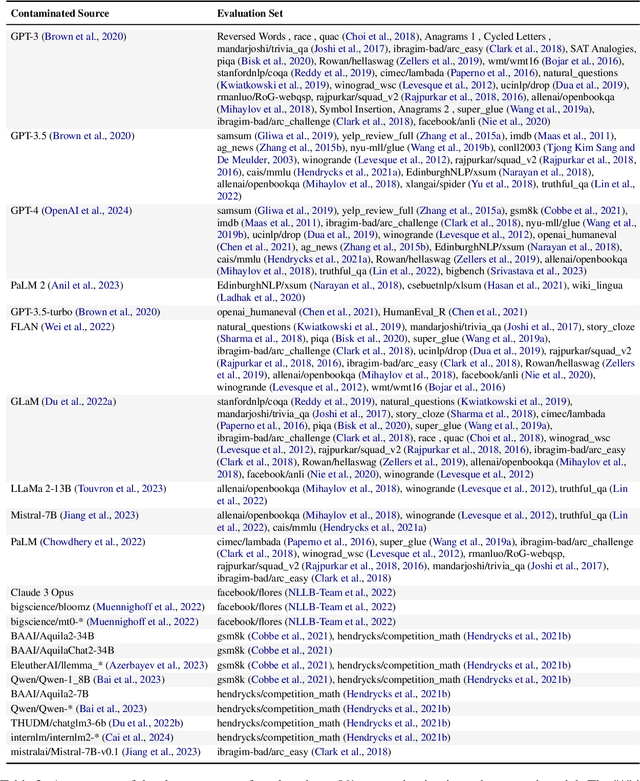
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
OlympicArena Medal Ranks: Who Is the Most Intelligent AI So Far?
Jun 26, 2024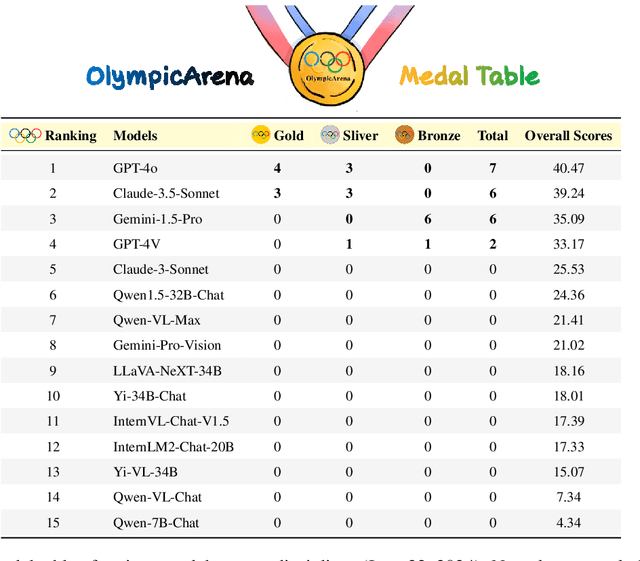
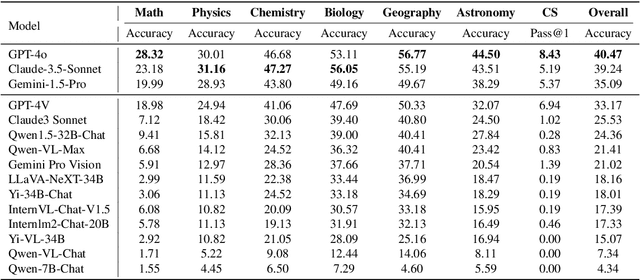
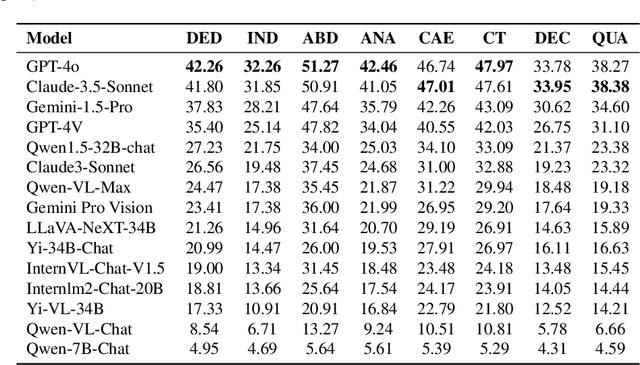
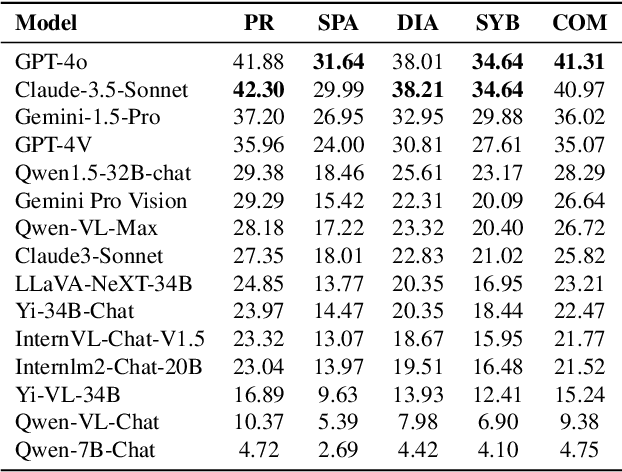
In this report, we pose the following question: Who is the most intelligent AI model to date, as measured by the OlympicArena (an Olympic-level, multi-discipline, multi-modal benchmark for superintelligent AI)? We specifically focus on the most recently released models: Claude-3.5-Sonnet, Gemini-1.5-Pro, and GPT-4o. For the first time, we propose using an Olympic medal Table approach to rank AI models based on their comprehensive performance across various disciplines. Empirical results reveal: (1) Claude-3.5-Sonnet shows highly competitive overall performance over GPT-4o, even surpassing GPT-4o on a few subjects (i.e., Physics, Chemistry, and Biology). (2) Gemini-1.5-Pro and GPT-4V are ranked consecutively just behind GPT-4o and Claude-3.5-Sonnet, but with a clear performance gap between them. (3) The performance of AI models from the open-source community significantly lags behind these proprietary models. (4) The performance of these models on this benchmark has been less than satisfactory, indicating that we still have a long way to go before achieving superintelligence. We remain committed to continuously tracking and evaluating the performance of the latest powerful models on this benchmark (available at https://github.com/GAIR-NLP/OlympicArena).
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent AI
Jun 18, 2024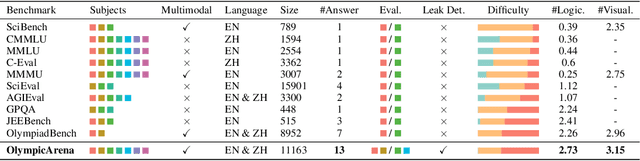
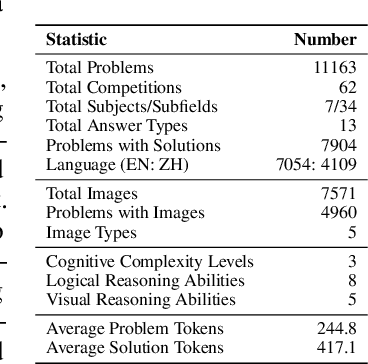
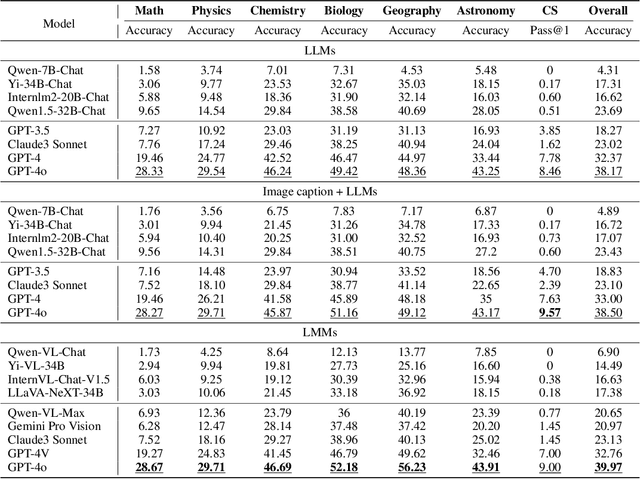
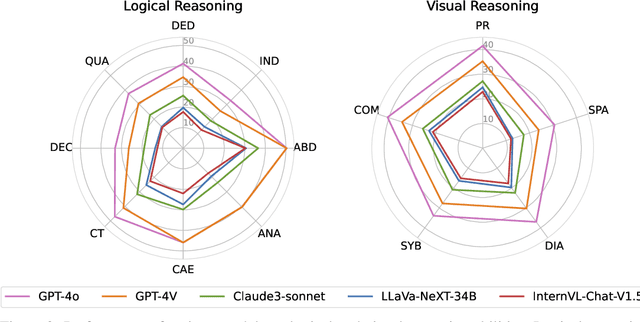
The evolution of Artificial Intelligence (AI) has been significantly accelerated by advancements in Large Language Models (LLMs) and Large Multimodal Models (LMMs), gradually showcasing potential cognitive reasoning abilities in problem-solving and scientific discovery (i.e., AI4Science) once exclusive to human intellect. To comprehensively evaluate current models' performance in cognitive reasoning abilities, we introduce OlympicArena, which includes 11,163 bilingual problems across both text-only and interleaved text-image modalities. These challenges encompass a wide range of disciplines spanning seven fields and 62 international Olympic competitions, rigorously examined for data leakage. We argue that the challenges in Olympic competition problems are ideal for evaluating AI's cognitive reasoning due to their complexity and interdisciplinary nature, which are essential for tackling complex scientific challenges and facilitating discoveries. Beyond evaluating performance across various disciplines using answer-only criteria, we conduct detailed experiments and analyses from multiple perspectives. We delve into the models' cognitive reasoning abilities, their performance across different modalities, and their outcomes in process-level evaluations, which are vital for tasks requiring complex reasoning with lengthy solutions. Our extensive evaluations reveal that even advanced models like GPT-4o only achieve a 39.97% overall accuracy, illustrating current AI limitations in complex reasoning and multimodal integration. Through the OlympicArena, we aim to advance AI towards superintelligence, equipping it to address more complex challenges in science and beyond. We also provide a comprehensive set of resources to support AI research, including a benchmark dataset, an open-source annotation platform, a detailed evaluation tool, and a leaderboard with automatic submission features.
Benchmarking Benchmark Leakage in Large Language Models
Apr 29, 2024



Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the "Benchmark Transparency Card" to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.
Generative AI for Math: Part I -- MathPile: A Billion-Token-Scale Pretraining Corpus for Math
Dec 28, 2023



High-quality, large-scale corpora are the cornerstone of building foundation models. In this work, we introduce \textsc{MathPile}, a diverse and high-quality math-centric corpus comprising about 9.5 billion tokens. Throughout its creation, we adhered to the principle of ``\emph{less is more}'', firmly believing in the supremacy of data quality over quantity, even in the pre-training phase. Our meticulous data collection and processing efforts included a complex suite of preprocessing, prefiltering, language identification, cleaning, filtering, and deduplication, ensuring the high quality of our corpus. Furthermore, we performed data contamination detection on downstream benchmark test sets to eliminate duplicates. We hope our \textsc{MathPile} can help to enhance the mathematical reasoning abilities of language models. We plan to open-source different versions of \mathpile with the scripts used for processing, to facilitate future developments in this field.