 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding the Facades, Connecting the Domains: Detecting Shifting Multimodal Hate Video with Test-Time Adaptation
Jan 28, 2026Hate Video Detection (HVD) is crucial for online ecosystems. Existing methods assume identical distributions between training (source) and inference (target) data. However, hateful content often evolves into irregular and ambiguous forms to evade censorship, resulting in substantial semantic drift and rendering previously trained models ineffective. Test-Time Adaptation (TTA) offers a solution by adapting models during inference to narrow the cross-domain gap, while conventional TTA methods target mild distribution shifts and struggle with the severe semantic drift in HVD. To tackle these challenges, we propose SCANNER, the first TTA framework tailored for HVD. Motivated by the insight that, despite the evolving nature of hateful manifestations, their underlying cores remain largely invariant (i.e., targeting is still based on characteristics like gender, race, etc), we leverage these stable cores as a bridge to connect the source and target domains. Specifically, SCANNER initially reveals the stable cores from the ambiguous layout in evolving hateful content via a principled centroid-guided alignment mechanism. To alleviate the impact of outlier-like samples that are weakly correlated with centroids during the alignment process, SCANNER enhances the prior by incorporating a sample-level adaptive centroid alignment strategy, promoting more stable adaptation. Furthermore, to mitigate semantic collapse from overly uniform outputs within clusters, SCANNER introduces an intra-cluster diversity regularization that encourages the cluster-wise semantic richness. Experiments show that SCANNER outperforms all baselines, with an average gain of 4.69% in Macro-F1 over the best.
Nip Rumors in the Bud: Retrieval-Guided Topic-Level Adaptation for Test-Time Fake News Video Detection
Jan 17, 2026Fake News Video Detection (FNVD) is critical for social stability. Existing methods typically assume consistent news topic distribution between training and test phases, failing to detect fake news videos tied to emerging events and unseen topics. To bridge this gap, we introduce RADAR, the first framework that enables test-time adaptation to unseen news videos. RADAR pioneers a new retrieval-guided adaptation paradigm that leverages stable (source-close) videos from the target domain to guide robust adaptation of semantically related but unstable instances. Specifically, we propose an Entropy Selection-Based Retrieval mechanism that provides videos with stable (low-entropy), relevant references for adaptation. We also introduce a Stable Anchor-Guided Alignment module that explicitly aligns unstable instances' representations to the source domain via distribution-level matching with their stable references, mitigating severe domain discrepancies. Finally, our novel Target-Domain Aware Self-Training paradigm can generate informative pseudo-labels augmented by stable references, capturing varying and imbalanced category distributions in the target domain and enabling RADAR to adapt to the fast-changing label distributions. Extensive experiments demonstrate that RADAR achieves superior performance for test-time FNVD, enabling strong on-the-fly adaptation to unseen fake news video topics.
From Shallow Humor to Metaphor: Towards Label-Free Harmful Meme Detection via LMM Agent Self-Improvement
Dec 25, 2025The proliferation of harmful memes on online media poses significant risks to public health and stability. Existing detection methods heavily rely on large-scale labeled data for training, which necessitates substantial manual annotation efforts and limits their adaptability to the continually evolving nature of harmful content. To address these challenges, we present ALARM, the first lAbeL-free hARmful Meme detection framework powered by Large Multimodal Model (LMM) agent self-improvement. The core innovation of ALARM lies in exploiting the expressive information from "shallow" memes to iteratively enhance its ability to tackle more complex and subtle ones. ALARM consists of a novel Confidence-based Explicit Meme Identification mechanism that isolates the explicit memes from the original dataset and assigns them pseudo-labels. Besides, a new Pairwise Learning Guided Agent Self-Improvement paradigm is introduced, where the explicit memes are reorganized into contrastive pairs (positive vs. negative) to refine a learner LMM agent. This agent autonomously derives high-level detection cues from these pairs, which in turn empower the agent itself to handle complex and challenging memes effectively. Experiments on three diverse datasets demonstrate the superior performance and strong adaptability of ALARM to newly evolved memes. Notably, our method even outperforms label-driven methods. These results highlight the potential of label-free frameworks as a scalable and promising solution for adapting to novel forms and topics of harmful memes in dynamic online environments.
TAMEing Long Contexts in Personalization: Towards Training-Free and State-Aware MLLM Personalized Assistant
Dec 25, 2025Multimodal Large Language Model (MLLM) Personalization is a critical research problem that facilitates personalized dialogues with MLLMs targeting specific entities (known as personalized concepts). However, existing methods and benchmarks focus on the simple, context-agnostic visual identification and textual replacement of the personalized concept (e.g., "A yellow puppy" -> "Your puppy Mochi"), overlooking the ability to support long-context conversations. An ideal personalized MLLM assistant is capable of engaging in long-context dialogues with humans and continually improving its experience quality by learning from past dialogue histories. To bridge this gap, we propose LCMP, the first Long-Context MLLM Personalization evaluation benchmark. LCMP assesses the capability of MLLMs in perceiving variations of personalized concepts and generating contextually appropriate personalized responses that reflect these variations. As a strong baseline for LCMP, we introduce a novel training-free and state-aware framework TAME. TAME endows MLLMs with double memories to manage the temporal and persistent variations of each personalized concept in a differentiated manner. In addition, TAME incorporates a new training-free Retrieve-then-Align Augmented Generation (RA2G) paradigm. RA2G introduces an alignment step to extract the contextually fitted information from the multi-memory retrieved knowledge to the current questions, enabling better interactions for complex real-world user queries. Experiments on LCMP demonstrate that TAME achieves the best performance, showcasing remarkable and evolving interaction experiences in long-context scenarios.
Compose Yourself: Average-Velocity Flow Matching for One-Step Speech Enhancement
Sep 19, 2025Diffusion and flow matching (FM) models have achieved remarkable progress in speech enhancement (SE), yet their dependence on multi-step generation is computationally expensive and vulnerable to discretization errors. Recent advances in one-step generative modeling, particularly MeanFlow, provide a promising alternative by reformulating dynamics through average velocity fields. In this work, we present COSE, a one-step FM framework tailored for SE. To address the high training overhead of Jacobian-vector product (JVP) computations in MeanFlow, we introduce a velocity composition identity to compute average velocity efficiently, eliminating expensive computation while preserving theoretical consistency and achieving competitive enhancement quality. Extensive experiments on standard benchmarks show that COSE delivers up to 5x faster sampling and reduces training cost by 40%, all without compromising speech quality. Code is available at https://github.com/ICDM-UESTC/COSE.
Retrieval-Augmented Dynamic Prompt Tuning for Incomplete Multimodal Learning
Jan 02, 2025



Multimodal learning with incomplete modality is practical and challenging. Recently, researchers have focused on enhancing the robustness of pre-trained MultiModal Transformers (MMTs) under missing modality conditions by applying learnable prompts. However, these prompt-based methods face several limitations: (1) incomplete modalities provide restricted modal cues for task-specific inference, (2) dummy imputation for missing content causes information loss and introduces noise, and (3) static prompts are instance-agnostic, offering limited knowledge for instances with various missing conditions. To address these issues, we propose RAGPT, a novel Retrieval-AuGmented dynamic Prompt Tuning framework. RAGPT comprises three modules: (I) the multi-channel retriever, which identifies similar instances through a within-modality retrieval strategy, (II) the missing modality generator, which recovers missing information using retrieved contexts, and (III) the context-aware prompter, which captures contextual knowledge from relevant instances and generates dynamic prompts to largely enhance the MMT's robustness. Extensive experiments conducted on three real-world datasets show that RAGPT consistently outperforms all competitive baselines in handling incomplete modality problems. The code of our work and prompt-based baselines is available at https://github.com/Jian-Lang/RAGPT.
An optical biomimetic eyes with interested object imaging
Aug 08, 2021
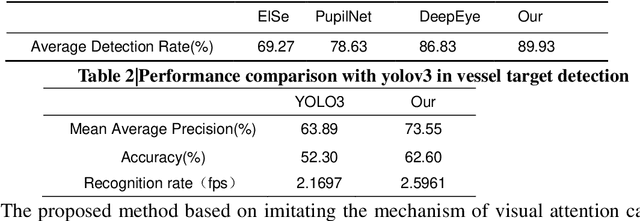
We presented an optical system to perform imaging interested objects in complex scenes, like the creature easy see the interested prey in the hunt for complex environments. It utilized Deep-learning network to learn the interested objects's vision features and designed the corresponding "imaging matrices", furthermore the learned matrixes act as the measurement matrix to complete compressive imaging with a single-pixel camera, finally we can using the compressed image data to only image the interested objects without the rest objects and backgrounds of the scenes with the previous Deep-learning network. Our results demonstrate that no matter interested object is single feature or rich details, the interference can be successfully filtered out and this idea can be applied in some common applications that effectively improve the performance. This bio-inspired optical system can act as the creature eye to achieve success on interested-based object imaging, object detection, object recognition and object tracking, etc.
A Heterogeneous Dynamical Graph Neural Networks Approach to Quantify Scientific Impact
Mar 26, 2020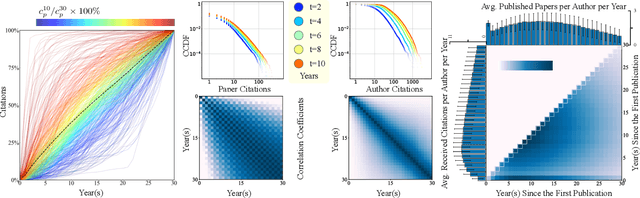
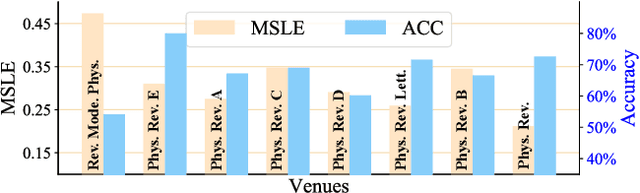
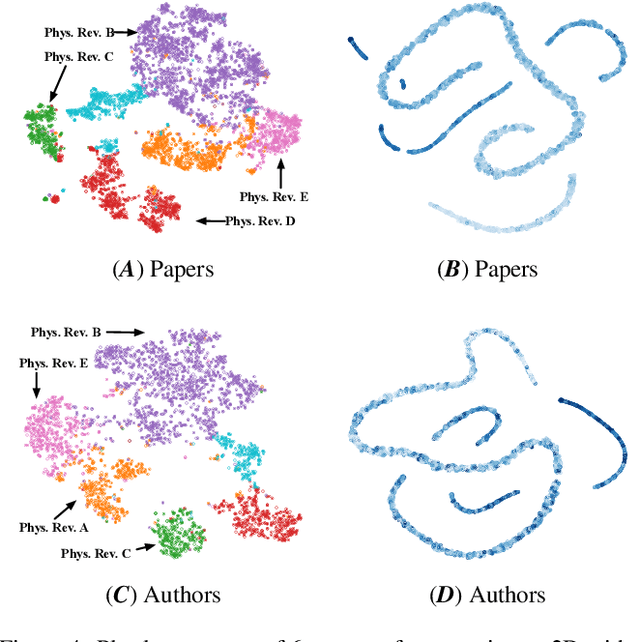
Quantifying and predicting the long-term impact of scientific writings or individual scholars has important implications for many policy decisions, such as funding proposal evaluation and identifying emerging research fields. In this work, we propose an approach based on Heterogeneous Dynamical Graph Neural Network (HDGNN) to explicitly model and predict the cumulative impact of papers and authors. HDGNN extends heterogeneous GNNs by incorporating temporally evolving characteristics and capturing both structural properties of attributed graph and the growing sequence of citation behavior. HDGNN is significantly different from previous models in its capability of modeling the node impact in a dynamic manner while taking into account the complex relations among nodes. Experiments conducted on a real citation dataset demonstrate its superior performance of predicting the impact of both papers and authors.
Continual Graph Learning
Mar 22, 2020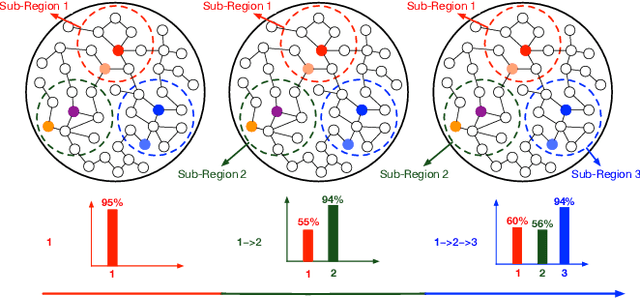
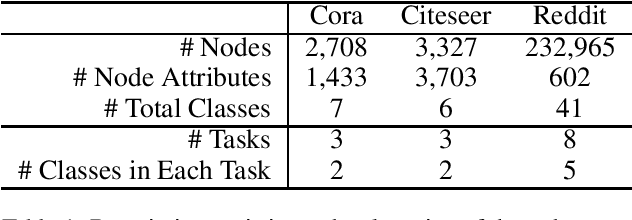
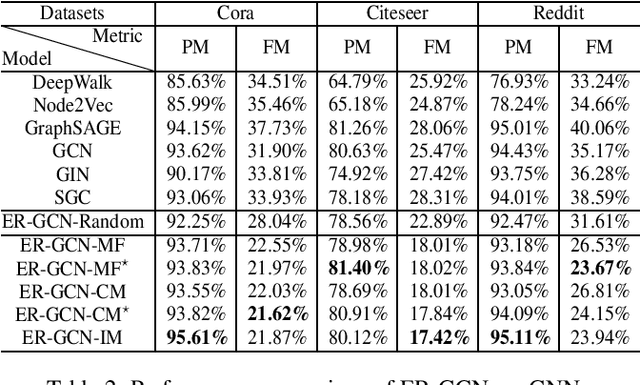
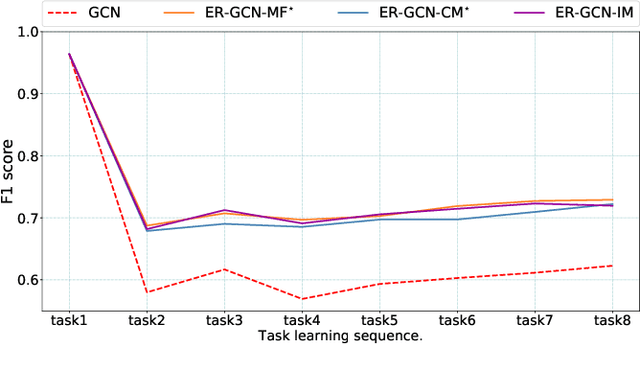
Graph Neural Networks (GNNs) have recently received significant research attention due to their prominent performance on a variety of graph-related learning tasks. Most of the existing works focus on either static or dynamic graph settings, addressing a particular task, e.g., node/graph classification, link prediction. In this work, we investigate the question: can GNNs be applied to continuously learning a sequence of tasks? Towards that, we explore the Continual Graph Learning (CGL) paradigm and we present the Experience Replay based framework ER-GNN for CGL to address the catastrophic forgetting problem in existing GNNs. ER-GNN stores knowledge from previous tasks as experiences and replays them when learning new tasks to mitigate the forgetting issue. We propose three experience node selection strategies: mean of features, coverage maximization and influence maximization, to guide the process of selecting experience nodes. Extensive experiments on three benchmark datasets demonstrate the effectiveness of ER-GNN and shed light on the incremental (non-Euclidean) graph structure learning.
Meta-GNN: On Few-shot Node Classification in Graph Meta-learning
May 23, 2019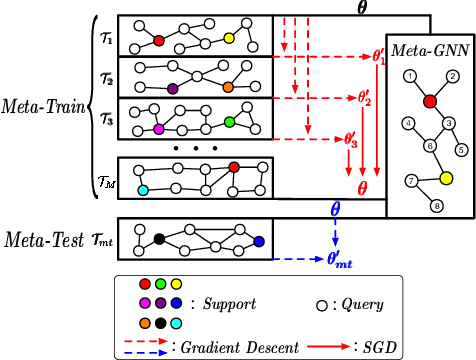
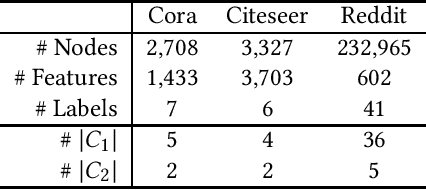
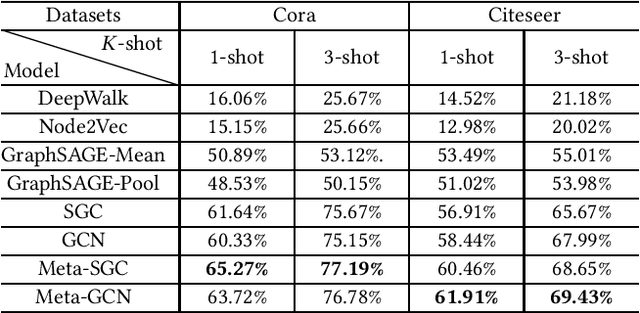
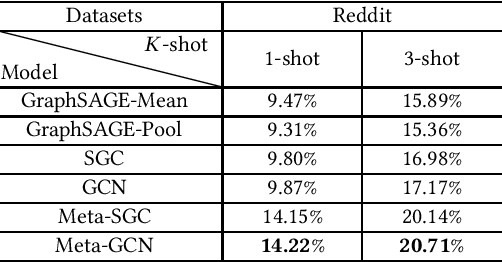
Meta-learning has received a tremendous recent attention as a possible approach for mimicking human intelligence, i.e., acquiring new knowledge and skills with little or even no demonstration. Most of the existing meta-learning methods are proposed to tackle few-shot learning problems such as image and text, in rather Euclidean domain. However, there are very few works applying meta-learning to non-Euclidean domains, and the recently proposed graph neural networks (GNNs) models do not perform effectively on graph few-shot learning problems. Towards this, we propose a novel graph meta-learning framework -- Meta-GNN -- to tackle the few-shot node classification problem in graph meta-learning settings. It obtains the prior knowledge of classifiers by training on many similar few-shot learning tasks and then classifies the nodes from new classes with only few labeled samples. Additionally, Meta-GNN is a general model that can be straightforwardly incorporated into any existing state-of-the-art GNN. Our experiments conducted on three benchmark datasets demonstrate that our proposed approach not only improves the node classification performance by a large margin on few-shot learning problems in meta-learning paradigm, but also learns a more general and flexible model for task adaption.