 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Guided Metric-Aware Temporal Consistency for Monocular Video Human Mesh Recovery
Feb 04, 2026Monocular video human mesh recovery faces fundamental challenges in maintaining metric consistency and temporal stability due to inherent depth ambiguities and scale uncertainties. While existing methods rely primarily on RGB features and temporal smoothing, they struggle with depth ordering, scale drift, and occlusion-induced instabilities. We propose a comprehensive depth-guided framework that achieves metric-aware temporal consistency through three synergistic components: A Depth-Guided Multi-Scale Fusion module that adaptively integrates geometric priors with RGB features via confidence-aware gating; A Depth-guided Metric-Aware Pose and Shape (D-MAPS) estimator that leverages depth-calibrated bone statistics for scale-consistent initialization; A Motion-Depth Aligned Refinement (MoDAR) module that enforces temporal coherence through cross-modal attention between motion dynamics and geometric cues. Our method achieves superior results on three challenging benchmarks, demonstrating significant improvements in robustness against heavy occlusion and spatial accuracy while maintaining computational efficiency.
Shedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jan 28, 2026Hate Video Detection (HVD) is crucial for online ecosystems. Existing methods assume identical distributions between training (source) and inference (target) data. However, hateful content often evolves into irregular and ambiguous forms to evade censorship, resulting in substantial semantic drift and rendering previously trained models ineffective. Test-Time Adaptation (TTA) offers a solution by adapting models during inference to narrow the cross-domain gap, while conventional TTA methods target mild distribution shifts and struggle with the severe semantic drift in HVD. To tackle these challenges, we propose SCANNER, the first TTA framework tailored for HVD. Motivated by the insight that, despite the evolving nature of hateful manifestations, their underlying cores remain largely invariant (i.e., targeting is still based on characteristics like gender, race, etc), we leverage these stable cores as a bridge to connect the source and target domains. Specifically, SCANNER initially reveals the stable cores from the ambiguous layout in evolving hateful content via a principled centroid-guided alignment mechanism. To alleviate the impact of outlier-like samples that are weakly correlated with centroids during the alignment process, SCANNER enhances the prior by incorporating a sample-level adaptive centroid alignment strategy, promoting more stable adaptation. Furthermore, to mitigate semantic collapse from overly uniform outputs within clusters, SCANNER introduces an intra-cluster diversity regularization that encourages the cluster-wise semantic richness. Experiments show that SCANNER outperforms all baselines, with an average gain of 4.69% in Macro-F1 over the best.
LookBench: A Live and Holistic Open Benchmark for Fashion Image Retrieval
Jan 21, 2026In this paper, we present LookBench (We use the term "look" to reflect retrieval that mirrors how people shop -- finding the exact item, a close substitute, or a visually consistent alternative.), a live, holistic and challenging benchmark for fashion image retrieval in real e-commerce settings. LookBench includes both recent product images sourced from live websites and AI-generated fashion images, reflecting contemporary trends and use cases. Each test sample is time-stamped and we intend to update the benchmark periodically, enabling contamination-aware evaluation aligned with declared training cutoffs. Grounded in our fine-grained attribute taxonomy, LookBench covers single-item and outfit-level retrieval across. Our experiments reveal that LookBench poses a significant challenge on strong baselines, with many models achieving below $60\%$ Recall@1. Our proprietary model achieves the best performance on LookBench, and we release an open-source counterpart that ranks second, with both models attaining state-of-the-art results on legacy Fashion200K evaluations. LookBench is designed to be updated semi-annually with new test samples and progressively harder task variants, providing a durable measure of progress. We publicly release our leaderboard, dataset, evaluation code, and trained models.
Nip Rumors in the Bud: Retrieval-Guided Topic-Level Adaptation for Test-Time Fake News Video Detection
Jan 17, 2026Fake News Video Detection (FNVD) is critical for social stability. Existing methods typically assume consistent news topic distribution between training and test phases, failing to detect fake news videos tied to emerging events and unseen topics. To bridge this gap, we introduce RADAR, the first framework that enables test-time adaptation to unseen news videos. RADAR pioneers a new retrieval-guided adaptation paradigm that leverages stable (source-close) videos from the target domain to guide robust adaptation of semantically related but unstable instances. Specifically, we propose an Entropy Selection-Based Retrieval mechanism that provides videos with stable (low-entropy), relevant references for adaptation. We also introduce a Stable Anchor-Guided Alignment module that explicitly aligns unstable instances' representations to the source domain via distribution-level matching with their stable references, mitigating severe domain discrepancies. Finally, our novel Target-Domain Aware Self-Training paradigm can generate informative pseudo-labels augmented by stable references, capturing varying and imbalanced category distributions in the target domain and enabling RADAR to adapt to the fast-changing label distributions. Extensive experiments demonstrate that RADAR achieves superior performance for test-time FNVD, enabling strong on-the-fly adaptation to unseen fake news video topics.
JavisGPT: A Unified Multi-modal LLM for Sounding-Video Comprehension and Generation
Dec 28, 2025This paper presents JavisGPT, the first unified multimodal large language model (MLLM) for Joint Audio-Video (JAV) comprehension and generation. JavisGPT adopts a concise encoder-LLM-decoder architecture, featuring a SyncFusion module for spatio-temporal audio-video fusion and synchrony-aware learnable queries to bridge a pretrained JAV-DiT generator. This design enables temporally coherent video-audio understanding and generation from multimodal instructions. We design an effective three-stage training pipeline consisting of multimodal pretraining, audio-video fine-tuning, and large-scale instruction-tuning, to progressively build multimodal comprehension and generation from existing vision-language models. To support this, we further construct JavisInst-Omni, a high-quality instruction dataset with over 200K GPT-4o-curated audio-video-text dialogues that span diverse and multi-level comprehension and generation scenarios. Extensive experiments on JAV comprehension and generation benchmarks show that JavisGPT outperforms existing MLLMs, particularly in complex and temporally synchronized settings.
TAMEing Long Contexts in Personalization: Towards Training-Free and State-Aware MLLM Personalized Assistant
Dec 25, 2025Multimodal Large Language Model (MLLM) Personalization is a critical research problem that facilitates personalized dialogues with MLLMs targeting specific entities (known as personalized concepts). However, existing methods and benchmarks focus on the simple, context-agnostic visual identification and textual replacement of the personalized concept (e.g., "A yellow puppy" -> "Your puppy Mochi"), overlooking the ability to support long-context conversations. An ideal personalized MLLM assistant is capable of engaging in long-context dialogues with humans and continually improving its experience quality by learning from past dialogue histories. To bridge this gap, we propose LCMP, the first Long-Context MLLM Personalization evaluation benchmark. LCMP assesses the capability of MLLMs in perceiving variations of personalized concepts and generating contextually appropriate personalized responses that reflect these variations. As a strong baseline for LCMP, we introduce a novel training-free and state-aware framework TAME. TAME endows MLLMs with double memories to manage the temporal and persistent variations of each personalized concept in a differentiated manner. In addition, TAME incorporates a new training-free Retrieve-then-Align Augmented Generation (RA2G) paradigm. RA2G introduces an alignment step to extract the contextually fitted information from the multi-memory retrieved knowledge to the current questions, enabling better interactions for complex real-world user queries. Experiments on LCMP demonstrate that TAME achieves the best performance, showcasing remarkable and evolving interaction experiences in long-context scenarios.
From Shallow Humor to Metaphor: Towards Label-Free Harmful Meme Detection via LMM Agent Self-Improvement
Dec 25, 2025The proliferation of harmful memes on online media poses significant risks to public health and stability. Existing detection methods heavily rely on large-scale labeled data for training, which necessitates substantial manual annotation efforts and limits their adaptability to the continually evolving nature of harmful content. To address these challenges, we present ALARM, the first lAbeL-free hARmful Meme detection framework powered by Large Multimodal Model (LMM) agent self-improvement. The core innovation of ALARM lies in exploiting the expressive information from "shallow" memes to iteratively enhance its ability to tackle more complex and subtle ones. ALARM consists of a novel Confidence-based Explicit Meme Identification mechanism that isolates the explicit memes from the original dataset and assigns them pseudo-labels. Besides, a new Pairwise Learning Guided Agent Self-Improvement paradigm is introduced, where the explicit memes are reorganized into contrastive pairs (positive vs. negative) to refine a learner LMM agent. This agent autonomously derives high-level detection cues from these pairs, which in turn empower the agent itself to handle complex and challenging memes effectively. Experiments on three diverse datasets demonstrate the superior performance and strong adaptability of ALARM to newly evolved memes. Notably, our method even outperforms label-driven methods. These results highlight the potential of label-free frameworks as a scalable and promising solution for adapting to novel forms and topics of harmful memes in dynamic online environments.
Causally-Grounded Dual-Path Attention Intervention for Object Hallucination Mitigation in LVLMs
Nov 12, 2025Object hallucination remains a critical challenge in Large Vision-Language Models (LVLMs), where models generate content inconsistent with visual inputs. Existing language-decoder based mitigation approaches often regulate visual or textual attention independently, overlooking their interaction as two key causal factors. To address this, we propose Owl (Bi-mOdal attention reWeighting for Layer-wise hallucination mitigation), a causally-grounded framework that models hallucination process via a structural causal graph, treating decomposed visual and textual attentions as mediators. We introduce VTACR (Visual-to-Textual Attention Contribution Ratio), a novel metric that quantifies the modality contribution imbalance during decoding. Our analysis reveals that hallucinations frequently occur in low-VTACR scenarios, where textual priors dominate and visual grounding is weakened. To mitigate this, we design a fine-grained attention intervention mechanism that dynamically adjusts token- and layer-wise attention guided by VTACR signals. Finally, we propose a dual-path contrastive decoding strategy: one path emphasizes visually grounded predictions, while the other amplifies hallucinated ones -- letting visual truth shine and hallucination collapse. Experimental results on the POPE and CHAIR benchmarks show that Owl achieves significant hallucination reduction, setting a new SOTA in faithfulness while preserving vision-language understanding capability. Our code is available at https://github.com/CikZ2023/OWL
DORAEMON: A Unified Library for Visual Object Modeling and Representation Learning at Scale
Nov 06, 2025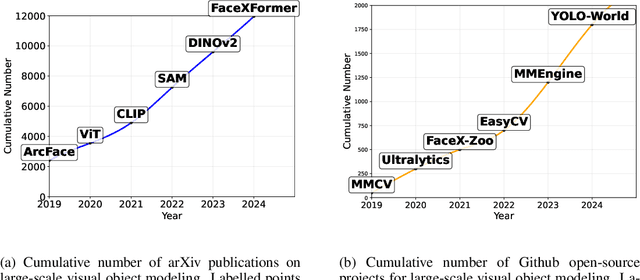
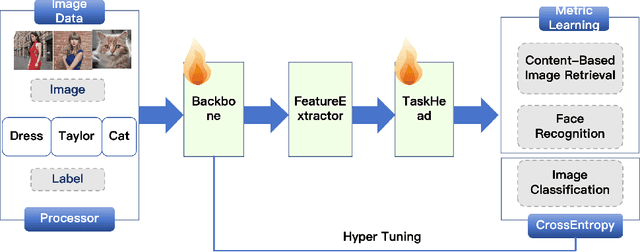
DORAEMON is an open-source PyTorch library that unifies visual object modeling and representation learning across diverse scales. A single YAML-driven workflow covers classification, retrieval and metric learning; more than 1000 pretrained backbones are exposed through a timm-compatible interface, together with modular losses, augmentations and distributed-training utilities. Reproducible recipes match or exceed reference results on ImageNet-1K, MS-Celeb-1M and Stanford online products, while one-command export to ONNX or HuggingFace bridges research and deployment. By consolidating datasets, models, and training techniques into one platform, DORAEMON offers a scalable foundation for rapid experimentation in visual recognition and representation learning, enabling efficient transfer of research advances to real-world applications. The repository is available at https://github.com/wuji3/DORAEMON.
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution
Oct 29, 2025Real-world language agents must handle complex, multi-step workflows across diverse Apps. For instance, an agent may manage emails by coordinating with calendars and file systems, or monitor a production database to detect anomalies and generate reports following an operating manual. However, existing language agent benchmarks often focus on narrow domains or simplified tasks that lack the diversity, realism, and long-horizon complexity required to evaluate agents' real-world performance. To address this gap, we introduce the Tool Decathlon (dubbed as Toolathlon), a benchmark for language agents offering diverse Apps and tools, realistic environment setup, and reliable execution-based evaluation. Toolathlon spans 32 software applications and 604 tools, ranging from everyday platforms such as Google Calendar and Notion to professional ones like WooCommerce, Kubernetes, and BigQuery. Most of the tools are based on a high-quality set of Model Context Protocol (MCP) servers that we may have revised or implemented ourselves. Unlike prior works, which primarily ensure functional realism but offer limited environment state diversity, we provide realistic initial environment states from real software, such as Canvas courses with dozens of students or real financial spreadsheets. This benchmark includes 108 manually sourced or crafted tasks in total, requiring interacting with multiple Apps over around 20 turns on average to complete. Each task is strictly verifiable through dedicated evaluation scripts. Comprehensive evaluation of SOTA models highlights their significant shortcomings: the best-performing model, Claude-4.5-Sonnet, achieves only a 38.6% success rate with 20.2 tool calling turns on average, while the top open-weights model DeepSeek-V3.2-Exp reaches 20.1%. We expect Toolathlon to drive the development of more capable language agents for real-world, long-horizon task execution.