 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming Every Example: Lifting Pre-training Data Quality like Experts at Scale
Paper and Code
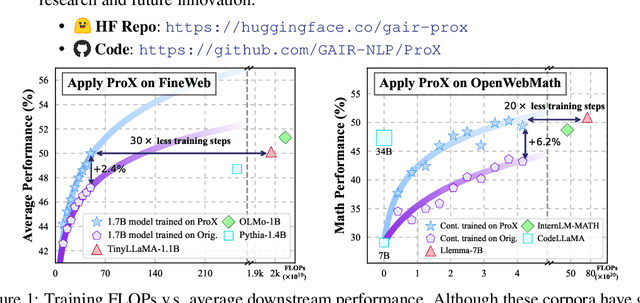

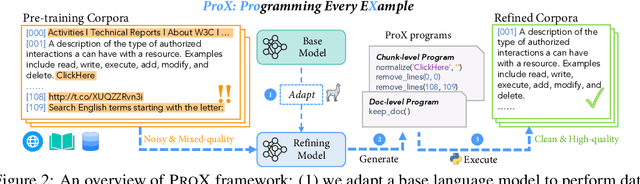
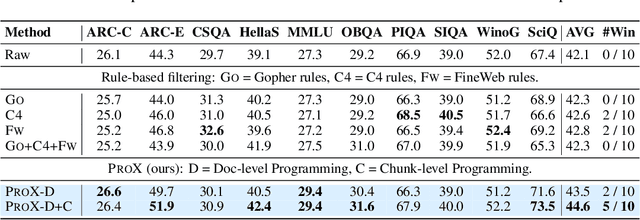
Large language model pre-training has traditionally relied on human experts to craft heuristics for improving the corpora quality, resulting in numerous rules developed to date. However, these rules lack the flexibility to address the unique characteristics of individual example effectively. Meanwhile, applying tailored rules to every example is impractical for human experts. In this paper, we demonstrate that even small language models, with as few as 0.3B parameters, can exhibit substantial data refining capabilities comparable to those of human experts. We introduce Programming Every Example (ProX), a novel framework that treats data refinement as a programming task, enabling models to refine corpora by generating and executing fine-grained operations, such as string normalization, for each individual example at scale. Experimental results show that models pre-trained on ProX-curated data outperform either original data or data filtered by other selection methods by more than 2% across various downstream benchmarks. Its effectiveness spans various model sizes and pre-training corpora, including C4, RedPajama-V2, and FineWeb. Furthermore, ProX exhibits significant potential in domain-specific continual pre-training: without domain specific design, models trained on OpenWebMath refined by ProX outperform human-crafted rule-based methods, improving average accuracy by 7.6% over Mistral-7B, with 14.6% for Llama-2-7B and 20.3% for CodeLlama-7B, all within 10B tokens to be comparable to models like Llemma-7B trained on 200B tokens. Further analysis highlights that ProX significantly saves training FLOPs, offering a promising path for efficient LLM pre-training.We are open-sourcing ProX with >100B corpus, models, and sharing all training and implementation details for reproducible research and future innovation. Code: https://github.com/GAIR-NLP/ProX